

Mantener los servicios en funcionamiento cuando algo falla
La conmutación por error es un mecanismo de confiabilidad que cambia de forma automática o manual las operaciones desde un componente principal fallido hacia un componente de respaldo. Se utiliza para mantener disponibles aplicaciones, redes, servidores, bases de datos, sistemas de comunicación, servicios en la nube y plataformas industriales cuando dejan de funcionar el hardware, el software, los enlaces o los servicios.
En términos simples, la conmutación por error responde a una pregunta esencial: si el sistema principal falla, ¿qué toma el control? Una arquitectura bien diseñada reduce el tiempo de inactividad, protege la continuidad del servicio y ayuda a las organizaciones a recuperarse con mayor rapidez ante fallos, sobrecargas, tareas de mantenimiento o interrupciones inesperadas.
La conmutación por error no evita todas las fallas. Su valor está en ofrecer al sistema una ruta de recuperación preparada cuando la falla ocurre.
Significado básico y función dentro del sistema
La conmutación por error se utiliza habitualmente en diseños de alta disponibilidad. Un recurso principal gestiona la operación normal, mientras uno o más recursos en espera permanecen preparados para asumir el servicio si el recurso principal deja de estar disponible. El respaldo puede ser otro servidor, router, nodo de base de datos, enlace de red, centro de datos, región de nube, sistema de almacenamiento o instancia de aplicación.
El objetivo es reducir la interrupción del servicio. En lugar de esperar a que los técnicos reparen el componente averiado antes de continuar, el sistema redirige el tráfico, las cargas de trabajo, las sesiones o las solicitudes hacia otro recurso disponible.
Recursos principales y en espera
El recurso principal es el componente activo que presta normalmente el servicio. El recurso en espera está preparado para asumirlo cuando el principal falla. En algunos sistemas, el recurso de respaldo permanece pasivo hasta que se activa la conmutación. En otros, varios recursos comparten el tráfico de manera activa al mismo tiempo.
Por ejemplo, un sitio web puede ejecutarse en dos servidores de aplicaciones. Si el primer servidor falla, el tráfico puede enviarse al segundo. Un router puede usar un enlace WAN de respaldo si se cae la conexión principal a internet. Una base de datos puede promover una réplica para convertirla en el nuevo nodo principal cuando el nodo original deja de funcionar.
Detección de fallas
La conmutación por error depende de la detección de fallas. El sistema debe saber cuándo el componente principal no está sano. La detección puede usar señales de latido, comprobaciones de estado, monitoreo de enlaces, sondas de servicio, estado de replicación de bases de datos, comprobaciones de respuesta de aplicaciones o pruebas de alcance de red.
Una buena detección debe ser lo suficientemente rápida para reducir el tiempo de inactividad, pero no tan sensible como para activar cambios innecesarios por un retraso breve o una pérdida temporal de paquetes. Ese equilibrio es importante en el diseño real de redes y aplicaciones.
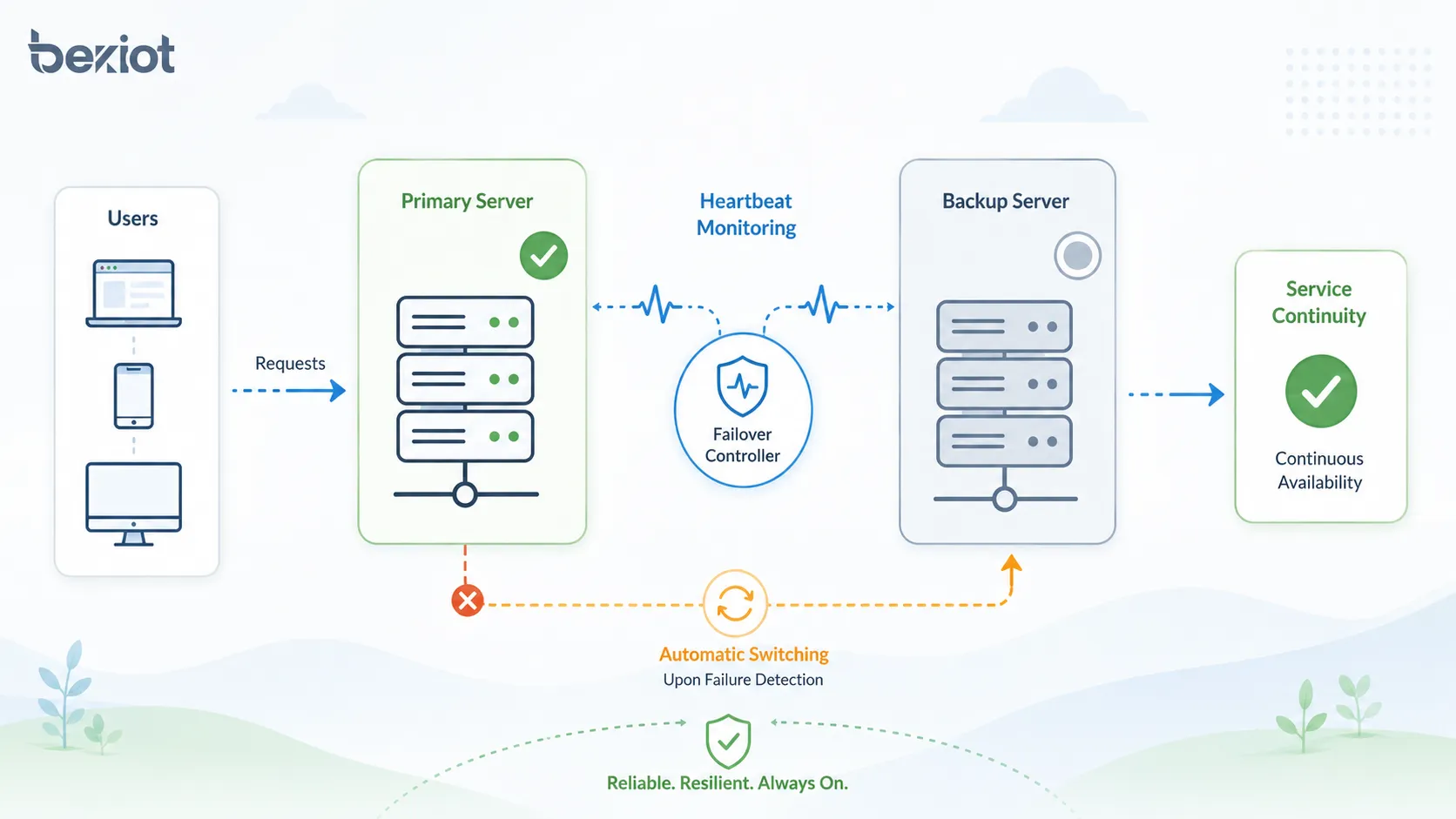
Cómo funciona el proceso de conmutación
El proceso de conmutación por error suele incluir monitoreo, detección de fallas, toma de decisiones, cambio de servicio, redirección de tráfico, verificación de recuperación y registro de eventos. Los detalles varían según el tipo de sistema, pero la lógica central es similar.
Cuando el mecanismo de monitoreo detecta que el sistema principal no está disponible o no está sano, el controlador de conmutación activa la ruta de respaldo. Los usuarios pueden notar una breve interrupción, pero el servicio debería continuar a través del componente alternativo.
Monitoreo y comprobaciones de estado
Las comprobaciones de estado se usan para confirmar si un servicio funciona correctamente. Una comprobación básica puede limitarse a verificar si un servidor responde a ping. Una comprobación más avanzada puede validar si la aplicación procesa solicitudes, se conecta a la base de datos y devuelve respuestas válidas.
Las comprobaciones a nivel de aplicación suelen ser más fiables que las comprobaciones simples de red. Un servidor puede seguir respondiendo a ping aunque la aplicación esté congelada, sobrecargada o sin acceso a servicios backend necesarios.
Cambio hacia recursos de respaldo
Una vez confirmada la falla, el sistema cambia la operación al recurso de respaldo. Esto puede implicar cambiar tablas de enrutamiento, actualizar registros DNS, mover una dirección IP virtual, promover una réplica de base de datos, activar un servidor en espera o redirigir el tráfico mediante un balanceador de carga.
El método de cambio debe coincidir con el requisito del negocio. Algunos sistemas pueden tolerar unos minutos de interrupción, mientras que los sistemas críticos pueden requerir una conmutación casi instantánea con impacto mínimo para el usuario.
Verificación del servicio después del cambio
Después de la conmutación, el servicio de respaldo debe verificarse. El sistema debe confirmar que los usuarios pueden conectarse, las transacciones pueden continuar, los datos están disponibles y los servicios dependientes funcionan correctamente.
La verificación es importante porque cambiar el tráfico a un componente de respaldo no garantiza por sí solo una operación normal. El respaldo debe estar sincronizado, correctamente configurado y preparado para soportar la carga de trabajo.
Principales tipos de conmutación por error
La conmutación por error puede diseñarse de distintas maneras según la criticidad del sistema, el presupuesto, los requisitos de rendimiento y los objetivos de recuperación. Los modelos más comunes incluyen activo-pasivo, activo-activo, conmutación manual, conmutación automática, conmutación local y conmutación geográfica.
Conmutación activo-pasivo
En la conmutación activo-pasivo, un sistema atiende activamente el tráfico de producción mientras otro permanece en modo de espera. Si el sistema activo falla, el sistema pasivo se vuelve activo y asume el servicio.
Este modelo es relativamente simple y se usa ampliamente en servidores, firewalls, bases de datos, sistemas PBX, controladores de almacenamiento y gateways de red. Su ventaja principal es la separación clara de funciones. Su limitación es que los recursos en espera pueden quedar infrautilizados durante la operación normal.
Conmutación activo-activo
En la conmutación activo-activo, dos o más sistemas manejan tráfico al mismo tiempo. Si uno falla, los sistemas restantes siguen prestando servicio a los usuarios y absorben la carga adicional.
Este modelo puede mejorar la utilización de recursos y la escalabilidad, pero exige un diseño cuidadoso. El balanceo de carga, la sincronización de datos, el manejo de sesiones, el control de conflictos y la planificación de capacidad se vuelven más complejos.
Conmutación manual y automática
La conmutación manual requiere que un operador o administrador active el cambio. Ofrece control humano y puede ser útil durante mantenimiento, migraciones planificadas o cambios sensibles del sistema.
La conmutación automática se activa mediante reglas del sistema. Es más rápida y adecuada para entornos de alta disponibilidad, pero debe configurarse con cuidado para evitar falsas conmutaciones, condiciones de cerebro dividido o cambios repetidos entre nodos.
Conmutación local y geográfica
La conmutación local ocurre dentro del mismo sitio, rack, centro de datos o zona de red. Protege frente a fallas locales de servidores, enlaces, módulos de energía o dispositivos.
La conmutación geográfica traslada el servicio a otro centro de datos, región de nube o sitio remoto. Protege contra fallas mayores como caída de un centro de datos, interrupción regional de red, pérdida de energía, incendios, inundaciones o incidentes importantes de infraestructura.
Características clave de un diseño fiable
Un buen sistema de conmutación por error no solo debe cambiar con rapidez. Debe hacerlo de forma segura, coherente y predecible. Las funciones más importantes incluyen monitoreo, redundancia, sincronización, control del tráfico, registro y planificación de recuperación.
Componentes redundantes
La redundancia significa contar con componentes de respaldo disponibles antes de que ocurra una falla. Estos componentes pueden incluir servidores, fuentes de alimentación, enlaces de red, routers, switches, rutas de almacenamiento, bases de datos, instancias de aplicación y regiones de nube.
La redundancia debe ser significativa. Un servidor de respaldo conectado a la misma fuente de energía fallida o al mismo switch único quizá no aporte resiliencia real. Los diseñadores deben evitar puntos únicos de falla ocultos.
Latido y monitoreo de estado
Las señales de latido ayudan a los sistemas a comprobar si el nodo principal está vivo. Si el nodo en espera deja de recibir mensajes de latido dentro de un periodo definido, puede asumir que el nodo principal ha fallado.
El diseño del latido debe considerar el retardo de red, la pérdida de paquetes y la confiabilidad del enlace de gestión. Una mala configuración puede causar problemas de cerebro dividido, donde dos nodos creen al mismo tiempo que deben estar activos.
Sincronización de datos
Muchos sistemas de conmutación requieren sincronizar datos entre nodos principales y de respaldo. Esto puede implicar replicación de bases de datos, sincronización de archivos, espejado de almacenamiento, copias de configuración o intercambio de estado.
La sincronización afecta la calidad de recuperación. Si el respaldo tiene datos antiguos, la conmutación puede restaurar el servicio pero perder transacciones recientes. Si la sincronización es demasiado lenta, los objetivos de punto de recuperación pueden no cumplirse.
Redirección automática del tráfico
La redirección de tráfico permite que usuarios o sistemas lleguen al servicio de respaldo después de la conmutación. Puede realizarse mediante balanceadores de carga, direcciones IP virtuales, protocolos de enrutamiento, DNS failover, políticas SD-WAN o gateways de aplicación.
El método de redirección debe coincidir con el tiempo de recuperación esperado. La conmutación basada en DNS puede ser sencilla, pero más lenta por la caché. El balanceador de carga o la IP virtual pueden ser más rápidos en entornos locales de alta disponibilidad.
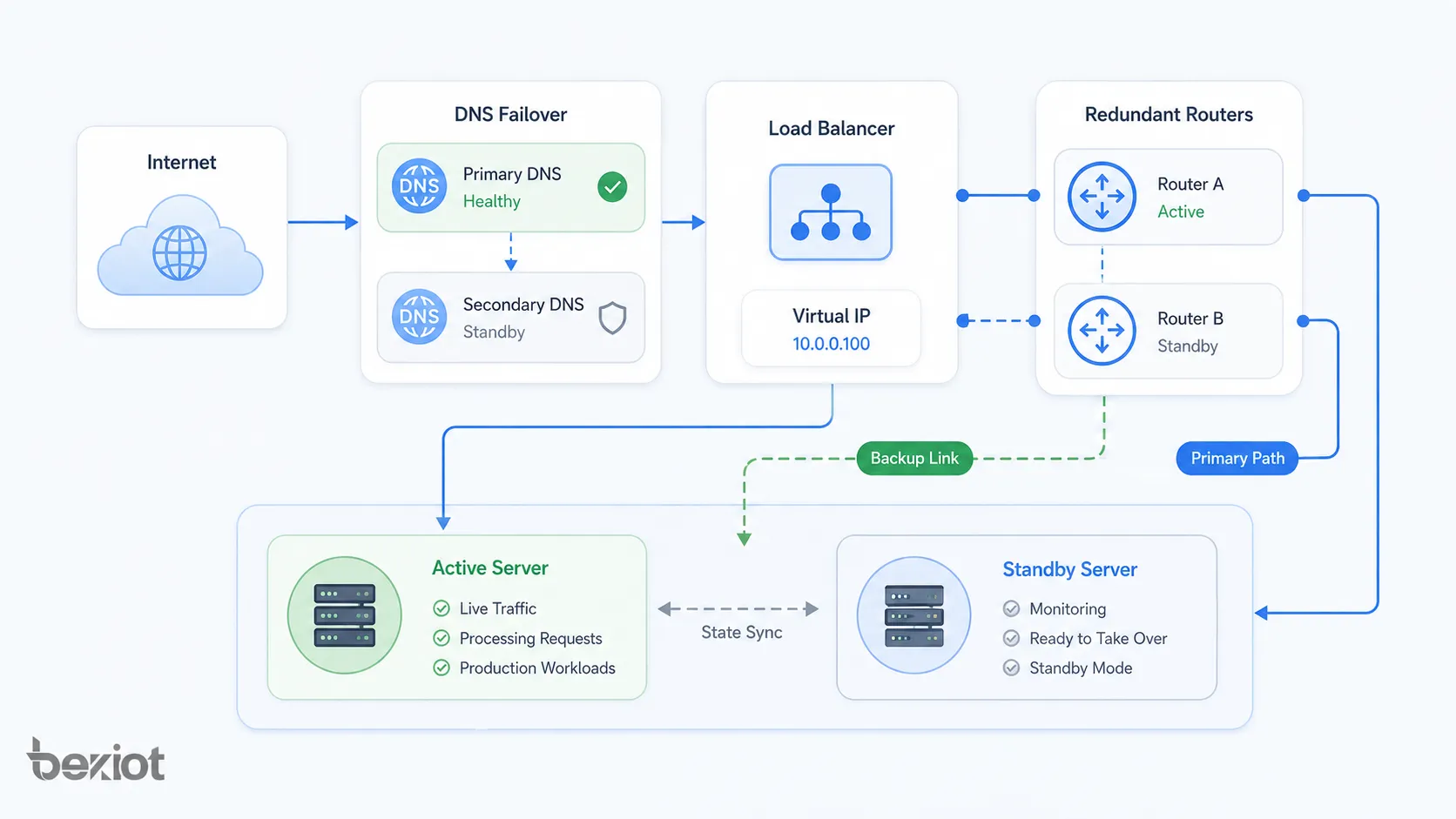
Patrones de arquitectura de red
La arquitectura de conmutación por error puede aplicarse en distintas capas de una red y de una pila de sistemas. Puede proteger enlaces físicos, rutas de enrutamiento, clústeres de servidores, bases de datos, regiones de nube o servicios de aplicación.
Conmutación a nivel de servidor
La conmutación a nivel de servidor utiliza dos o más servidores para ofrecer el mismo servicio. Si un servidor falla, otro asume la operación. Es habitual en servidores de aplicaciones, web, archivos, comunicación y plataformas de gestión.
Este tipo de conmutación puede utilizar software de clúster, plataformas de virtualización, balanceadores de carga, orquestación de contenedores o servicios de alta disponibilidad. La coherencia de configuración entre servidores es esencial.
Conmutación de enlace de red
La conmutación de enlaces de red utiliza rutas de respaldo cuando falla la conexión principal. Algunos ejemplos son doble WAN, enlaces de fibra de respaldo, LTE o 5G de respaldo, conexiones redundantes con proveedores de internet y cambio de enlaces SD-WAN.
Esto es importante para sucursales, sitios remotos, cadenas minoristas, instalaciones industriales y sistemas conectados a la nube. Si el enlace principal falla, el enlace de respaldo mantiene la comunicación disponible, aunque el ancho de banda o la latencia puedan cambiar.
Conmutación de routers y firewalls
Los routers y firewalls suelen admitir pares de alta disponibilidad. Un dispositivo puede estar activo y otro en espera, o ambos pueden compartir carga según el diseño. A menudo se usa una dirección de gateway virtual para que los clientes no necesiten saber qué equipo físico está activo.
La conmutación de firewalls debería sincronizar el estado de las sesiones cuando sea posible. Sin sincronización de sesiones, las conexiones existentes pueden caerse durante la conmutación aunque las nuevas conexiones continúen normalmente.
Conmutación de bases de datos
La conmutación de bases de datos protege los servicios de datos al cambiar de una base principal fallida a una réplica o base en espera. Se usa en aplicaciones empresariales, comercio electrónico, sistemas financieros, servicios en la nube y plataformas operativas críticas.
Requiere manejar con cuidado el retraso de replicación, la coherencia de transacciones, los conflictos de escritura y la reconexión de aplicaciones. Un diseño deficiente puede provocar pérdida de datos o errores de aplicación.
Conmutación en la nube y multirregión
La conmutación en la nube puede mover servicios entre zonas, regiones o proveedores de nube. Esto protege contra fallas de infraestructura local y respalda estrategias de recuperación ante desastres.
La conmutación multirregión puede requerir gestión global del tráfico, bases de datos replicadas, sincronización de almacenamiento de objetos, disponibilidad del servicio de identidad y procedimientos de recuperación probados. El diseño debe alinearse con los objetivos de tiempo y punto de recuperación.
Métricas y objetivos de planificación
La planificación de la conmutación por error suele guiarse por métricas de disponibilidad y recuperación. Estas métricas ayudan a las organizaciones a decidir cuánta redundancia necesitan y cuánto tiempo de inactividad o pérdida de datos es aceptable.
| Métrica | Significado | Por qué importa |
|---|---|---|
| RTO | Objetivo de tiempo de recuperación | Tiempo máximo aceptable para restaurar el servicio después de una falla |
| RPO | Objetivo de punto de recuperación | Cantidad máxima aceptable de pérdida de datos medida en tiempo |
| MTTR | Tiempo medio de reparación | Tiempo promedio requerido para restaurar un componente fallido |
| MTBF | Tiempo medio entre fallas | Tiempo operativo promedio entre fallas |
| Disponibilidad | Porcentaje de tiempo en que un servicio está operativo | Muestra el rendimiento general de tiempo activo del servicio |
Objetivo de tiempo de recuperación
El objetivo de tiempo de recuperación define qué tan rápido debe restaurarse un servicio después de una falla. Una herramienta interna de informes no crítica puede tolerar horas de inactividad, mientras que un sistema de pagos, una plataforma de emergencia o un sistema de control de producción puede requerir recuperación en segundos o minutos.
Un RTO más bajo suele requerir mayor inversión en automatización, redundancia, monitoreo e infraestructura. El diseño debe ajustarse al impacto del negocio en lugar de asumir que todos los sistemas necesitan el mismo nivel de protección.
Objetivo de punto de recuperación
El objetivo de punto de recuperación define cuánta pérdida de datos es aceptable. Si una organización solo puede tolerar unos segundos de datos perdidos, puede necesitar replicación casi en tiempo real. Si puede tolerar varias horas, una copia de seguridad programada puede ser suficiente.
El RPO es especialmente importante para bases de datos, sistemas de archivos, plataformas transaccionales, registros de clientes y logs operativos. Una conmutación sin planificación de datos puede restaurar el servicio, pero aun así generar una pérdida de negocio inaceptable.
Beneficios para el negocio y las operaciones
La conmutación por error aporta valor porque el tiempo de inactividad afecta ingresos, seguridad, productividad, confianza del cliente y continuidad operativa. Una estrategia bien diseñada ayuda a las organizaciones a mantener el servicio durante fallos inesperados y mantenimiento planificado.
Mayor disponibilidad del servicio
El beneficio principal es la mejora de la disponibilidad. Cuando falla un componente principal, el componente de respaldo continúa prestando servicio. Esto reduce la inactividad y ayuda a que los usuarios sigan trabajando.
La alta disponibilidad es importante para servicios en línea, sistemas de comunicación, plataformas sanitarias, redes de transporte, automatización industrial, sistemas financieros y aplicaciones de cara al público.
Menor riesgo operativo
La conmutación por error reduce el riesgo de que la falla de un solo componente detenga todo el sistema. Es especialmente importante en sistemas con puntos únicos de falla, como un único enlace de internet, servidor, base de datos o gateway.
Al añadir rutas de respaldo y lógica de recuperación automatizada, las organizaciones pueden reducir el impacto de fallos de hardware, caídas de red, bloqueos de software e interrupciones por mantenimiento.
Más flexibilidad de mantenimiento
La conmutación por error puede apoyar el mantenimiento planificado. Los administradores pueden mover el servicio de un nodo a otro, actualizar el sistema principal, probar cambios y volver a conmutar cuando el trabajo esté completo.
Esto reduce la necesidad de ventanas de mantenimiento prolongadas. También hace que las actualizaciones sean más seguras porque el servicio puede permanecer disponible mediante recursos de respaldo.
Mayor confianza de los usuarios
Los usuarios quizá no vean directamente el proceso de conmutación, pero sí perciben cuando los servicios siguen disponibles. Los sistemas fiables mejoran la confianza del cliente, la productividad de los empleados y la confianza en la infraestructura digital.
Para plataformas críticas de comunicación, industriales y empresariales, la disponibilidad no es solo una métrica técnica. Forma parte de la experiencia del servicio.
Aplicaciones en distintos sistemas
La conmutación por error se utiliza allí donde la continuidad es importante. El diseño exacto depende del tipo de sistema, pero el objetivo sigue siendo el mismo: evitar la interrupción del servicio cuando algo falla.
Redes empresariales
Las redes empresariales usan conmutación por error para enlaces de internet, firewalls, routers, switches, túneles VPN, controladores inalámbricos y conectividad de sucursales. Si una ruta falla, el tráfico puede desplazarse a otra.
En organizaciones con múltiples sucursales, ayuda a mantener las oficinas remotas conectadas a servicios en la nube, centros de datos, sistemas de comunicación y aplicaciones de negocio.
Centros de datos y plataformas en la nube
Los centros de datos usan conmutación por error en servidores, almacenamiento, bases de datos, clústeres de virtualización, sistemas de energía, refrigeración y tejidos de red. Las plataformas en la nube utilizan zonas de disponibilidad, conmutación regional, balanceadores de carga, grupos de autoescalado y réplicas gestionadas de bases de datos.
Estos diseños ayudan a que las aplicaciones sobrevivan a fallos de hardware, hosts, racks o incluso interrupciones regionales del servicio cuando están bien planificados.
Sistemas VoIP y de comunicación
Los sistemas VoIP y SIP pueden usar conmutación por error para servidores SIP, plataformas PBX, gateways, SBC, troncales SIP, registros DNS SRV, servidores de medios y enlaces de red. Si falla un servidor o una troncal, las llamadas pueden enrutarse por una ruta de respaldo.
Esto es importante para la comunicación empresarial porque la caída de los servicios de voz puede afectar el contacto con clientes, la coordinación interna, las llamadas de emergencia y las operaciones de servicio.
Tecnología industrial y operativa
Los entornos industriales pueden usar conmutación por error para servidores SCADA, redes de control, plataformas de monitoreo, estaciones HMI, historiadores, gateways industriales y enlaces de comunicación. El objetivo es mantener disponibles la producción, el monitoreo y las operaciones relacionadas con la seguridad.
El diseño industrial debe considerar comunicación determinista, compatibilidad de dispositivos, condiciones ambientales y procedimientos operativos seguros. El cambio automático no debe generar comportamientos inseguros en las máquinas.
Aplicaciones web y servicios en línea
Las aplicaciones web usan conmutación por error mediante balanceadores de carga, servidores de aplicaciones replicados, réplicas de bases de datos, servicios CDN, DNS failover y despliegues multirregión. Estos métodos ayudan a que sitios web y API permanezcan disponibles durante fallas de servidores o redes.
En comercio electrónico, banca, SaaS, streaming y portales de clientes, la conmutación por error puede proteger ingresos y experiencia de usuario durante interrupciones inesperadas.
Retos y riesgos comunes
La conmutación por error mejora la resiliencia, pero un diseño deficiente puede crear nuevos problemas. El sistema de respaldo debe probarse, actualizarse, sincronizarse y dimensionarse correctamente. De lo contrario, puede fallar cuando más se necesita.
Falsa conmutación
La falsa conmutación ocurre cuando el sistema cambia al respaldo aunque el servicio principal no haya fallado realmente. Puede deberse a pérdida temporal de paquetes, respuesta lenta, monitoreo sobrecargado o umbrales demasiado agresivos.
Una falsa conmutación puede interrumpir a los usuarios sin necesidad. Las comprobaciones de estado deben diseñarse para confirmar una falla real del servicio antes de cambiar.
Condición de cerebro dividido
Una condición de cerebro dividido ocurre cuando dos nodos creen al mismo tiempo que son el principal activo. Esto puede suceder cuando falla la comunicación de latido, pero ambos sistemas siguen funcionando.
Es peligrosa en bases de datos, almacenamiento y sistemas en clúster porque puede causar corrupción de datos o escrituras conflictivas. Los mecanismos de quórum, el aislamiento de nodos y un diseño de clúster adecuado reducen este riesgo.
Problemas de capacidad del respaldo
Un recurso de respaldo debe tener capacidad suficiente para manejar la carga después de la conmutación. Si el respaldo es demasiado pequeño, el servicio puede seguir técnicamente en línea, pero con bajo rendimiento.
La planificación de capacidad debe considerar carga máxima, crecimiento, operación en modo degradado y la posibilidad de que ocurran varias fallas al mismo tiempo.
Planes de recuperación no probados
Un diseño de conmutación por error que nunca se ha probado no es fiable. La deriva de configuración, certificados caducados, copias antiguas, cambios en firewalls, caché DNS, licencias faltantes o versiones de software antiguas pueden impedir una recuperación exitosa.
Los ejercicios regulares de conmutación son necesarios. Las pruebas deben incluir, cuando sea posible, conmutación planificada y escenarios de falla no planificada.
Buenas prácticas para una implementación fiable
La conmutación por error debe diseñarse como parte de una estrategia más amplia de alta disponibilidad y recuperación ante desastres. Debe incluir planificación de arquitectura, monitoreo, documentación, pruebas y mejora continua.
Identificar primero los servicios críticos
No todos los sistemas necesitan el mismo nivel de conmutación. Las organizaciones deben identificar qué servicios son críticos, cómo afecta la inactividad a las operaciones y qué objetivos de recuperación se requieren.
Esto ayuda a priorizar la inversión. Los sistemas críticos pueden necesitar conmutación automática y redundancia geográfica, mientras que los menos críticos quizá solo requieran copia de seguridad y recuperación manual.
Eliminar puntos únicos de falla ocultos
La conmutación por error puede debilitarse por dependencias ocultas. Un servidor de respaldo puede depender del mismo almacenamiento, fuente de alimentación, switch de red, servicio DNS o sistema de autenticación que el servidor principal.
La revisión de arquitectura debe identificar estas dependencias. La resiliencia real exige redundancia en toda la ruta del servicio, no solo en la capa visible de aplicación.
Mantener la configuración sincronizada
Los sistemas principales y de respaldo deben usar configuraciones coherentes. Diferencias en versión de software, reglas de firewall, certificados, políticas de enrutamiento, datos de usuario o ajustes de aplicación pueden provocar fallos de conmutación.
Las herramientas de gestión de configuración, plantillas, copias de seguridad y control de cambios ayudan a mantener los sistemas alineados. Después de cualquier cambio importante, conviene revisar de nuevo la preparación para la conmutación.
Probar la conmutación con regularidad
Las pruebas periódicas confirman si la conmutación funciona en condiciones reales. Deben verificar tiempo de detección, tiempo de cambio, coherencia de datos, comportamiento de la aplicación, acceso de usuarios, registro y procedimiento de retorno.
Las pruebas deben documentarse. Cada prueba debe registrar qué se comprobó, qué ocurrió, qué falló y qué mejoras son necesarias.
Retorno y recuperación después de la conmutación
La conmutación por error es solo una parte del proceso de recuperación. Después de reparar el sistema principal, la organización debe decidir si mover el servicio de vuelta y cómo hacerlo. Este proceso se denomina retorno o failback.
Cuándo volver al sistema principal
El retorno no debe hacerse demasiado rápido. El sistema principal original debe estar totalmente reparado, probado, sincronizado y verificado antes de devolver el tráfico. Si el retorno se apresura, el sistema puede fallar otra vez y crear una nueva interrupción.
Algunas organizaciones optan por mantener activo el sistema de respaldo hasta la siguiente ventana de mantenimiento. Esto permite un regreso controlado en lugar de un cambio inmediato.
Sincronización de datos y estado
Antes del retorno, los datos creados durante la operación de respaldo deben sincronizarse de nuevo con el sistema principal original. Esto es especialmente importante para bases de datos, archivos, transacciones, sesiones de usuario y cambios de configuración.
Sin una sincronización adecuada, el retorno puede causar pérdida de datos, registros desactualizados o comportamiento inconsistente del servicio.
Revisión posterior al incidente
Después de un evento de conmutación, los equipos deben revisar lo ocurrido. La revisión debe incluir causa de la falla, tiempo de detección, resultado del cambio, impacto en usuarios, rendimiento del respaldo, proceso de comunicación y acciones de mejora.
Esto convierte la conmutación por error de un evento aislado de recuperación en un proceso continuo de mejora de la confiabilidad.
FAQ
¿Qué es la conmutación por error?
La conmutación por error es un mecanismo de confiabilidad que mueve servicios, tráfico, cargas de trabajo u operaciones desde un componente principal fallido hacia un componente de respaldo. Se utiliza para reducir el tiempo de inactividad y mantener la continuidad del servicio.
¿Cuál es la diferencia entre conmutación por error y copia de seguridad?
La copia de seguridad guarda datos o configuraciones para recuperarlos. La conmutación por error mueve el servicio activo a otro recurso cuando ocurre una falla. La copia de seguridad ayuda a restaurar información, mientras que la conmutación ayuda a mantener el servicio funcionando.
¿Qué es la conmutación activo-pasivo?
La conmutación activo-pasivo utiliza un sistema activo y un sistema en espera. El sistema en espera asume el servicio solo cuando el sistema activo falla o se desconecta por mantenimiento.
¿Qué es la conmutación activo-activo?
La conmutación activo-activo utiliza varios sistemas que manejan tráfico al mismo tiempo. Si uno falla, los demás siguen atendiendo a los usuarios y asumen la carga adicional.
¿Dónde se usa habitualmente la conmutación por error?
Se usa habitualmente en redes empresariales, plataformas en la nube, centros de datos, bases de datos, aplicaciones web, sistemas VoIP, firewalls, routers, almacenamiento y plataformas de control industrial.
¿Cómo se puede probar la conmutación por error?
Puede probarse simulando la falla del sistema principal, desconectando rutas de red de forma controlada, apagando nodos de prueba, activando conmutación por mantenimiento, comprobando el cambio de servicio, verificando la coherencia de datos y revisando los registros después de la recuperación.







