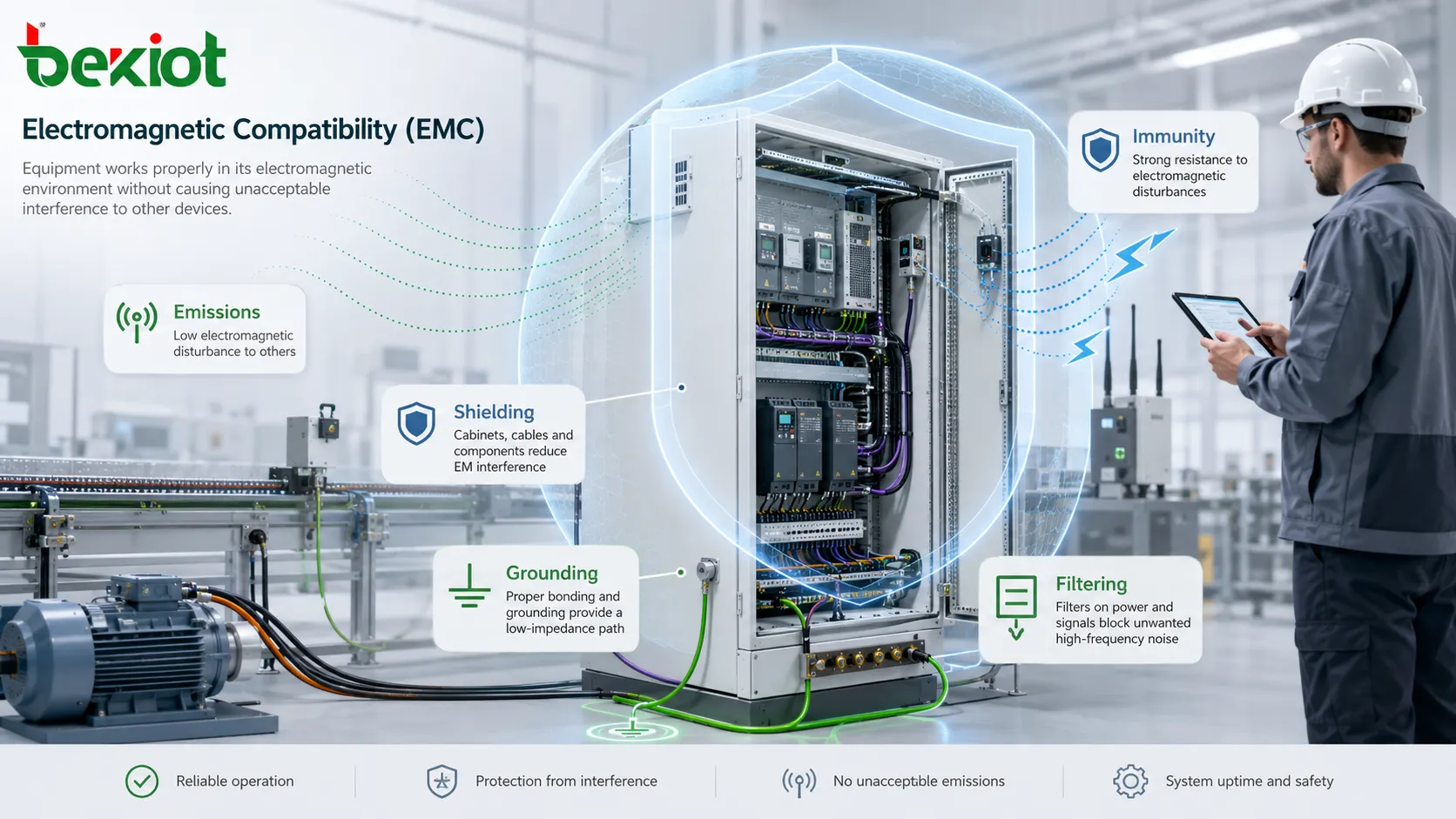
La redundancia se refiere a la duplicación deliberada de componentes críticos, funciones, enlaces o recursos en un sistema para que el servicio pueda continuar incluso si una parte falla. En términos prácticos de ingeniería y operación, la redundancia no es desperdicio. Es una estrategia de confiabilidad. El objetivo es reducir los puntos únicos de fallo y mejorar la capacidad de un sistema para permanecer disponible durante fallos, eventos de mantenimiento, condiciones de sobrecarga o interrupciones inesperadas.
El concepto aparece en muchos campos técnicos y operativos. En redes, la redundancia puede significar enlaces ascendentes duales, conmutadores de respaldo o múltiples rutas de transmisión. En telefonía y comunicaciones unificadas, puede involucrar servidores SIP redundantes, plataformas IP PBX en espera, pasarelas duplicadas o lógica de enrutamiento de llamadas de respaldo. En sistemas de energía, puede incluir fuentes de alimentación duales, respaldo de batería y alimentaciones eléctricas redundantes. En entornos industriales, la redundancia a menudo se extiende aún más para incluir controladores duplicados, rutas de comunicación, dispositivos de campo y servidores de conmutación por fallo que admiten operaciones de alta disponibilidad.
Aunque la redundancia a menudo se discute en el contexto de infraestructura y sistemas críticos, la idea subyacente es simple. Un sistema se vuelve frágil cuando una sola falla puede detener todo el servicio. La redundancia reduce esa fragilidad al garantizar que ya esté preparada una ruta, dispositivo o instancia de servicio alternativa para hacerse cargo. Por esta razón, la redundancia es uno de los principios de diseño más importantes en redes de comunicación, sistemas de seguridad, plataformas de automatización, sistemas de seguridad pública y arquitectura de TI empresarial.

La redundancia mejora la continuidad del servicio al agregar recursos de respaldo y reducir los puntos únicos de fallo.
Lo que Significa la Redundancia en la Práctica
Más que una Simple Copia de Seguridad
Muchas personas usan las palabras redundancia y copia de seguridad como si significaran lo mismo, pero en el diseño de sistemas reales están relacionadas más no son idénticas. Una copia de seguridad es a menudo una copia de reserva o un recurso en espera que puede usarse después de una falla, mientras que la redundancia generalmente implica que ya hay múltiples recursos integrados en la arquitectura del sistema en vivo. En otras palabras, la redundancia no se trata solo de la recuperación después de que algo sale mal. Se trata de diseñar el sistema para que pueda continuar operando con una interrupción mínima cuando algo sale mal.
Por ejemplo, un archivo de configuración de respaldo almacenado fuera de línea es útil, pero no crea continuidad del servicio en tiempo real. Por el contrario, un par de servidores redundantes, una ruta de red secundaria o una segunda fuente de alimentación pueden respaldar la continuidad mientras el sistema aún está funcionando. Esta distinción es especialmente importante en entornos donde las interrupciones del servicio son costosas o peligrosas, como hospitales, salas de control, centros de transporte, plantas industriales, sistemas de comunicación de emergencia y grandes redes empresariales.
Es por eso que la redundancia a menudo se trata como parte de la ingeniería de disponibilidad en lugar de solo como parte de la recuperación ante desastres. Aborda la cuestión de cómo se comporta el sistema durante una falla, no solo cómo se puede reconstruir después de que la falla ya haya causado tiempo de inactividad.
Reducción de Puntos Únicos de Fallo
La razón más común para usar redundancia es eliminar o reducir los puntos únicos de fallo. Un punto único de fallo es cualquier componente cuya falla puede derribar el sistema más grande. Esto puede ser un conmutador de red, un módulo de alimentación, un servidor, un dispositivo de almacenamiento, una pasarela, un controlador o incluso una ruta de cable. Si ese elemento falla y no existe una alternativa, el servicio se detiene.
La redundancia cambia ese modelo de riesgo. En lugar de depender de un elemento crítico, el sistema se diseña para que otro componente, ruta o instancia pueda continuar la tarea. En algunos diseños, el recurso de repuesto permanece inactivo hasta que se necesita. En otros, ambos recursos están activos y comparten la carga. De cualquier manera, el objetivo es mantener el servicio disponible incluso cuando ocurre una falla.
Esta es la razón por la cual la redundancia es tan valiosa en los sistemas de comunicación modernos. Las funciones de voz, datos, control y alarmas dependen cada vez más de una infraestructura digital interconectada. Cuando una falla afecta a múltiples servicios a la vez, el impacto operativo puede ser mucho mayor que en sistemas aislados más antiguos. La redundancia ayuda a contener ese riesgo.
La redundancia es la decisión de ingeniería de asumir que ocurrirán fallas y de diseñar el sistema para que esas fallas no se conviertan en un colapso del servicio.
Cómo Funciona la Redundancia
Modelos Activo-En Espera y Activo-Activo
La redundancia se puede implementar de varias maneras, pero dos modelos comunes son activo-en espera y activo-activo. En un diseño activo-en espera, el recurso primario maneja el servicio en condiciones normales mientras que el recurso secundario espera en reserva. Si el primario falla, el secundario toma el control. Este enfoque es común en servidores, controladores, pasarelas, módulos de alimentación y nodos de comunicación donde se desea un comportamiento de conmutación por fallo simplificado.
En un modelo activo-activo, múltiples recursos están activos al mismo tiempo. Pueden compartir el tráfico, procesar solicitudes en paralelo o proporcionar continuidad mutua si una instancia falla. Este diseño puede mejorar tanto la disponibilidad como la capacidad, pero a menudo requiere una sincronización más cuidadosa, manejo de estado y gestión del tráfico. En redes y servicios de datos, los enfoques activo-activo son especialmente comunes cuando tanto el reparto de carga como la capacidad de respuesta continua son importantes.
La mejor elección depende de la aplicación. Activo-en espera suele ser más simple de controlar y verificar, mientras que activo-activo puede ofrecer un rendimiento más fuerte y una continuidad más fluida en sistemas más grandes. Ambos enfoques son formas de redundancia, pero difieren en el comportamiento operativo y la complejidad del diseño.
Lógica de Conmutación por Fallo, Transferencia y Recuperación
La redundancia se vuelve útil solo cuando el sistema sabe cómo reaccionar ante las fallas. Aquí es donde importa la lógica de conmutación por fallo. Un diseño redundante generalmente incluye monitoreo de salud, señales de latido, mecanismos de sincronización, definiciones de roles y reglas de transferencia. Cuando el sistema detecta que un recurso ya no funciona correctamente, inicia una transición para que el recurso alternativo pueda continuar proporcionando el servicio.
Esa transición puede ser automática o manual dependiendo del entorno. En comunicaciones críticas, a menudo se prefiere la conmutación por fallo automática porque la demora puede interrumpir el tráfico de voz o las operaciones de respuesta. En algunos entornos industriales o regulados, se puede utilizar una transferencia supervisada o semimanual para mantener el control sobre el estado del sistema y la seguridad del proceso. En cualquier caso, la efectividad de la redundancia depende no solo de tener hardware o software adicional, sino de gestionar la transición correctamente.
La recuperación también importa después de la conmutación por fallo. Una vez que se repara el componente fallido, el sistema debe decidir si devolver el servicio al recurso original inmediatamente, esperar la aprobación del operador o mantener el control del respaldo hasta una ventana de mantenimiento programada. Estas opciones de política afectan la estabilidad y deben planificarse en lugar de improvisarse.
Sincronización y Conciencia del Estado
En muchos sistemas redundantes, el recurso secundario debe estar listo para hacerse cargo sin perder el contexto crítico. Eso significa que los datos de configuración, la información de sesión, el estado de la llamada, las tablas de enrutamiento, los datos del usuario, las alarmas o el estado de la aplicación pueden necesitar sincronizarse entre los componentes primario y secundario. Sin sincronización, la conmutación por fallo puede preservar la disponibilidad de la infraestructura pero aun así interrumpir la experiencia del servicio de manera importante.
Esto es especialmente importante en sistemas de voz y comunicación. Una plataforma SIP redundante, un servidor de despacho o una IP PBX pueden necesitar perfiles de usuario sincronizados, datos de extensión, políticas de enrutamiento y lógica de registro. En entornos de almacenamiento y virtualización, el estado sincronizado ayuda a prevenir la inconsistencia de datos. En sistemas de control industrial, la lógica sincronizada es esencial para mantener el comportamiento de automatización predecible durante el cambio.
Debido a esto, la redundancia no se trata solo de duplicación física. También se trata de continuidad de la información. Un servidor en espera que existe pero no está sincronizado aún puede dejar a la organización vulnerable a la interrupción del servicio cuando se hace cargo.
Características Clave de la Redundancia
Soporte de Alta Disponibilidad
La característica más reconocida de la redundancia es la mejora de la disponibilidad. Un diseño redundante ayuda a que los servicios permanezcan accesibles incluso cuando ocurren problemas de hardware, software o conectividad. En lugar de tratar el tiempo de actividad como una cuestión de suerte, la redundancia hace que la disponibilidad sea parte de la arquitectura misma. Esto es especialmente valioso en sistemas que admiten comunicación en vivo, coordinación de operaciones, alarmas, seguridad o interacción orientada al cliente.
En implementaciones reales, la alta disponibilidad no se trata solo de si el sistema está técnicamente en línea. También se trata de si los usuarios pueden continuar su trabajo con una interrupción mínima. Un sistema de comunicación que pierde todos los registros activos o se vuelve inalcanzable durante una sola falla de servidor puede no cumplir con las expectativas operativas incluso si puede reiniciarse rápidamente. La redundancia reduce esa exposición al preparar rutas de continuidad con anticipación.
Esta es la razón por la cual el diseño de alta disponibilidad a menudo es inseparable de la planificación de la redundancia. Donde el tiempo de actividad importa, la redundancia suele ser una de las principales herramientas utilizadas para lograrlo.
Tolerancia a Fallos y Continuidad del Servicio
La redundancia está estrechamente asociada con la tolerancia a fallos, pero las dos ideas no son exactamente iguales. La tolerancia a fallos se refiere a la capacidad del sistema para continuar funcionando correctamente a pesar de los fallos. La redundancia es uno de los mecanismos que ayuda a lograr ese resultado. Al duplicar los recursos críticos, el sistema gana tolerancia a fallos en áreas que de otro modo causarían una interrupción inmediata del servicio.
En sistemas de comunicación e infraestructura, esto significa que los usuarios a menudo pueden continuar haciendo llamadas, accediendo a servicios o intercambiando datos incluso si se pierde un nodo, enlace o fuente de alimentación. En entornos industriales, puede significar que las operaciones de monitoreo, difusión, intercomunicación o control continúan sin un punto ciego peligroso. En TI empresarial, puede permitir que las aplicaciones y las sesiones de usuario permanezcan disponibles mientras los fallos se aíslan y reparan.
La continuidad del servicio es el resultado práctico que les importa a los usuarios. Puede que no vean directamente la lógica de redundancia, pero experimentan el sistema como confiable y resistente bajo estrés.
Mantenimiento Flexible y Resiliencia Operativa
Otra característica importante de la redundancia es que admite el mantenimiento sin requerir una interrupción completa del servicio. Si una plataforma tiene servidores redundantes, conmutadores, enlaces o fuentes de alimentación, los técnicos pueden dar servicio a una parte mientras la otra continúa con la carga de trabajo. Esto mejora la capacidad de gestión del ciclo de vida y reduce el costo de las ventanas de mantenimiento.
La redundancia también respalda la resiliencia operativa durante la degradación parcial. No todos los problemas son un fallo total. A veces el problema es la sobrecarga, la inestabilidad intermitente, las actualizaciones planificadas o la interrupción ambiental temporal. Un diseño redundante proporciona opciones para redirigir, aislar y estabilizar los servicios antes de que un pequeño problema se convierta en una interrupción mayor.
Esa resiliencia se vuelve cada vez más importante a medida que las organizaciones dependen de la comunicación digital siempre activa. El sistema debe sobrevivir no solo a desastres raros, sino también a fallos rutinarios y realidades de mantenimiento.

La redundancia respalda la alta disponibilidad, la tolerancia a fallos y un mantenimiento más flexible en sistemas de comunicación e infraestructura.
Tipos Comunes de Redundancia
Redundancia de Red
La redundancia de red es una de las formas más comunes. Puede incluir múltiples enlaces ascendentes, conmutadores redundantes, enrutadores duales, topologías en anillo, enlaces de malla o rutas WAN alternativas. El propósito es garantizar que el tráfico aún pueda moverse si una conexión o dispositivo falla. En redes empresariales e industriales, esto es esencial porque una interrupción de la red puede afectar la voz, el video, las alarmas, el tráfico de control y las aplicaciones comerciales al mismo tiempo.
En proyectos reales, la redundancia de red a menudo se combina con protocolos de abarcamiento, conmutación por fallo de enrutamiento, mecanismos de recuperación rápida, diseño de VLAN y planificación de QoS. La red no solo debe tener enlaces adicionales, sino también saber cómo usarlos sin causar bucles, inestabilidad o un comportamiento de conmutación impredecible. Esto es especialmente importante para el tráfico VoIP y SIP, donde el retraso y la pérdida pueden degradar el servicio rápidamente.
A medida que los sistemas de comunicación se expanden a través de fábricas, campus, sitios de transporte y entornos de servicios públicos, la redundancia de red se convierte en un requisito fundamental en lugar de una mejora opcional.
Redundancia de Servidores y Aplicaciones
La redundancia de servidores se utiliza cuando las aplicaciones, la lógica de control o los servicios de comunicación deben permanecer disponibles a pesar de fallos de hardware o software. Esto puede involucrar servidores en clúster, entornos de conmutación por fallo virtualizados, nodos de aplicación reflejados o instancias de servicio en espera. En plataformas de comunicación SIP e IP, la redundancia puede cubrir servidores de control de llamadas, sistemas de aprovisionamiento, plataformas de correo de voz, servidores de despacho y aplicaciones de gestión.
La redundancia de aplicaciones es especialmente importante cuando los usuarios dependen de servicios centrales para el registro, la autenticación, el enrutamiento o la coordinación. Si falla un solo servidor de comunicaciones, cientos o miles de terminales pueden verse afectados. La redundancia reduce esa concentración de riesgo al garantizar que el servicio pueda continuar desde otro nodo.
La redundancia exitosa de servidores requiere más que instalar una segunda máquina. También depende de la sincronización, las comprobaciones de estado, el manejo de bases de datos y una secuencia de conmutación por fallo claramente definida que se ajuste a la aplicación.
Redundancia de Energía
Muchas interrupciones comienzan no con una falla de software sino con una interrupción de energía. La redundancia de energía aborda este riesgo al proporcionar más de una fuente de energía o ruta de suministro. Los ejemplos comunes incluyen fuentes de alimentación duales, alimentaciones eléctricas independientes, sistemas UPS, respaldo de batería, integración de generadores y duplicación de módulos de alimentación dentro de equipos de red o comunicaciones.
En los sistemas de comunicación, la redundancia de energía es crítica porque incluso una arquitectura de red y servidores bien diseñada deja de estar disponible si se pierde la energía en un nodo central o terminal de campo. Esto es especialmente importante en telefonía de emergencia, sistemas de megafonía, comunicación de transporte, intercomunicación industrial y entornos de sala de control donde el servicio puede ser más necesario durante el estrés de la infraestructura.
Por esa razón, la redundancia de energía a menudo se trata como inseparable de la redundancia de comunicaciones. Tanto la ruta de red como la ruta de energía deben ser resistentes; de lo contrario, no se puede alcanzar el objetivo de disponibilidad general.
Redundancia de Almacenamiento y Datos
Los datos también necesitan protección. La redundancia de almacenamiento puede implicar discos reflejados, configuraciones RAID, bases de datos replicadas, nodos de almacenamiento sincronizados y copias de datos remotas. El propósito es evitar la pérdida de información o la interrupción del servicio cuando falla un dispositivo de almacenamiento. En sistemas empresariales, esto respalda la continuidad de la aplicación. En plataformas de comunicación, puede proteger registros de usuarios, bitácoras, correo de voz, datos de configuración, reglas de enrutamiento e historial de eventos.
Sin embargo, la redundancia de almacenamiento no debe confundirse con la protección completa de datos. El reflejado protege contra algunos tipos de fallos de hardware, pero no resuelve automáticamente la corrupción, la eliminación accidental o los errores a nivel de aplicación. Por esta razón, las organizaciones generalmente combinan la redundancia con la planificación de copias de seguridad y recuperación en lugar de tratar una como sustituto de la otra.
Esto ilustra un punto importante: la redundancia mejora la continuidad, pero funciona mejor cuando se combina con una estrategia de resiliencia más amplia.
Aplicaciones de la Redundancia
Sistemas de Comunicación y Telefonía IP
La redundancia se usa ampliamente en plataformas de comunicación porque se espera que los servicios de voz estén continuamente disponibles. En entornos de telefonía SIP e IP, la redundancia puede involucrar servidores SIP duplicados, nodos IP PBX de respaldo, elementos de borde de sesión secundarios, pasarelas redundantes y conectividad WAN alternativa. Estos diseños ayudan a garantizar que las llamadas aún puedan procesarse incluso si falla un nodo o una ruta.
En términos prácticos, esto es importante para oficinas, campus, hospitales, sitios industriales, instalaciones de transporte y centros de coordinación de emergencias. Un sistema telefónico puede ser central para las operaciones diarias, la interacción con el cliente y la respuesta a incidentes. Si el servidor principal o la ruta de red falla sin redundancia, el impacto en la comunicación puede ser inmediato y generalizado.
Esta es la razón por la cual la telefonía empresarial moderna trata cada vez más la redundancia como una característica arquitectónica esperada en lugar de un extra premium. A medida que los sistemas se integran más con la megafonía, la intercomunicación, las alarmas, el video y el despacho, el valor de la continuidad de la comunicación se vuelve aún mayor.
Control Industrial e Infraestructura Crítica
Los entornos industriales y de infraestructura crítica dependen en gran medida de la redundancia porque la interrupción del servicio puede afectar no solo la productividad sino también la seguridad. Las plantas de energía, refinerías, túneles, sistemas de metro, instalaciones de agua, corredores de servicios públicos y sitios de fabricación a menudo utilizan enlaces de comunicación redundantes, servidores de control, rutas de red y diseños de energía para reducir el riesgo operativo.
En tales entornos, la redundancia puede respaldar la comunicación SCADA, la telefonía industrial, los sistemas PAGA, la difusión de alarmas, las consolas de despacho, la intercomunicación de campo y las plataformas de monitoreo central. El objetivo es preservar la visibilidad y el control incluso durante fallos de equipo o estrés de la infraestructura. Esto es especialmente importante donde los operadores necesitan conciencia continua del estado de la planta y la capacidad de comunicarse con el personal de campo.
Debido a que el costo del fallo puede ser alto, la redundancia en estos sectores generalmente se planifica de manera más deliberada y se prueba más rigurosamente que en entornos de oficina comunes.
Centros de Datos, TI Empresarial y Servicios en la Nube
En entornos de TI empresarial y centros de datos, la redundancia respalda la disponibilidad de las aplicaciones, la continuidad del servicio y la resiliencia empresarial. Las organizaciones utilizan nodos de cómputo redundantes, tejidos de red, sistemas de almacenamiento, rutas de refrigeración e infraestructura de energía para mantener accesibles los servicios digitales. Incluso cuando están involucrados servicios en la nube, la redundancia sigue siendo importante porque la arquitectura aún depende de la conectividad resistente, el diseño de la plataforma y la distribución del servicio.
Para los usuarios, esto puede aparecer como un sitio web que permanece en línea, una plataforma de comunicación que sigue funcionando o un servicio de colaboración remota que sobrevive a fallos localizados. Detrás de esa experiencia a menudo hay un modelo de redundancia cuidadosamente estratificado que distribuye el riesgo a través de las capas de hardware, software y conectividad.
A medida que las operaciones comerciales se vuelven más digitales, la redundancia se vuelve menos un tema especializado y más un requisito básico para la prestación de servicios confiables.
Operaciones de Seguridad, Protección y Emergencia
Los sistemas de seguridad y emergencia son otra área de aplicación importante. Las infraestructuras de vigilancia por video, los servidores de control de acceso, las plataformas de llamadas de emergencia, los sistemas de megafonía, las soluciones de despacho y las redes de distribución de alarmas a menudo requieren redundancia porque deben permanecer disponibles durante condiciones anormales. En muchos casos, estos son los momentos exactos en que más se necesitan los sistemas.
Por ejemplo, una red de puntos de llamada de emergencia puede requerir enrutamiento de comunicación redundante y energía de respaldo. Una sala de control puede necesitar servidores duplicados y rutas de voz alternativas. Un sistema de radiodifusión de seguridad pública puede requerir amplificadores redundantes, conmutadores de red o nodos de gestión central. Sin redundancia, el sistema puede fallar precisamente cuando su función se vuelve crítica.
Esta es la razón por la cual la redundancia a menudo se trata como un principio de diseño central en la arquitectura de comunicación y monitoreo relacionada con la seguridad.

La redundancia se usa ampliamente en telefonía, sistemas industriales, TI empresarial y entornos de comunicación críticos para la seguridad.
El valor de la redundancia se vuelve más visible cuando ocurre lo inesperado y el sistema sigue funcionando de todos modos.
Consideraciones de Diseño para Sistemas Redundantes
Complejidad, Costo y Pruebas
La redundancia agrega resiliencia, pero también agrega complejidad. Más dispositivos, más enlaces, más lógica y más requisitos de sincronización pueden aumentar la carga de diseño. Si se implementa mal, un sistema redundante puede volverse difícil de administrar o puede fallar de manera impredecible durante la transferencia. Por esta razón, la redundancia debe planificarse con una arquitectura clara, un alcance controlado y procedimientos operativos realistas.
El costo es otro factor. Los componentes redundantes aumentan los requisitos de hardware, licencias, integración y mantenimiento. Sin embargo, la decisión debe basarse en el riesgo y la importancia del servicio, no solo en el costo del hardware. En muchos entornos, el costo del tiempo de inactividad es mucho mayor que el costo de construir la redundancia correctamente.
Las pruebas son esenciales. Un diseño redundante que nunca se prueba puede crear una falsa confianza. Las organizaciones deben verificar el comportamiento de conmutación por fallo, los tiempos, la preservación del estado, el manejo de alarmas y los procedimientos de recuperación en condiciones controladas.
Hacer Coincidir la Redundancia con el Riesgo Comercial Real
No todos los componentes necesitan el mismo nivel de redundancia. El diseño efectivo comienza con la identificación de qué servicios son verdaderamente críticos y qué nivel de interrupción es aceptable. Un servidor de voz de sala de control puede justificar una redundancia completa, mientras que una herramienta de informes no esencial puede no necesitarla. Un conmutador troncal puede requerir enlaces ascendentes duplicados, mientras que una impresora local de bajo impacto no necesita la misma atención.
Este enfoque basado en el riesgo ayuda a las organizaciones a aplicar la redundancia donde ofrece el mayor valor. También evita el sobrediseño, donde se aumenta la complejidad sin un beneficio operativo significativo. El objetivo no es duplicar todo a ciegas. El objetivo es proteger las partes del sistema cuyo fallo tendría consecuencias desproporcionadas.
Por lo tanto, una buena planificación de la redundancia es estratégica. Alinea la arquitectura técnica con las prioridades operativas.
Conclusión
Por Qué es Importante la Redundancia
La redundancia es importante porque los sistemas modernos son demasiado importantes para depender completamente de una ruta, un nodo o una fuente de energía. Ya sea que el entorno sea un sistema telefónico de oficina, una plataforma de comunicación industrial, una red de control o un servicio empresarial basado en la nube, el riesgo de un punto único de fallo puede interrumpir las operaciones, reducir la seguridad y dañar la calidad del servicio. La redundancia reduce ese riesgo al preparar la continuidad con anticipación.
Su valor práctico radica en una mejor disponibilidad, una mayor tolerancia a fallos, una mejor flexibilidad de mantenimiento y un servicio más confiable durante eventos anormales. Al mismo tiempo, la redundancia no es solo una cuestión de agregar hardware adicional. Requiere una buena lógica de conmutación por fallo, sincronización, pruebas y disciplina de arquitectura. Los sistemas redundantes más efectivos son aquellos diseñados en torno a necesidades operativas reales en lugar de ambiciones técnicas abstractas.
A medida que las organizaciones continúan confiando en la comunicación siempre activa y la infraestructura digital, la redundancia sigue siendo uno de los componentes básicos más importantes del diseño de sistemas resilientes.
Preguntas Frecuentes
¿Es la redundancia lo mismo que la copia de seguridad?
No. La copia de seguridad generalmente se refiere a una copia de reserva o un recurso de recuperación, mientras que la redundancia generalmente significa que los recursos duplicados en vivo están integrados en el sistema para mantener el servicio en funcionamiento durante una falla.
¿Cuál es el propósito principal de la redundancia?
El propósito principal es reducir los puntos únicos de fallo y mejorar la continuidad del servicio cuando fallan equipos, enlaces, software o fuentes de alimentación.
¿Dónde se usa comúnmente la redundancia?
Se usa comúnmente en redes, sistemas de telefonía SIP e IP, entornos de control industrial, centros de datos, plataformas de seguridad y sistemas de comunicación de emergencia.
¿La redundancia garantiza cero tiempo de inactividad?
No siempre. La redundancia puede reducir en gran medida el tiempo de inactividad, pero el resultado real depende de la calidad de la arquitectura, el diseño de la conmutación por fallo, la sincronización y las pruebas.