Una alarma de fallo es una señal de advertencia generada cuando equipos, software, sistemas de comunicación, sensores, dispositivos de alimentación, máquinas industriales, terminales de seguridad o plataformas de infraestructura detectan una condición anormal. Ayuda a los operadores a identificar fallos, responder con rapidez, reducir el tiempo de inactividad y evitar que pequeños problemas técnicos se conviertan en riesgos operativos mayores.
Una alarma de fallo no es solo un mensaje de advertencia. Es el punto de inicio de un flujo de respuesta que conecta detección, notificación, verificación, despacho, mantenimiento y recuperación.
Significado básico y función en el sistema
Una alarma de fallo indica que un dispositivo, circuito, servicio, sensor o componente del sistema no está funcionando como se espera. El fallo puede estar relacionado con pérdida de energía, desconexión de red, avería de equipo, interrupción de señal, temperatura anormal, batería baja, error de sensor, tiempo de espera de comunicación, daño de hardware, excepción de software o estado operativo inseguro.
En los sistemas modernos, las alarmas de fallo suelen enviarse a una plataforma de monitorización, sala de control, panel de mantenimiento, centro de despacho, aplicación móvil o sistema de notificación. Su finalidad es hacer que las condiciones anormales sean visibles y accionables para que el equipo responsable pueda responder antes de que la calidad del servicio o la seguridad se vean seriamente afectadas.
Alarma de fallo frente a notificación general
Una notificación general puede ofrecer información rutinaria, como actualizaciones de estado, recordatorios o mensajes operativos. Una alarma de fallo es más específica porque señala una condición anormal que requiere atención, verificación o acción correctiva.
Por ejemplo, “dispositivo en línea” es una notificación de estado, mientras que “dispositivo fuera de línea”, “fallo de alimentación”, “comunicación perdida” o “fallo de sensor” son alarmas de fallo. El nivel de alarma, el tiempo de respuesta y la regla de escalamiento deben corresponder a la gravedad del problema.
Por qué es importante en la operación diaria
Sin alarmas de fallo, los equipos de mantenimiento pueden descubrir los problemas solo después de que los usuarios se quejen, el equipo se detenga, la producción se interrumpa o aparezcan riesgos de seguridad. Este enfoque reactivo aumenta el tiempo de inactividad y complica el diagnóstico.
Con alarmas de fallo bien configuradas, los operadores pueden detectar incidencias antes. Un dispositivo de red puede informar una caída de enlace, un módulo de alimentación puede informar voltaje anormal, un terminal de emergencia puede informar estado fuera de línea y un sensor puede informar datos inválidos antes de que todo el sistema deje de estar disponible.

Cómo funciona la detección de alarmas de fallo
La detección de alarmas de fallo normalmente comienza con una monitorización continua. El sistema revisa parámetros operativos, estado del dispositivo, comunicación, alimentación, datos ambientales, registros de software o retroalimentación de sensores. Cuando un valor supera un umbral definido o desaparece una señal necesaria, se genera una alarma.
El método de detección depende del tipo de sistema. Los equipos industriales pueden usar sensores y señales PLC. Los sistemas de TI pueden usar registros y comprobaciones de salud. Los sistemas de comunicación pueden usar estado de registro, mensajes de latido, pérdida de paquetes y sondeo de dispositivos. Los dispositivos de seguridad pueden usar entradas de contacto seco, interruptores antisabotaje, estado de batería o supervisión de red.
Detección basada en umbrales
La detección basada en umbrales utiliza límites predefinidos. Si la temperatura supera un nivel seguro, el voltaje cae por debajo del rango permitido, el uso de almacenamiento es demasiado alto o la señal es demasiado débil, el sistema activa una alarma de fallo.
Este método es fácil de entender y se usa ampliamente. Sin embargo, los umbrales deben configurarse con cuidado. Si son demasiado sensibles, habrá falsas alarmas frecuentes; si son demasiado laxos, pueden perderse señales tempranas de advertencia.
Detección basada en estado
La detección basada en estado supervisa si un dispositivo o servicio se encuentra en el estado esperado. Los ejemplos incluyen en línea o fuera de línea, normal o fallo, registrado o no registrado, abierto o cerrado, activo o inactivo, cargado o con batería baja.
Este método es común en plataformas de comunicación, control de acceso, monitorización eléctrica, automatización de edificios y terminales de llamada de emergencia. Un dispositivo que deja de informar su estado puede generar una alarma de fuera de línea o de fallo de comunicación.
Detección basada en eventos
La detección basada en eventos responde a eventos concretos del sistema. Estos pueden incluir fallo de reinicio, error de módulo, desconexión de sensor, sabotaje de puerta, corte de línea, disparo por sobrecorriente, caída de software, inicio de sesión fallido o cambio de configuración anormal.
Las alarmas basadas en eventos son útiles porque suelen aportar más detalle que las alarmas simples por umbral. Ayudan a los técnicos a entender no solo que algo va mal, sino también qué tipo de fallo se produjo.
Funciones principales de un sistema de alarmas de fallo
Un sistema útil de alarmas de fallo debe hacer más que mostrar advertencias. Debe clasificar alarmas, identificar ubicaciones, filtrar eventos repetidos, admitir escalamiento, registrar acciones de respuesta y ayudar al equipo a cerrar el fallo tras la reparación.
Clasificación de alarmas
Las alarmas de fallo suelen clasificarse por gravedad, tipo de sistema, ubicación, dispositivo origen o categoría de fallo. Los niveles comunes incluyen información, advertencia, menor, mayor y crítico. La clasificación ayuda a los operadores a decidir qué alarma debe atenderse primero.
Por ejemplo, un recordatorio de mantenimiento de baja prioridad no debe recibir la misma respuesta que un fallo crítico de comunicación en un sistema de llamada de emergencia. Una clasificación clara evita la sobrecarga de alarmas y mejora la eficiencia de respuesta.
Notificación en tiempo real
La notificación en tiempo real permite enviar alarmas inmediatamente a las personas o plataformas adecuadas. Los métodos pueden incluir ventanas emergentes en paneles, correo electrónico, SMS, alertas de aplicación móvil, llamadas de voz, enlace con megafonía o eventos en sistemas de despacho.
Las reglas de notificación deben coincidir con turnos y responsabilidades. Un fallo eléctrico puede ir a los ingenieros de instalaciones, un fallo de red al personal de TI y un fallo de terminal de emergencia al equipo de seguridad o a la sala de control.
Identificación de ubicación y dispositivo
Una alarma de fallo debe indicar claramente dónde se encuentra el problema. La información útil incluye nombre del dispositivo, ID, sala, planta, edificio, zona, sitio, posición en mapa, categoría del sistema y marca de tiempo.
Sin información de ubicación, los técnicos pueden perder mucho tiempo buscando el dispositivo afectado. En campus grandes, parques industriales, túneles, hospitales, estaciones de transporte e instalaciones públicas, una identificación precisa es esencial.
Reconocimiento y cierre de alarmas
El reconocimiento confirma que un operador vio la alarma y acepta la responsabilidad de seguimiento. El cierre confirma que el fallo fue reparado, verificado o resuelto de otra manera.
Este flujo evita que las alarmas se ignoren. También crea un registro trazable que muestra cuándo ocurrió el fallo, quién lo gestionó, qué acción se tomó y cuándo el sistema volvió a la normalidad.
Escalamiento y control de alarmas repetidas
Si una alarma no se atiende dentro de un tiempo definido, el sistema puede escalarla a un supervisor, otro equipo o un centro de mando superior. El escalamiento es importante en sistemas críticos donde una respuesta tardía puede crear riesgos de seguridad o de servicio.
El control de alarmas repetidas también es importante. Si un dispositivo envía la misma alarma una y otra vez, la plataforma debe agrupar o suprimir duplicados cuando corresponda. Esto reduce la fatiga por alarmas y mantiene a los operadores concentrados en eventos significativos.
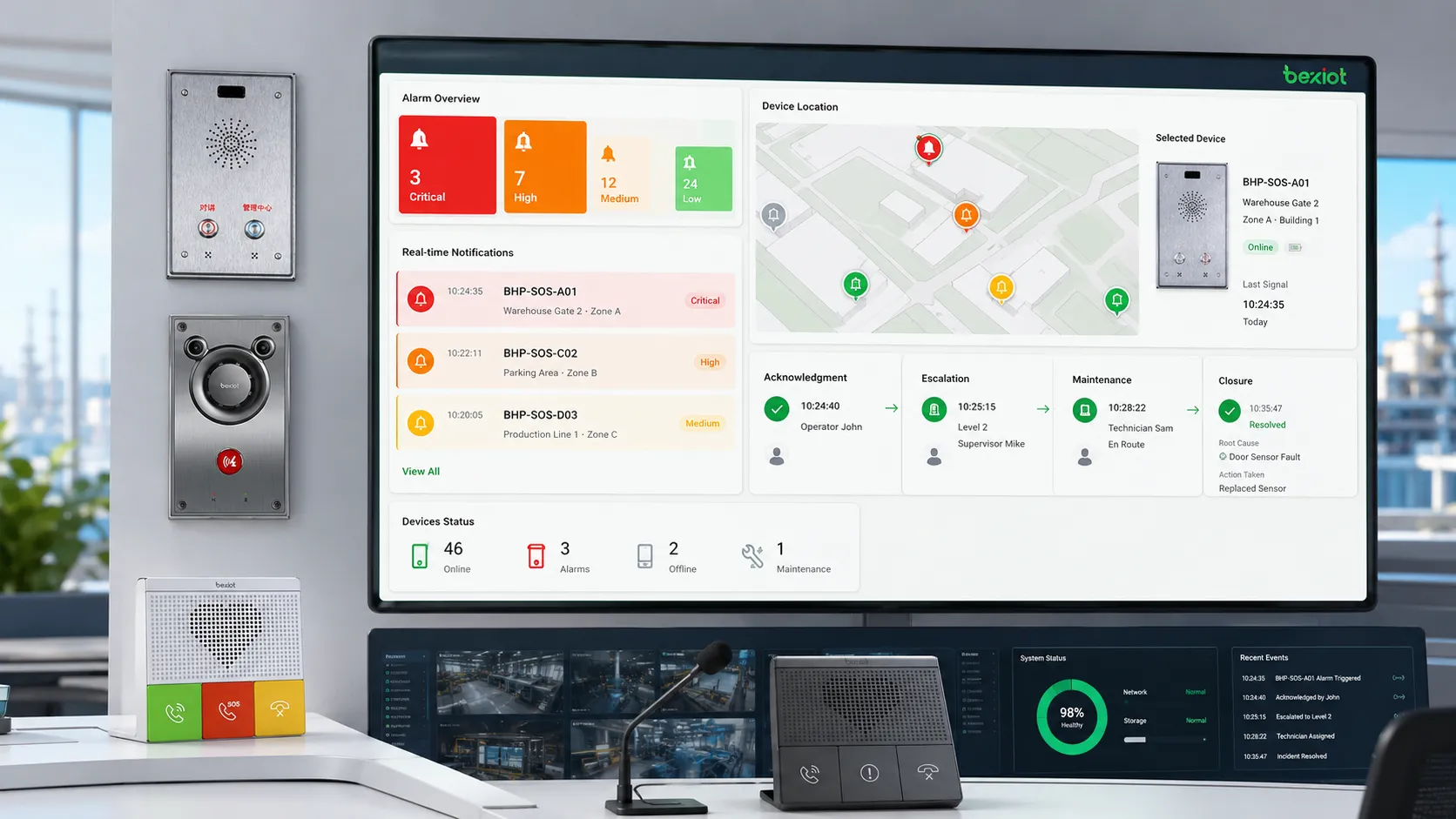
Valor para la fiabilidad y la seguridad
Las alarmas de fallo aportan valor al hacer visibles los problemas ocultos. Ayudan a los equipos a pasar de la reparación pasiva a la monitorización y respuesta activas. Cuando los datos de alarmas se gestionan bien, apoyan la planificación de mantenimiento, la mejora del servicio, el control de riesgos y la optimización a largo plazo.
Descubrimiento más rápido de fallos
Las alarmas de fallo reducen el tiempo entre la aparición de un fallo y su detección. En lugar de esperar a una inspección manual, el sistema informa automáticamente condiciones anormales cuando ocurren.
Una detección más rápida ayuda a reducir el tiempo de inactividad. Si un dispositivo está fuera de línea, una batería está baja, un servicio de servidor se detiene o un terminal de comunicación no está registrado, el equipo de mantenimiento puede actuar antes de que los usuarios se vean afectados.
Mayor eficiencia de mantenimiento
Las alarmas de fallo proporcionan a los equipos de mantenimiento información más precisa. En lugar de revisar cada dispositivo manualmente, los técnicos pueden priorizar las alarmas por gravedad, ubicación y tipo de sistema.
Los registros históricos también ayudan a identificar fallos recurrentes. Si el mismo dispositivo informa repetidamente pérdida de red o fallo de alimentación, la causa raíz puede estar en el cableado, el entorno, la configuración o el envejecimiento del hardware.
Mejor control del riesgo
Algunos fallos generan riesgos de seguridad, como un dispositivo de emergencia fuera de línea, fallo de interfaz contra incendios, mal funcionamiento del control de acceso, anomalía de alimentación, fallo de línea de comunicación o fallo de sensor en entornos peligrosos.
La detección temprana ayuda a reducir estos riesgos. En sistemas relacionados con la seguridad, las alarmas de fallo deben probarse con regularidad y vincularse a procedimientos de respuesta claros.
Mayor visibilidad operativa
Cuando las alarmas se recopilan en una plataforma central, los responsables pueden ver la salud del sistema en varios sitios, edificios, zonas o departamentos. Esto favorece una mejor asignación de recursos y revisión del rendimiento.
La visibilidad operativa es especialmente útil para organizaciones grandes con infraestructura distribuida. Ayuda a saber qué sistemas son estables, qué dispositivos fallan con frecuencia y dónde se necesita inversión o mejora de mantenimiento.
Escenarios de aplicación comunes
Las alarmas de fallo se usan en muchos sistemas porque casi todo entorno técnico necesita detectar condiciones anormales. La lógica puede variar, pero el objetivo se mantiene: identificar fallos rápidamente y guiar la respuesta.
Automatización industrial y equipos de producción
Los sistemas industriales usan alarmas de fallo en motores, bombas, transportadores, sensores, PLC, variadores, armarios de control, fuentes de alimentación, sistemas de temperatura, aire comprimido y equipos de producción. Las alarmas pueden indicar sobrecarga, sobrecalentamiento, presión anormal, desconexión de sensor, parada de emergencia o pérdida de comunicación.
En producción, las alarmas ayudan a reducir paradas no planificadas y a apoyar la programación de mantenimiento. También ayudan a los operadores a proteger equipos y evitar daños secundarios.
Gestión de edificios e instalaciones
Los sistemas de edificios usan alarmas para HVAC, ascensores, control de iluminación, control de acceso, interfaces de incendio, detección de fugas de agua, distribución eléctrica, UPS, dispositivos de seguridad y plataformas de gestión energética.
Los equipos de instalaciones dependen de estas alarmas para mantener edificios seguros y confortables. Una bomba fallida, un controlador fuera de línea, una temperatura anormal o un fallo eléctrico puede afectar a ocupantes y continuidad si no se atiende rápido.
Sistemas de comunicación y emergencia
Los sistemas de comunicación pueden generar alarmas por fallo de registro SIP, interrupción de red, dispositivo fuera de línea, fallo de ruta de audio, fallo de troncal, error de gateway, batería baja o servicio de servidor anormal.
Para puntos de comunicación de emergencia, intercomunicadores con botón de alarma, terminales SOS y sistemas públicos de ayuda, la salud del dispositivo es crítica. Las soluciones Becke Telcom BHP-SOS pueden considerarse en proyectos donde se necesite integrar activación de emergencia, comunicación de voz y supervisión de estado en un flujo de seguridad o despacho.
Infraestructura de TI y plataformas en la nube
Los sistemas de TI usan alarmas para servidores, almacenamiento, bases de datos, máquinas virtuales, contenedores, dispositivos de red, firewalls, aplicaciones, API y servicios en la nube. Las alarmas pueden relacionarse con uso de CPU, presión de memoria, fallo de disco, caída de servicio, alta latencia, pérdida de paquetes o copia de seguridad fallida.
En servicios digitales, una alarma de fallo ayuda a responder antes de que los usuarios sufran problemas graves. La monitorización y las alertas son parte central de operaciones de TI, DevOps e ingeniería de fiabilidad del sitio.
Energía, potencia y servicios públicos
Los sistemas de energía y servicios públicos usan alarmas para subestaciones, transformadores, inversores, baterías, generadores, cuadros de distribución, medidores, equipos solares y almacenamiento de energía.
Estas alarmas apoyan la operación segura y la continuidad. Voltaje anormal, sobrecarga, fallo de aislamiento, problema de puesta a tierra, fallo de comunicación o advertencia de batería pueden requerir respuesta técnica inmediata.

Integración con flujos de respuesta
Una alarma de fallo resulta más útil cuando está conectada a un flujo de respuesta. El flujo debe definir quién recibe la alarma, cómo se verifica, qué acción se requiere, cuándo se escala y cómo se cierra.
Verificación del operador
Después de que aparece una alarma, el operador debe verificar si es real, repetida, temporal o si ya está en mantenimiento. La verificación puede incluir revisar estado del dispositivo, ver cámaras, llamar al personal de campo, revisar registros o probar el servicio afectado.
La verificación evita despachos innecesarios. También ayuda a no ignorar fallos reales que al principio parecen menores pero pueden convertirse en problemas mayores.
Despacho de mantenimiento
Una vez confirmado el fallo, el sistema puede crear una tarea de mantenimiento o enviar un técnico. La tarea debe incluir tipo de alarma, ubicación, ID de dispositivo, hora del fallo, severidad y pasos sugeridos de diagnóstico si están disponibles.
En sitios grandes, el despacho basado en mapas y los registros de ubicación reducen el tiempo de respuesta. Los técnicos deben poder encontrar rápido el equipo afectado y confirmar el resultado de la reparación.
Vinculación con herramientas de comunicación
Las alarmas pueden activar acciones de comunicación como llamadas de voz, SMS, notificaciones push, llamadas de intercomunicador, despacho por radio o anuncios de megafonía. El tipo de aviso debe corresponder a la severidad y al público.
Por ejemplo, un fallo no crítico puede avisar solo al personal de mantenimiento, mientras que una alarma crítica de terminal de emergencia fuera de línea puede avisar tanto a la sala de control como al supervisor de turno.
Factores para seleccionar un sistema de alarmas de fallo
Elegir un sistema de alarmas requiere entender los dispositivos, riesgos, equipos de respuesta e integraciones necesarias. Un sitio simple puede necesitar solo indicadores locales, mientras que una instalación grande puede requerir monitorización centralizada y escalamiento automático.
| Factor de selección | Por qué importa | Qué comprobar |
|---|---|---|
| Fuente de alarma | Determina qué se puede monitorizar | Dispositivos, sensores, sistemas, contactos, estado de red, registros de software |
| Clasificación de severidad | Ayuda a priorizar la respuesta | Niveles crítico, mayor, menor, advertencia e información |
| Método de notificación | Asegura que la alarma llegue a las personas correctas | Panel, SMS, correo, push de app, llamada de voz, enlace de despacho |
| Precisión de ubicación | Reduce el tiempo de respuesta en campo | ID de dispositivo, zona, sala, punto de mapa, planta, nombre del sitio |
| Historial de eventos | Apoya mantenimiento y revisión | Hora de alarma, reconocimiento, acción, cierre, recurrencia |
| Capacidad de integración | Conecta alarmas con flujos reales | API, entrada de contacto seco, SNMP, Modbus, BACnet, SIP, webhook, enlace de plataforma |
Ajustar el método de alarma al dispositivo
Los dispositivos informan fallos de maneras diferentes. Algunos usan salidas de contacto seco, otros protocolos de red, otros API de software y algunos solo indicadores locales. El sistema de monitorización debe admitir el tipo de señal requerido.
Si el sistema no puede leer correctamente la señal de fallo, la alarma puede no llegar a los operadores. La compatibilidad debe verificarse durante el diseño y la puesta en marcha.
Diseñar para una capacidad real de respuesta
Un sistema de alarmas debe coincidir con la capacidad real de respuesta de la organización. Si demasiadas alarmas de bajo valor se envían a demasiadas personas, el personal puede ignorarlas. Si las alarmas críticas no se escalan rápido, la respuesta puede retrasarse.
El mejor diseño separa eventos urgentes de advertencias rutinarias y proporciona una regla de respuesta adecuada para cada tipo.
Planificar la expansión futura
A medida que los sitios crecen, puede ser necesario monitorizar más dispositivos y sistemas. La plataforma debe admitir más puntos, nuevos tipos de dispositivos, sitios remotos, roles de usuario, informes e integraciones.
La expansión futura es más sencilla cuando la nomenclatura de alarmas, los ID de dispositivos, las zonas y las categorías se planifican claramente desde el principio.
Consejos de mantenimiento para alarmas fiables
Los sistemas de alarmas de fallo también necesitan mantenimiento. Si las reglas quedan obsoletas, los nombres de dispositivos son incorrectos, fallan los enlaces de comunicación o los contactos de notificación ya no son válidos, el sistema puede no apoyar la respuesta cuando se necesite.
Probar regularmente las rutas de alarma
Las pruebas deben confirmar que el dispositivo genera la alarma, la plataforma la recibe, la ubicación es correcta y la notificación llega a la persona adecuada. Deben incluir disparo normal y recuperación de fallo.
Las alarmas críticas deben probarse con más frecuencia. Los registros de prueba deben incluir hora, dispositivo, tipo de alarma, resultado, respuesta del operador y acción correctiva.
Revisar los umbrales de alarma
Los umbrales pueden requerir ajuste tras envejecimiento de equipos, cambios ambientales, expansión del sistema o experiencia operativa. Demasiadas falsas alarmas indican sensibilidad excesiva; advertencias perdidas pueden indicar umbrales demasiado laxos.
La revisión debe basarse en datos reales, no en suposiciones. Las tendencias históricas de alarmas ayudan a refinar la configuración.
Mantener actualizados los registros de dispositivos
Los nombres, ubicaciones, contactos, direcciones IP, versiones de firmware y propietarios del sistema deben actualizarse cuando los equipos se mueven, reemplazan o reconfiguran.
Los registros obsoletos retrasan el mantenimiento. Si una alarma muestra una ubicación incorrecta o un nombre antiguo, los técnicos pueden revisar el equipo equivocado.
Analizar fallos repetidos
Las alarmas repetidas no deben tratarse como eventos aislados. Si un dispositivo, cable, fuente de alimentación, segmento de red o sensor informa fallos repetidamente, debe investigarse la causa raíz.
Las alarmas recurrentes pueden indicar mala instalación, alimentación inestable, estrés ambiental, hardware envejecido, cobertura de red débil o configuración incorrecta. El análisis de causa raíz reduce futuras alarmas y mejora la fiabilidad.
Errores comunes que se deben evitar
Un error común es habilitar demasiadas alarmas sin clasificación. Esto causa fatiga por alarmas, abruma a los operadores y puede hacer que se pierdan eventos críticos. Las reglas deben ser significativas y priorizadas.
Otro error es ignorar el cierre de alarmas. Si permanecen abiertas después de la reparación, los operadores no saben si el sistema sigue fallando o si el registro no fue actualizado. Los procedimientos de cierre son necesarios para la trazabilidad.
Un tercer error es tratar las alarmas de fallo como información solo de mantenimiento. Algunas afectan a seguridad, protección, atención al cliente y continuidad del negocio. Su flujo de respuesta debe reflejar su impacto operativo real.
FAQ
¿Qué es una alarma de fallo?
Una alarma de fallo es una advertencia generada cuando un dispositivo, sistema, sensor, circuito, servicio de software o enlace de comunicación detecta una condición anormal. Ayuda a los operadores a identificar y responder a fallos o riesgos.
¿Cuál es la diferencia entre una alarma de fallo y una notificación de evento?
Una notificación de evento puede informar actividad normal o anormal. Una alarma de fallo indica específicamente que algo está mal o fuera del estado operativo esperado y puede requerir acción correctiva.
¿Dónde se usan comúnmente las alarmas de fallo?
Se usan en automatización industrial, gestión de edificios, sistemas de comunicación, terminales de emergencia, infraestructura de TI, energía, plataformas de seguridad, distribución eléctrica y monitorización de instalaciones.
¿Qué información debe incluir una alarma de fallo?
Debe incluir tipo de alarma, severidad, hora, nombre del dispositivo, ubicación, categoría del sistema, estado actual, acción sugerida si existe y registro de reconocimiento o cierre.
¿Cómo se pueden reducir las falsas alarmas?
Pueden reducirse con umbrales adecuados, filtrado de duplicados, mejor calidad de sensores, mantenimiento de dispositivos, verificación de enlaces de comunicación, lógica de retardo cuando proceda y revisión de datos históricos.
¿Pueden los intercomunicadores con botón de alarma BHP-SOS apoyar flujos de alarmas de fallo?
Sí. Los intercomunicadores Becke Telcom BHP-SOS pueden considerarse para proyectos que necesitan activación de emergencia, comunicación de voz, supervisión de estado del dispositivo y enlace con plataformas de seguridad o despacho. La configuración final debe ajustarse al método de monitorización y al procedimiento de respuesta del sitio.