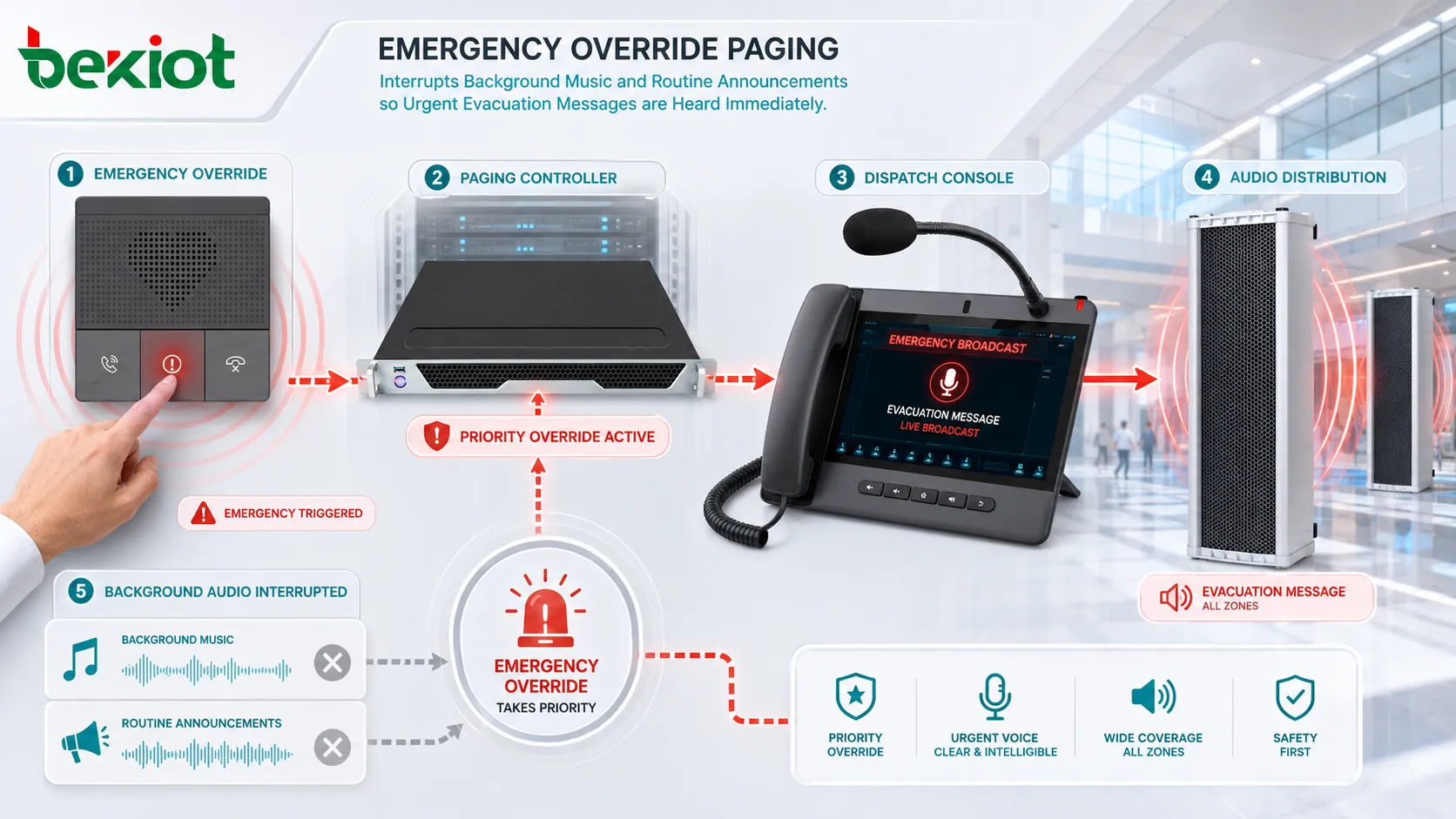
¿Qué es el mantenimiento correctivo y cómo funciona?{tag}>
El mantenimiento correctivo es un enfoque de mantenimiento utilizado para reparar, restaurar, ajustar o reemplazar equipos después de detectar una avería, fallo, condición anormal o problema de rendimiento. Se aplica cuando una máquina, sistema, dispositivo, componente, servicio de software, terminal de comunicación, activo de instalaciones o línea de producción ya no funciona como se esperaba y necesita una acción para volver a su función normal.
A diferencia del mantenimiento preventivo, que se planifica antes de que ocurra la falla, el mantenimiento correctivo responde a un problema real. Puede ser una reparación rápida tras una falla menor, una corrección programada después de una inspección o una reparación urgente tras una avería grave. En operaciones reales, el trabajo correctivo suele combinarse con mantenimiento preventivo, predictivo y basado en condición para crear una estrategia equilibrada de gestión de activos.

Cuando la reparación se vuelve necesaria{tag}>
En la práctica, Cuando la reparación se vuelve necesaria no debe limitarse a cambiar piezas. También debe explicar por qué ocurrió la falla, si puede repetirse y qué cambios son necesarios en relación con causa raíz, sobrecalentamiento, vibración, contaminación, sobrecarga e instalación, para que el mismo incidente no vuelva a generar parada o coste adicional.
Un proceso fiable combina rapidez con verificación. En Cuando la reparación se vuelve necesaria, los técnicos deben confirmar síntomas, aislar la causa, ejecutar la reparación y probar el resultado, manteniendo repuestos aprobados, herramientas estándar, pasos seguros y registro técnico como parte de la trazabilidad de la orden de trabajo.
Las organizaciones maduras integran Cuando la reparación se vuelve necesaria con mantenimiento preventivo, predictivo y basado en condición. Los datos sobre pruebas funcionales, pruebas de carga, calibración y aceptación del usuario permiten ajustar prioridades, inventario de repuestos, formación de operadores y futuras decisiones de inversión.
Detección de fallas{tag}>
Cómo suele desarrollarse el proceso de reparación{tag}>
Cuando el impacto es bajo, Detección de fallas puede programarse para una ventana posterior; cuando afecta seguridad, producción o servicio crítico, debe escalarse de inmediato. El análisis de reparación diferida, parada planificada, seguimiento del riesgo y entrega de repuestos ayuda a evitar tanto la reacción exagerada como la demora peligrosa.
El valor operativo de Detección de fallas aparece cuando cada reparación deja información aprovechable. Si se documentan síntomas, acciones, pruebas y activos no críticos, coste de sustitución, impacto del negocio y disponibilidad de piezas, la empresa reduce recurrencias, mejora disponibilidad y controla mejor el presupuesto.
Evaluación inicial{tag}>
En fábricas, edificios, redes IT, transporte o sanidad, Evaluación inicial requiere reglas claras de prioridad. Relacionar documentación, datos de la orden, tiempo de inactividad y recomendación posterior con procedimientos, pruebas de retorno y recomendaciones de seguimiento convierte una reparación puntual en mejora continua.
El mantenimiento correctivo en Evaluación inicial se centra en devolver un activo a una condición operativa aceptable después de detectar una falla, anomalía o pérdida de rendimiento. Para tomar una decisión útil, el equipo debe valorar fallas repetidas, daños secundarios, defectos ocultos y revisión de diseño y definir una respuesta proporcional al riesgo real.
Diagnóstico y revisión de causa raíz{tag}>
A diferencia de una intervención puramente preventiva, Diagnóstico y revisión de causa raíz responde a un problema que ya existe o que ha sido observado durante una inspección. El registro de MTTR, tiempo entre fallas, primera reparación efectiva y coste de mantenimiento ayuda a preparar herramientas, repuestos, personal y pasos de seguridad antes de actuar.
En la práctica, Diagnóstico y revisión de causa raíz no debe limitarse a cambiar piezas. También debe explicar por qué ocurrió la falla, si puede repetirse y qué cambios son necesarios en relación con máquinas, transportadores, motores, sensores y paneles de control, para que el mismo incidente no vuelva a generar parada o coste adicional.
Reparación o sustitución{tag}>
Un proceso fiable combina rapidez con verificación. En Reparación o sustitución, los técnicos deben confirmar síntomas, aislar la causa, ejecutar la reparación y probar el resultado, manteniendo HVAC, iluminación, ascensores, control de acceso y sistemas contra incendios como parte de la trazabilidad de la orden de trabajo.
Las organizaciones maduras integran Reparación o sustitución con mantenimiento preventivo, predictivo y basado en condición. Los datos sobre servidores, redes, teléfonos, gateways y servicios de software permiten ajustar prioridades, inventario de repuestos, formación de operadores y futuras decisiones de inversión.
Pruebas y retorno al servicio{tag}>
Cuando el impacto es bajo, Pruebas y retorno al servicio puede programarse para una ventana posterior; cuando afecta seguridad, producción o servicio crítico, debe escalarse de inmediato. El análisis de señalización, servicios públicos, enlaces de comunicación y dispositivos de campo ayuda a evitar tanto la reacción exagerada como la demora peligrosa.
El valor operativo de Pruebas y retorno al servicio aparece cuando cada reparación deja información aprovechable. Si se documentan síntomas, acciones, pruebas y equipos médicos, laboratorio, calibración, seguridad y cumplimiento, la empresa reduce recurrencias, mejora disponibilidad y controla mejor el presupuesto.
Reparación de emergencia{tag}>
Diferentes niveles de respuesta{tag}>
En fábricas, edificios, redes IT, transporte o sanidad, Reparación de emergencia requiere reglas claras de prioridad. Relacionar bloqueo, permisos, protección personal e instrucciones de trabajo seguro con procedimientos, pruebas de retorno y recomendaciones de seguimiento convierte una reparación puntual en mejora continua.
El mantenimiento correctivo en Reparación de emergencia se centra en devolver un activo a una condición operativa aceptable después de detectar una falla, anomalía o pérdida de rendimiento. Para tomar una decisión útil, el equipo debe valorar clasificación de repuestos, plazo de suministro, frecuencia de falla y logística remota y definir una respuesta proporcional al riesgo real.
Reparación diferida{tag}>
A diferencia de una intervención puramente preventiva, Reparación diferida responde a un problema que ya existe o que ha sido observado durante una inspección. El registro de formación de operadores, control ambiental, actualización del plan y fiabilidad ayuda a preparar herramientas, repuestos, personal y pasos de seguridad antes de actuar.
En la práctica, Reparación diferida no debe limitarse a cambiar piezas. También debe explicar por qué ocurrió la falla, si puede repetirse y qué cambios son necesarios en relación con detección de fallas, alarmas, lecturas de sensores e informes de operadores, para que el mismo incidente no vuelva a generar parada o coste adicional.
Reparación por funcionamiento hasta la falla{tag}>
Un proceso fiable combina rapidez con verificación. En Reparación por funcionamiento hasta la falla, los técnicos deben confirmar síntomas, aislar la causa, ejecutar la reparación y probar el resultado, manteniendo severidad, seguridad, impacto productivo y prioridad del servicio como parte de la trazabilidad de la orden de trabajo.
Las organizaciones maduras integran Reparación por funcionamiento hasta la falla con mantenimiento preventivo, predictivo y basado en condición. Los datos sobre causa raíz, sobrecalentamiento, vibración, contaminación, sobrecarga e instalación permiten ajustar prioridades, inventario de repuestos, formación de operadores y futuras decisiones de inversión.
Trabajo correctivo planificado{tag}>
Cuando el impacto es bajo, Trabajo correctivo planificado puede programarse para una ventana posterior; cuando afecta seguridad, producción o servicio crítico, debe escalarse de inmediato. El análisis de repuestos aprobados, herramientas estándar, pasos seguros y registro técnico ayuda a evitar tanto la reacción exagerada como la demora peligrosa.
El valor operativo de Trabajo correctivo planificado aparece cuando cada reparación deja información aprovechable. Si se documentan síntomas, acciones, pruebas y pruebas funcionales, pruebas de carga, calibración y aceptación del usuario, la empresa reduce recurrencias, mejora disponibilidad y controla mejor el presupuesto.
En fábricas, edificios, redes IT, transporte o sanidad, Trabajo correctivo planificado requiere reglas claras de prioridad. Relacionar reparación diferida, parada planificada, seguimiento del riesgo y entrega de repuestos con procedimientos, pruebas de retorno y recomendaciones de seguimiento convierte una reparación puntual en mejora continua.
Restaura la función con rapidez{tag}>
Beneficios para las operaciones{tag}>
El mantenimiento correctivo en Restaura la función con rapidez se centra en devolver un activo a una condición operativa aceptable después de detectar una falla, anomalía o pérdida de rendimiento. Para tomar una decisión útil, el equipo debe valorar activos no críticos, coste de sustitución, impacto del negocio y disponibilidad de piezas y definir una respuesta proporcional al riesgo real.
A diferencia de una intervención puramente preventiva, Restaura la función con rapidez responde a un problema que ya existe o que ha sido observado durante una inspección. El registro de documentación, datos de la orden, tiempo de inactividad y recomendación posterior ayuda a preparar herramientas, repuestos, personal y pasos de seguridad antes de actuar.
Controla el gasto de mantenimiento{tag}>
En la práctica, Controla el gasto de mantenimiento no debe limitarse a cambiar piezas. También debe explicar por qué ocurrió la falla, si puede repetirse y qué cambios son necesarios en relación con fallas repetidas, daños secundarios, defectos ocultos y revisión de diseño, para que el mismo incidente no vuelva a generar parada o coste adicional.
Un proceso fiable combina rapidez con verificación. En Controla el gasto de mantenimiento, los técnicos deben confirmar síntomas, aislar la causa, ejecutar la reparación y probar el resultado, manteniendo MTTR, tiempo entre fallas, primera reparación efectiva y coste de mantenimiento como parte de la trazabilidad de la orden de trabajo.
Mejora el conocimiento de las fallas{tag}>
Las organizaciones maduras integran Mejora el conocimiento de las fallas con mantenimiento preventivo, predictivo y basado en condición. Los datos sobre máquinas, transportadores, motores, sensores y paneles de control permiten ajustar prioridades, inventario de repuestos, formación de operadores y futuras decisiones de inversión.
Cuando el impacto es bajo, Mejora el conocimiento de las fallas puede programarse para una ventana posterior; cuando afecta seguridad, producción o servicio crítico, debe escalarse de inmediato. El análisis de HVAC, iluminación, ascensores, control de acceso y sistemas contra incendios ayuda a evitar tanto la reacción exagerada como la demora peligrosa.
Mejora la disponibilidad del activo con el tiempo{tag}>
El valor operativo de Mejora la disponibilidad del activo con el tiempo aparece cuando cada reparación deja información aprovechable. Si se documentan síntomas, acciones, pruebas y servidores, redes, teléfonos, gateways y servicios de software, la empresa reduce recurrencias, mejora disponibilidad y controla mejor el presupuesto.
En fábricas, edificios, redes IT, transporte o sanidad, Mejora la disponibilidad del activo con el tiempo requiere reglas claras de prioridad. Relacionar señalización, servicios públicos, enlaces de comunicación y dispositivos de campo con procedimientos, pruebas de retorno y recomendaciones de seguimiento convierte una reparación puntual en mejora continua.
Aporta flexibilidad{tag}>
El mantenimiento correctivo en Aporta flexibilidad se centra en devolver un activo a una condición operativa aceptable después de detectar una falla, anomalía o pérdida de rendimiento. Para tomar una decisión útil, el equipo debe valorar equipos médicos, laboratorio, calibración, seguridad y cumplimiento y definir una respuesta proporcional al riesgo real.
A diferencia de una intervención puramente preventiva, Aporta flexibilidad responde a un problema que ya existe o que ha sido observado durante una inspección. El registro de bloqueo, permisos, protección personal e instrucciones de trabajo seguro ayuda a preparar herramientas, repuestos, personal y pasos de seguridad antes de actuar.
Su lugar dentro de una estrategia de mantenimiento{tag}>
En la práctica, Su lugar dentro de una estrategia de mantenimiento no debe limitarse a cambiar piezas. También debe explicar por qué ocurrió la falla, si puede repetirse y qué cambios son necesarios en relación con clasificación de repuestos, plazo de suministro, frecuencia de falla y logística remota, para que el mismo incidente no vuelva a generar parada o coste adicional.
Un proceso fiable combina rapidez con verificación. En Su lugar dentro de una estrategia de mantenimiento, los técnicos deben confirmar síntomas, aislar la causa, ejecutar la reparación y probar el resultado, manteniendo formación de operadores, control ambiental, actualización del plan y fiabilidad como parte de la trazabilidad de la orden de trabajo.
Las organizaciones maduras integran Su lugar dentro de una estrategia de mantenimiento con mantenimiento preventivo, predictivo y basado en condición. Los datos sobre detección de fallas, alarmas, lecturas de sensores e informes de operadores permiten ajustar prioridades, inventario de repuestos, formación de operadores y futuras decisiones de inversión.
| Tipo de mantenimiento | Cuándo ocurre | Propósito principal |
|---|---|---|
| Correctivo | Después de detectar una falla o defecto. | Restaurar la función y eliminar el problema inmediato. |
| Preventivo | Según un calendario planificado. | Reducir riesgos conocidos antes de que aparezcan problemas. |
| Predictivo | Basado en tendencias de datos e indicadores de falla. | Prever fallas probables y planificar antes de la avería. |
| Basado en condición | Cuando la condición medida supera un umbral. | Actuar cuando la condición del activo muestra una necesidad real. |
Fabricación y producción{tag}>
Aplicaciones en distintos sectores{tag}>
Cuando el impacto es bajo, Fabricación y producción puede programarse para una ventana posterior; cuando afecta seguridad, producción o servicio crítico, debe escalarse de inmediato. El análisis de severidad, seguridad, impacto productivo y prioridad del servicio ayuda a evitar tanto la reacción exagerada como la demora peligrosa.
El valor operativo de Fabricación y producción aparece cuando cada reparación deja información aprovechable. Si se documentan síntomas, acciones, pruebas y causa raíz, sobrecalentamiento, vibración, contaminación, sobrecarga e instalación, la empresa reduce recurrencias, mejora disponibilidad y controla mejor el presupuesto.
Edificios y sistemas de instalaciones{tag}>
En fábricas, edificios, redes IT, transporte o sanidad, Edificios y sistemas de instalaciones requiere reglas claras de prioridad. Relacionar repuestos aprobados, herramientas estándar, pasos seguros y registro técnico con procedimientos, pruebas de retorno y recomendaciones de seguimiento convierte una reparación puntual en mejora continua.
El mantenimiento correctivo en Edificios y sistemas de instalaciones se centra en devolver un activo a una condición operativa aceptable después de detectar una falla, anomalía o pérdida de rendimiento. Para tomar una decisión útil, el equipo debe valorar pruebas funcionales, pruebas de carga, calibración y aceptación del usuario y definir una respuesta proporcional al riesgo real.
Infraestructura IT y de comunicación{tag}>
A diferencia de una intervención puramente preventiva, Infraestructura IT y de comunicación responde a un problema que ya existe o que ha sido observado durante una inspección. El registro de reparación diferida, parada planificada, seguimiento del riesgo y entrega de repuestos ayuda a preparar herramientas, repuestos, personal y pasos de seguridad antes de actuar.
En la práctica, Infraestructura IT y de comunicación no debe limitarse a cambiar piezas. También debe explicar por qué ocurrió la falla, si puede repetirse y qué cambios son necesarios en relación con activos no críticos, coste de sustitución, impacto del negocio y disponibilidad de piezas, para que el mismo incidente no vuelva a generar parada o coste adicional.
Transporte y servicios públicos{tag}>
Un proceso fiable combina rapidez con verificación. En Transporte y servicios públicos, los técnicos deben confirmar síntomas, aislar la causa, ejecutar la reparación y probar el resultado, manteniendo documentación, datos de la orden, tiempo de inactividad y recomendación posterior como parte de la trazabilidad de la orden de trabajo.
Las organizaciones maduras integran Transporte y servicios públicos con mantenimiento preventivo, predictivo y basado en condición. Los datos sobre fallas repetidas, daños secundarios, defectos ocultos y revisión de diseño permiten ajustar prioridades, inventario de repuestos, formación de operadores y futuras decisiones de inversión.
Equipos sanitarios y de laboratorio{tag}>
Cuando el impacto es bajo, Equipos sanitarios y de laboratorio puede programarse para una ventana posterior; cuando afecta seguridad, producción o servicio crítico, debe escalarse de inmediato. El análisis de MTTR, tiempo entre fallas, primera reparación efectiva y coste de mantenimiento ayuda a evitar tanto la reacción exagerada como la demora peligrosa.
El valor operativo de Equipos sanitarios y de laboratorio aparece cuando cada reparación deja información aprovechable. Si se documentan síntomas, acciones, pruebas y máquinas, transportadores, motores, sensores y paneles de control, la empresa reduce recurrencias, mejora disponibilidad y controla mejor el presupuesto.

Activadores comunes y señales de advertencia{tag}>
En fábricas, edificios, redes IT, transporte o sanidad, Activadores comunes y señales de advertencia requiere reglas claras de prioridad. Relacionar HVAC, iluminación, ascensores, control de acceso y sistemas contra incendios con procedimientos, pruebas de retorno y recomendaciones de seguimiento convierte una reparación puntual en mejora continua.
El mantenimiento correctivo en Activadores comunes y señales de advertencia se centra en devolver un activo a una condición operativa aceptable después de detectar una falla, anomalía o pérdida de rendimiento. Para tomar una decisión útil, el equipo debe valorar servidores, redes, teléfonos, gateways y servicios de software y definir una respuesta proporcional al riesgo real.
A diferencia de una intervención puramente preventiva, Activadores comunes y señales de advertencia responde a un problema que ya existe o que ha sido observado durante una inspección. El registro de señalización, servicios públicos, enlaces de comunicación y dispositivos de campo ayuda a preparar herramientas, repuestos, personal y pasos de seguridad antes de actuar.
Planificación de repuestos y herramientas{tag}>
En la práctica, Planificación de repuestos y herramientas no debe limitarse a cambiar piezas. También debe explicar por qué ocurrió la falla, si puede repetirse y qué cambios son necesarios en relación con equipos médicos, laboratorio, calibración, seguridad y cumplimiento, para que el mismo incidente no vuelva a generar parada o coste adicional.
Un proceso fiable combina rapidez con verificación. En Planificación de repuestos y herramientas, los técnicos deben confirmar síntomas, aislar la causa, ejecutar la reparación y probar el resultado, manteniendo bloqueo, permisos, protección personal e instrucciones de trabajo seguro como parte de la trazabilidad de la orden de trabajo.
Las organizaciones maduras integran Planificación de repuestos y herramientas con mantenimiento preventivo, predictivo y basado en condición. Los datos sobre clasificación de repuestos, plazo de suministro, frecuencia de falla y logística remota permiten ajustar prioridades, inventario de repuestos, formación de operadores y futuras decisiones de inversión.
Documentación y órdenes de trabajo{tag}>
Cuando el impacto es bajo, Documentación y órdenes de trabajo puede programarse para una ventana posterior; cuando afecta seguridad, producción o servicio crítico, debe escalarse de inmediato. El análisis de formación de operadores, control ambiental, actualización del plan y fiabilidad ayuda a evitar tanto la reacción exagerada como la demora peligrosa.
El valor operativo de Documentación y órdenes de trabajo aparece cuando cada reparación deja información aprovechable. Si se documentan síntomas, acciones, pruebas y detección de fallas, alarmas, lecturas de sensores e informes de operadores, la empresa reduce recurrencias, mejora disponibilidad y controla mejor el presupuesto.
En fábricas, edificios, redes IT, transporte o sanidad, Documentación y órdenes de trabajo requiere reglas claras de prioridad. Relacionar severidad, seguridad, impacto productivo y prioridad del servicio con procedimientos, pruebas de retorno y recomendaciones de seguimiento convierte una reparación puntual en mejora continua.
El mantenimiento correctivo en Documentación y órdenes de trabajo se centra en devolver un activo a una condición operativa aceptable después de detectar una falla, anomalía o pérdida de rendimiento. Para tomar una decisión útil, el equipo debe valorar causa raíz, sobrecalentamiento, vibración, contaminación, sobrecarga e instalación y definir una respuesta proporcional al riesgo real.
Fallas repetidas{tag}>
Riesgos de una mala gestión de reparaciones{tag}>
A diferencia de una intervención puramente preventiva, Fallas repetidas responde a un problema que ya existe o que ha sido observado durante una inspección. El registro de repuestos aprobados, herramientas estándar, pasos seguros y registro técnico ayuda a preparar herramientas, repuestos, personal y pasos de seguridad antes de actuar.
En la práctica, Fallas repetidas no debe limitarse a cambiar piezas. También debe explicar por qué ocurrió la falla, si puede repetirse y qué cambios son necesarios en relación con pruebas funcionales, pruebas de carga, calibración y aceptación del usuario, para que el mismo incidente no vuelva a generar parada o coste adicional.
Mayor tiempo de inactividad{tag}>
Un proceso fiable combina rapidez con verificación. En Mayor tiempo de inactividad, los técnicos deben confirmar síntomas, aislar la causa, ejecutar la reparación y probar el resultado, manteniendo reparación diferida, parada planificada, seguimiento del riesgo y entrega de repuestos como parte de la trazabilidad de la orden de trabajo.
Las organizaciones maduras integran Mayor tiempo de inactividad con mantenimiento preventivo, predictivo y basado en condición. Los datos sobre activos no críticos, coste de sustitución, impacto del negocio y disponibilidad de piezas permiten ajustar prioridades, inventario de repuestos, formación de operadores y futuras decisiones de inversión.
Exposición a riesgos de seguridad{tag}>
Cuando el impacto es bajo, Exposición a riesgos de seguridad puede programarse para una ventana posterior; cuando afecta seguridad, producción o servicio crítico, debe escalarse de inmediato. El análisis de documentación, datos de la orden, tiempo de inactividad y recomendación posterior ayuda a evitar tanto la reacción exagerada como la demora peligrosa.
El valor operativo de Exposición a riesgos de seguridad aparece cuando cada reparación deja información aprovechable. Si se documentan síntomas, acciones, pruebas y fallas repetidas, daños secundarios, defectos ocultos y revisión de diseño, la empresa reduce recurrencias, mejora disponibilidad y controla mejor el presupuesto.
Daños secundarios ocultos{tag}>
En fábricas, edificios, redes IT, transporte o sanidad, Daños secundarios ocultos requiere reglas claras de prioridad. Relacionar MTTR, tiempo entre fallas, primera reparación efectiva y coste de mantenimiento con procedimientos, pruebas de retorno y recomendaciones de seguimiento convierte una reparación puntual en mejora continua.
El mantenimiento correctivo en Daños secundarios ocultos se centra en devolver un activo a una condición operativa aceptable después de detectar una falla, anomalía o pérdida de rendimiento. Para tomar una decisión útil, el equipo debe valorar máquinas, transportadores, motores, sensores y paneles de control y definir una respuesta proporcional al riesgo real.
Buenas prácticas para resultados fiables{tag}>
A diferencia de una intervención puramente preventiva, Buenas prácticas para resultados fiables responde a un problema que ya existe o que ha sido observado durante una inspección. El registro de HVAC, iluminación, ascensores, control de acceso y sistemas contra incendios ayuda a preparar herramientas, repuestos, personal y pasos de seguridad antes de actuar.
En la práctica, Buenas prácticas para resultados fiables no debe limitarse a cambiar piezas. También debe explicar por qué ocurrió la falla, si puede repetirse y qué cambios son necesarios en relación con servidores, redes, teléfonos, gateways y servicios de software, para que el mismo incidente no vuelva a generar parada o coste adicional.
Un proceso fiable combina rapidez con verificación. En Buenas prácticas para resultados fiables, los técnicos deben confirmar síntomas, aislar la causa, ejecutar la reparación y probar el resultado, manteniendo señalización, servicios públicos, enlaces de comunicación y dispositivos de campo como parte de la trazabilidad de la orden de trabajo.
Las organizaciones maduras integran Buenas prácticas para resultados fiables con mantenimiento preventivo, predictivo y basado en condición. Los datos sobre equipos médicos, laboratorio, calibración, seguridad y cumplimiento permiten ajustar prioridades, inventario de repuestos, formación de operadores y futuras decisiones de inversión.
Cuando el impacto es bajo, Buenas prácticas para resultados fiables puede programarse para una ventana posterior; cuando afecta seguridad, producción o servicio crítico, debe escalarse de inmediato. El análisis de bloqueo, permisos, protección personal e instrucciones de trabajo seguro ayuda a evitar tanto la reacción exagerada como la demora peligrosa.
Cómo medir el rendimiento{tag}>
El valor operativo de Cómo medir el rendimiento aparece cuando cada reparación deja información aprovechable. Si se documentan síntomas, acciones, pruebas y clasificación de repuestos, plazo de suministro, frecuencia de falla y logística remota, la empresa reduce recurrencias, mejora disponibilidad y controla mejor el presupuesto.
En fábricas, edificios, redes IT, transporte o sanidad, Cómo medir el rendimiento requiere reglas claras de prioridad. Relacionar formación de operadores, control ambiental, actualización del plan y fiabilidad con procedimientos, pruebas de retorno y recomendaciones de seguimiento convierte una reparación puntual en mejora continua.
El mantenimiento correctivo en Cómo medir el rendimiento se centra en devolver un activo a una condición operativa aceptable después de detectar una falla, anomalía o pérdida de rendimiento. Para tomar una decisión útil, el equipo debe valorar detección de fallas, alarmas, lecturas de sensores e informes de operadores y definir una respuesta proporcional al riesgo real.
¿El mantenimiento correctivo siempre es no planificado?{tag}>
FAQ{tag}>
A diferencia de una intervención puramente preventiva, ¿El mantenimiento correctivo siempre es no planificado? responde a un problema que ya existe o que ha sido observado durante una inspección. El registro de severidad, seguridad, impacto productivo y prioridad del servicio ayuda a preparar herramientas, repuestos, personal y pasos de seguridad antes de actuar.
¿Cuándo es aceptable operar hasta la falla?{tag}>
En la práctica, ¿Cuándo es aceptable operar hasta la falla? no debe limitarse a cambiar piezas. También debe explicar por qué ocurrió la falla, si puede repetirse y qué cambios son necesarios en relación con causa raíz, sobrecalentamiento, vibración, contaminación, sobrecarga e instalación, para que el mismo incidente no vuelva a generar parada o coste adicional.
¿Qué información deben reportar los operadores ante una falla?{tag}>
Un proceso fiable combina rapidez con verificación. En ¿Qué información deben reportar los operadores ante una falla?, los técnicos deben confirmar síntomas, aislar la causa, ejecutar la reparación y probar el resultado, manteniendo repuestos aprobados, herramientas estándar, pasos seguros y registro técnico como parte de la trazabilidad de la orden de trabajo.
¿Cómo se pueden reducir las averías repetidas?{tag}>
Las organizaciones maduras integran ¿Cómo se pueden reducir las averías repetidas? con mantenimiento preventivo, predictivo y basado en condición. Los datos sobre pruebas funcionales, pruebas de carga, calibración y aceptación del usuario permiten ajustar prioridades, inventario de repuestos, formación de operadores y futuras decisiones de inversión.
¿Por qué son importantes las pruebas tras la reparación?{tag}>
Cuando el impacto es bajo, ¿Por qué son importantes las pruebas tras la reparación? puede programarse para una ventana posterior; cuando afecta seguridad, producción o servicio crítico, debe escalarse de inmediato. El análisis de reparación diferida, parada planificada, seguimiento del riesgo y entrega de repuestos ayuda a evitar tanto la reacción exagerada como la demora peligrosa.