

Imagine que un sitio remoto pierde la conexión con la plataforma central mientras los operadores aún necesitan llamarse entre sí, contactar números de emergencia y mantener en marcha la comunicación esencial.
Aquí es donde la supervivencia local aporta valor. No está diseñada para condiciones ideales de red, sino para el momento en que la ruta principal se interrumpe, el enlace WAN es inestable, el servidor central no responde o el sitio no puede acceder al servicio en la nube.
Mantener activa la comunicación esencial durante el aislamiento de red
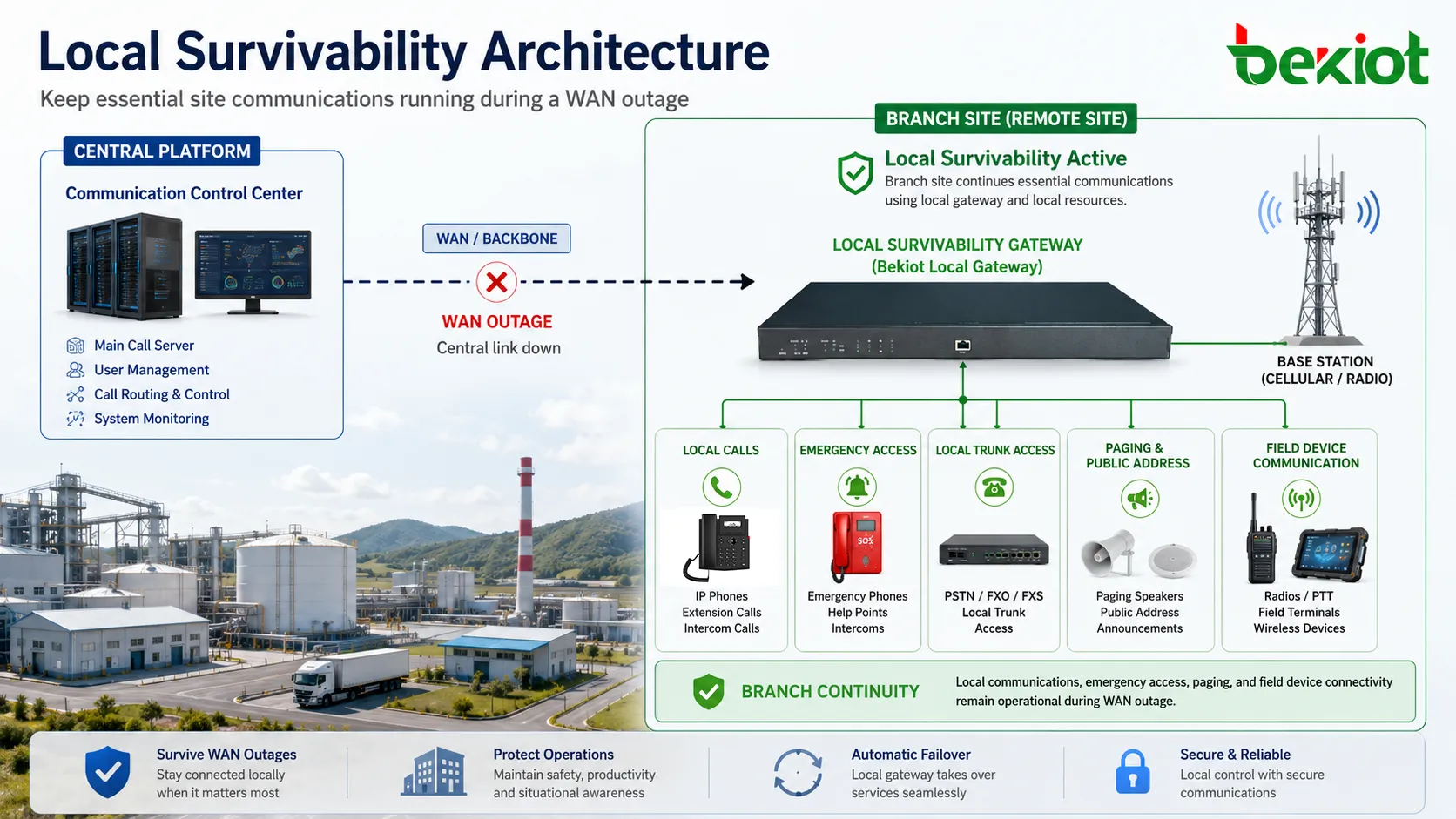
La supervivencia local es la capacidad de una sucursal, estación de campo, instalación industrial o nodo remoto de comunicación para seguir ejecutando servicios básicos aunque se interrumpa la conexión con el sistema central. En redes de comunicación, esto significa que los usuarios locales todavía pueden llamarse entre sí, acceder a números de emergencia predefinidos, utilizar troncales locales o conservar servicios críticos de voz sin esperar a que se recupere la plataforma central.
La ventaja práctica es la continuidad. Muchos sistemas distribuidos dependen de servidores centrales para registro, enrutamiento, control de políticas, grabación o gestión de usuarios. Este modelo centralizado es eficiente durante la operación normal, pero también crea dependencia. Si falla el enlace WAN, los dispositivos del sitio remoto pueden perder acceso al servidor principal de llamadas, PBX en la nube, plataforma de despacho o centro de control de comunicaciones. Sin supervivencia local, el sitio puede quedar operativamente aislado.
Con supervivencia local, una pasarela, servidor, controlador o nodo de servicio local puede asumir temporalmente funciones seleccionadas de comunicación. No reemplaza necesariamente a la plataforma central por completo. En cambio, preserva los servicios más importantes para la operación local: llamadas internas, comunicación de emergencia, enrutamiento local, troncales de respaldo, registro alternativo de dispositivos y, en algunos casos, funciones limitadas de despacho o anuncios.
Esta capacidad es especialmente importante en plantas industriales, estaciones de transporte, instalaciones energéticas, campus, parques logísticos, minas, túneles, aeropuertos y sitios de servicio público. Estos entornos no pueden detener la comunicación solo porque un enlace troncal esté caído. La supervivencia local ofrece un estado de respaldo controlado en lugar de una interrupción total del servicio.
Reducir la dependencia de una única plataforma central
Las plataformas centralizadas simplifican la administración, pero pueden convertirse en un único punto de dependencia si los sitios remotos no tienen respaldo local. En una arquitectura normal, el registro de terminales, el enrutamiento de llamadas, la autenticación, la traducción de números y las políticas de servicio pueden gestionarse en el sistema central. Si toda comunicación debe pasar por esa plataforma, un fallo de enlace puede afectar incluso llamadas locales sencillas entre dos dispositivos del mismo edificio.
La supervivencia local cambia este modelo. Permite que funciones locales seleccionadas permanezcan disponibles bajo condiciones definidas. Por ejemplo, las extensiones locales pueden volver a registrarse en una pasarela superviviente, o la pasarela puede conservar un plan de marcación en caché para llamadas locales. Los números de emergencia pueden enrutarse por troncales locales. Oficinas de seguridad, equipos de mantenimiento, salas de control de producción y terminales de campo pueden seguir comunicándose dentro del sitio aunque el servidor principal no sea accesible.
Esto no significa descentralizarlo todo. Un buen diseño sigue usando administración centralizada durante la operación normal porque ofrece configuración unificada, monitoreo, control de políticas y mantenimiento más sencillo. La supervivencia añade un segundo estado operativo. El sistema trabaja de forma centralizada cuando la red está sana y pasa a control local solo cuando falla la ruta central.
La ventaja es el equilibrio. Las organizaciones obtienen los beneficios de una arquitectura centralizada sin aceptar la pérdida total del servicio durante el aislamiento de red. Esto es particularmente valioso en despliegues multisede, donde cada sucursal, estación, planta o nodo de campo tiene responsabilidades operativas propias.
Mantener las llamadas de emergencia cuando falla la ruta principal
Las llamadas de emergencia son una de las razones más importantes para desplegar supervivencia local. En muchos entornos, los usuarios pueden necesitar contactar seguridad, bomberos, soporte médico, operadores de sala de control o servicios locales de emergencia precisamente durante el tipo de incidente que también interrumpe la conectividad. Si el sistema depende por completo de una plataforma central, la llamada de emergencia puede fallar cuando más se necesita.
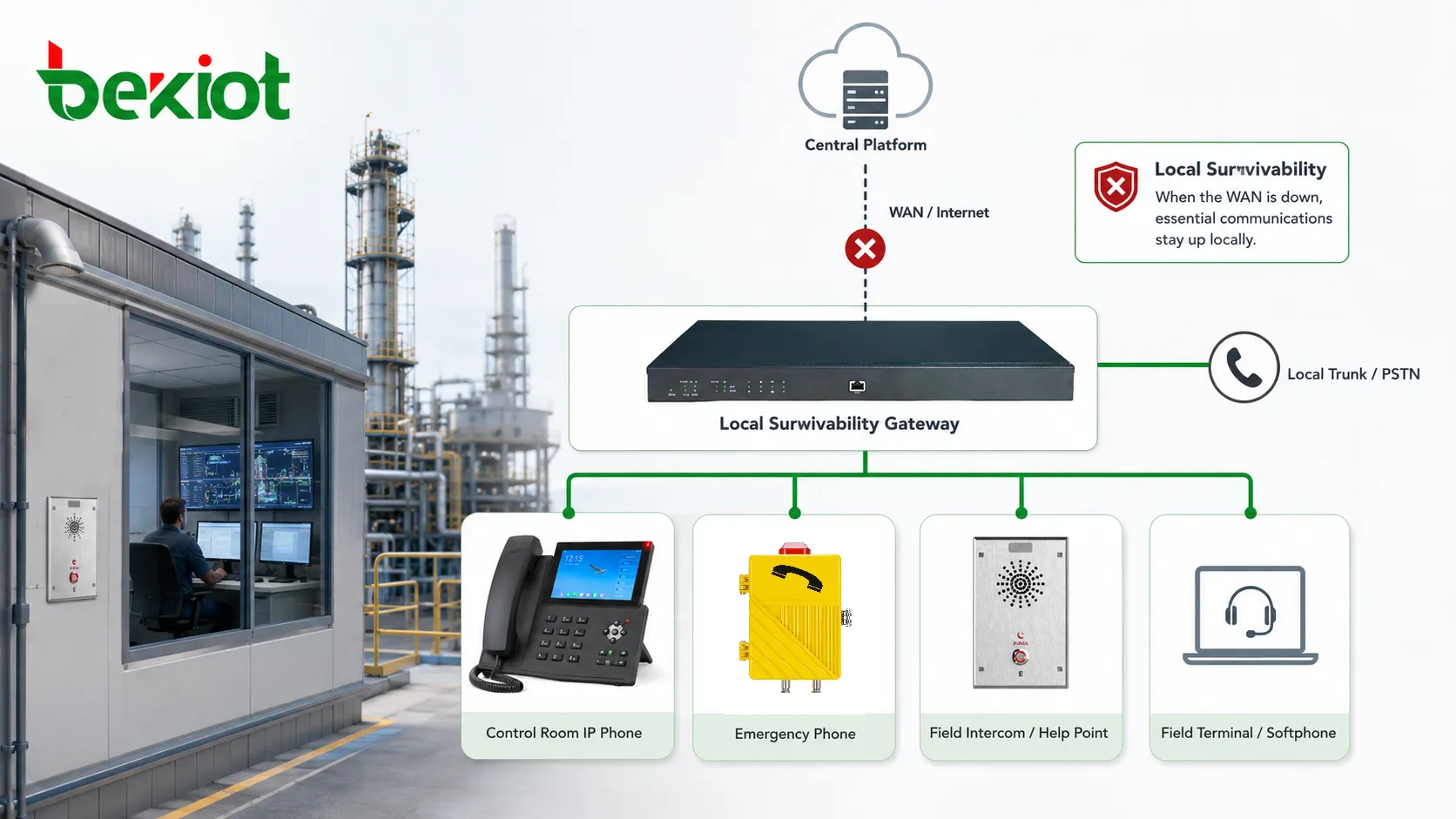
Un nodo local superviviente puede conservar el enrutamiento de emergencia mediante números locales, líneas analógicas, troncales SIP, pasarelas de radio o terminales de respuesta predefinidos. El diseño depende del sitio, pero el principio es el mismo: la comunicación de emergencia debe tener una ruta local que no dependa totalmente de infraestructura distante. Esto es crucial para sitios industriales remotos, estaciones de transporte, instalaciones subterráneas, plataformas offshore y entornos de seguridad pública.
La supervivencia local también ayuda a que el comportamiento de emergencia sea predecible. Cuando la plataforma central está caída, los usuarios no deberían adivinar qué números funcionan. El sistema debe definir qué números de emergencia siguen disponibles, adónde se enrutan, cómo se alerta a los operadores y si el respaldo es automático. Un comportamiento claro bajo fallo vale más que un sistema complejo que solo funciona en condiciones normales.
En la planificación del despliegue, el enrutamiento de emergencia debe probarse por separado de las llamadas ordinarias. Los ingenieros deben confirmar si las llamadas conectan durante una falla WAN simulada, si se conserva la ubicación o identidad del dispositivo cuando sea necesario, si los operadores locales reciben la llamada y si las troncales de respaldo funcionan correctamente. La supervivencia solo tiene sentido si la ruta alternativa se ha verificado antes de un incidente real.
Respaldar operaciones locales en sitios industriales y remotos
Algunos sitios no pueden pausar sus operaciones porque la red central no esté disponible. Una línea de producción puede seguir necesitando coordinación entre sala de control y personal de campo. Una estación ferroviaria puede requerir comunicación interna entre andén, seguridad y mantenimiento. Una mina puede necesitar contacto de voz entre puntos subterráneos y supervisión local. Una subestación eléctrica puede necesitar comunicación entre operadores y técnicos. Son flujos locales, y muchos deben permanecer disponibles durante la desconexión central.
La supervivencia local apoya esto manteniendo la comunicación cerca de las personas y dispositivos que la necesitan. En lugar de enrutar cada llamada por un centro de datos remoto o una plataforma en la nube, las llamadas locales seleccionadas pueden gestionarse dentro del sitio. Esto reduce la dependencia de trayectos de red largos y da a la instalación una capacidad operativa básica bajo condiciones degradadas.
En entornos industriales, el valor no es solo continuidad técnica. También respalda la seguridad y la disciplina de producción. Los operadores pueden reportar fallos, los equipos de mantenimiento coordinar reparaciones, el personal de seguridad comunicarse con puertas o rondas, y los teléfonos de emergencia alcanzar puestos locales de respuesta. El sitio puede operar en modo reducido, pero no queda en silencio.
Esto resulta especialmente útil cuando la reparación WAN puede tardar. Sitios remotos, gabinetes exteriores, rutas subterráneas y enlaces arrendados no siempre se restauran de inmediato. Una capa de supervivencia local gana tiempo para los equipos de reparación mientras mantiene la coordinación interna esencial.
Mejorar la resiliencia sin complicar toda la red
La resiliencia suele asociarse con redundancia completa: servidores duplicados, enlaces duplicados, centros de datos de respaldo, múltiples operadores y sistemas paralelos. Estos diseños pueden ser necesarios en redes grandes o críticas, pero también pueden ser costosos y complejos. La supervivencia local ofrece un método enfocado de resiliencia al proteger las funciones de comunicación más importantes del sitio sin duplicar toda la plataforma central en cada ubicación.
Esto la hace atractiva para organizaciones distribuidas. Una sucursal no siempre necesita un servidor completo con todas las funciones avanzadas. Una estación o planta puede no requerir duplicación total de plataforma. Lo que necesita es mantener llamadas básicas, enrutamiento de emergencia y acceso a servicios locales durante la desconexión. La supervivencia responde a ese requisito práctico.
La arquitectura puede escalarse según el riesgo. Una sucursal de bajo riesgo puede requerir solo llamadas locales de emergencia y respaldo de extensiones internas. Una instalación industrial crítica puede necesitar registro local, troncales locales, teléfonos de emergencia, acceso a megafonía y respaldo de consola. Una red de transporte puede requerir continuidad a nivel de estación y reconexión controlada al centro de mando cuando regrese el enlace.
Al ajustar la profundidad de supervivencia a la importancia del sitio, las organizaciones mejoran la resiliencia sin desplegar infraestructura innecesariamente pesada en todas partes. El objetivo no es hacer que cada sitio sea totalmente independiente, sino asegurar que conserve las funciones de comunicación que realmente necesita durante condiciones anormales de red.
Acortar el tiempo de recuperación tras una interrupción
La supervivencia local puede reducir el impacto operativo de las caídas porque los servicios no colapsan por completo durante el fallo. Cuando se restaura la ruta central, el sistema puede volver del modo de respaldo local a la operación centralizada. Esta transición puede ser automática o controlada, según el diseño de la plataforma y los requisitos del proyecto.
Sin supervivencia, una caída WAN puede provocar muchos problemas secundarios. Los usuarios intentan llamadas fallidas repetidamente, los operadores reciben quejas, el enrutamiento de emergencia se vuelve incierto y mantenimiento debe explicar por qué dispositivos cercanos no pueden comunicarse. Recuperar no es solo restaurar el enlace; también es restablecer la confianza del usuario y el orden del servicio.
Con supervivencia, el sitio sigue funcionando en un modo limitado pero organizado. Los usuarios locales pueden notar que algunos servicios centrales no están disponibles, pero la comunicación esencial continúa. Cuando regresa la plataforma principal, registros, rutas y políticas pueden sincronizarse de nuevo con el estado normal. Esto hace que la interrupción sea más manejable y menos disruptiva.
La planificación de recuperación debe incluir qué ocurre después del fallo. El sistema debe evitar registros duplicados, confusión de rutas, estados inconsistentes o restauración tardía. Los equipos de mantenimiento deben ver cuándo el sitio entró en modo superviviente, qué llamadas se gestionaron localmente y cuándo se reanudó el modo normal. Estos registros verifican que la conmutación se comportó correctamente.
Preservar la experiencia del usuario en condiciones degradadas
Los usuarios no suelen pensar en servidores de llamadas, enrutamiento WAN, registro SIP o respaldo de troncales. Esperan que el teléfono, terminal de emergencia, intercomunicador o consola funcione cuando lo necesitan. La supervivencia local ayuda a preservar esa experiencia manteniendo disponibles las acciones de comunicación más familiares aunque la red amplia esté afectada.
Por ejemplo, un usuario aún puede marcar una extensión local, contactar al puesto de seguridad, llamar a la sala de control o activar un punto de emergencia. El sistema puede estar en modo de respaldo, pero la experiencia sigue siendo lo bastante cercana a la normalidad para las tareas críticas. Esto reduce la confusión y evita que las personas abandonen los procedimientos oficiales por métodos informales.
Preservar la experiencia también reduce la carga de formación. Si el comportamiento de respaldo sigue patrones de marcación y rutas de respuesta conocidas, los usuarios no necesitan memorizar un método especial para fallas de red. El sistema debe adaptarse al fallo, no obligar a cada usuario a cambiar de comportamiento durante un momento de estrés.
Sin embargo, no todas las funciones pueden o deben permanecer disponibles localmente. Servicios avanzados como directorios centralizados, grabación remota, conferencias entre sitios, buzón de voz en la nube o enrutamiento global pueden no estar disponibles durante el aislamiento. Un buen despliegue define claramente qué funciones están garantizadas localmente y cuáles dependen del sistema central.
Diseñar reglas de conmutación en las que los operadores puedan confiar
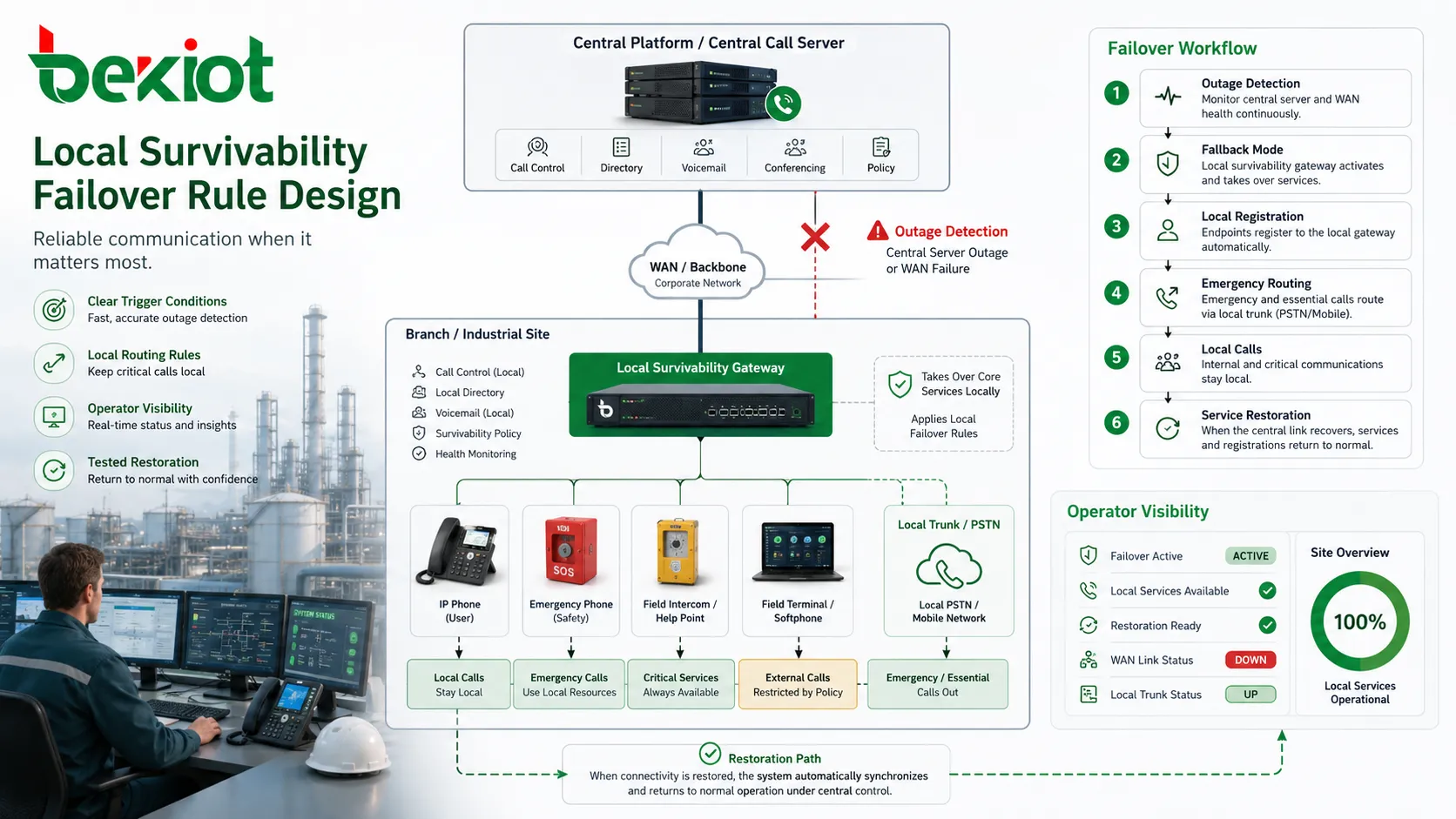
La supervivencia depende de reglas. El sistema debe saber cuándo entrar en modo de respaldo, qué servicios debe asumir localmente, qué números se enrutan por recursos locales y cuándo debe reanudarse la operación normal. Si estas reglas no son claras, la supervivencia puede crear confusión en lugar de estabilidad.
Las condiciones de activación son la primera cuestión de diseño. Un sitio puede entrar en modo superviviente cuando pierde contacto con el servidor central de llamadas, cuando falla el registro SIP, cuando la latencia WAN supera un umbral o cuando una troncal primaria no está disponible. El disparador debe ser lo bastante específico para evitar conmutaciones innecesarias y lo bastante sensible para responder antes de una falla generalizada.
Las reglas de enrutamiento son igual de importantes. Las llamadas locales deben permanecer locales cuando corresponda. Las llamadas de emergencia pueden enviarse a operadores locales o troncales de respaldo. Las llamadas externas pueden limitarse a números esenciales si la capacidad local es reducida. Las llamadas a otros sitios pueden bloquearse, reenrutarse o gestionarse por rutas alternativas. Los operadores deben entender estas reglas antes de que ocurra una interrupción.
La confianza proviene de pruebas y documentación. Si el personal no sabe qué significa el modo superviviente, puede pensar que el sistema está roto aunque funcione correctamente. Indicadores de estado claros, registros de mantenimiento, guías para operadores y pruebas periódicas de conmutación ayudan a construir confianza. Un diseño que nadie entiende no entrega todo su valor operativo.
Planificación para arquitecturas de sucursal y multisede
La supervivencia local debe planificarse según el rol del sitio. Una sucursal pequeña, una fábrica grande, una estación de transporte público, un edificio de campus, una instalación remota de servicios públicos y un punto de mando de emergencia no necesitan el mismo diseño. El primer paso es identificar qué funciones de comunicación deben seguir disponibles si la plataforma central no es accesible.
Las preguntas clave incluyen: ¿las extensiones locales deben seguir llamándose entre sí?, ¿las llamadas de emergencia van a un puesto local o a una troncal externa?, ¿se requiere acceso a la red pública?, ¿son necesarias megafonía o anuncios locales?, ¿deben seguir activos enlaces de radio o intercomunicación?, ¿cuántas llamadas simultáneas se necesitan?, ¿cuánto tiempo puede permanecer aislado el sitio? Estas preguntas definen el tamaño y función del nodo local.
También debe revisarse el diseño de red. Los dispositivos locales deben poder alcanzar el nodo de respaldo aunque la WAN esté caída. Por eso importan la conmutación local, VLAN, direccionamiento IP, comportamiento DHCP, dependencia DNS, respaldo eléctrico y ubicación de la pasarela. La supervivencia no funciona si los terminales locales pierden red o energía al mismo tiempo.
En despliegues multisede, la consistencia de configuración es importante. Cada sitio puede tener reglas locales propias, pero el diseño general debe seguir un patrón estándar cuando sea posible. Las plantillas reducen errores de ingeniería y facilitan mantenimiento. Las excepciones específicas pueden añadirse para ubicaciones de alto riesgo o propósito especial.
Valor de monitoreo operativo y mantenimiento
La supervivencia local no debe tratarse como una función que se configura una vez y se olvida. Su valor depende de que la ruta local de respaldo se mantenga sana. Los equipos de mantenimiento deben vigilar pasarelas locales, troncales de respaldo, comportamiento de registro, condiciones de energía y versiones de software. Un nodo apagado o mal configurado puede pasar inadvertido hasta una interrupción real.
Las pruebas regulares son esenciales. Los ingenieros deben simular de forma controlada la indisponibilidad del servidor central o la desconexión WAN y verificar si llamadas locales, llamadas de emergencia y rutas de respaldo se comportan como se espera. Estas pruebas deben documentarse, especialmente en entornos donde la seguridad o la continuidad son importantes.
El monitoreo también debe incluir registros de eventos. Cuando un sitio entra en modo superviviente, el sistema debe generar logs o alarmas para que mantenimiento entienda qué ocurrió. Si la conmutación se activa con frecuencia, puede haber inestabilidad WAN, problemas de alcance al servidor central, umbrales incorrectos o fallos de red local. La supervivencia protege el servicio, pero la activación frecuente indica un problema subyacente.
Después de una interrupción real, los registros ayudan a evaluar el desempeño. ¿Las llamadas locales siguieron disponibles? ¿Las llamadas de emergencia se enrutaron correctamente? ¿Los usuarios reportaron confusión? ¿El sistema volvió limpiamente al modo normal? Estas preguntas permiten refinar el diseño y mejorar la resiliencia futura.
Limitaciones comunes que deben entenderse antes del despliegue
La supervivencia local es valiosa, pero no equivale a duplicación completa del sistema. Algunos servicios centralizados pueden no estar disponibles durante el aislamiento. Según la arquitectura, esto puede incluir llamadas entre sitios, grabación centralizada, consulta de directorio en la nube, conferencias avanzadas, buzón de voz centralizado, colas globales o control remoto de administrador. Estas limitaciones deben explicarse antes del despliegue.
La capacidad también puede ser limitada. Un nodo de supervivencia puede soportar solo una cantidad definida de usuarios, llamadas, troncales o funciones. Si el sitio espera que todos los usuarios trabajen normalmente durante una caída WAN, el sistema de respaldo debe dimensionarse de esa forma. Si solo se requiere comunicación esencial y de emergencia, un diseño menor puede bastar.
Otra limitación es la consistencia de datos. Durante el respaldo, algunos registros de llamada, estados de dispositivos o cambios de configuración pueden almacenarse localmente y sincronizarse después, o quizá no estén plenamente disponibles para la plataforma central. El proyecto debe definir cómo se manejan los registros y qué información se requiere para auditoría o reportes.
Comprender estos límites no debilita el caso de la supervivencia. Hace el despliegue más realista. Los diseños más sólidos son los que definen claramente qué sobrevive localmente, qué depende del sistema central y cómo deben actuar usuarios y operadores durante la operación degradada.
Valor empresarial a largo plazo de la resiliencia por sitio
El valor a largo plazo de la supervivencia local proviene de reducir el riesgo operativo en entornos distribuidos. Una interrupción individual puede ser rara, pero su costo puede ser alto. La pérdida de comunicación puede retrasar mantenimiento, interrumpir producción, afectar servicio al cliente, debilitar la respuesta de emergencia o crear riesgos de seguridad. La supervivencia reduce la posibilidad de que un fallo de red se convierta en una falla operativa total.
Para organizaciones con muchos sitios, el valor aumenta aún más. Aunque cada sitio tenga problemas de conectividad solo ocasionalmente, el riesgo total de la red puede ser significativo. La capacidad de respaldo local crea un modelo operativo más resiliente, especialmente cuando los sitios están dispersos geográficamente o dependen de enlaces WAN arrendados.
La supervivencia también apoya la modernización. Las organizaciones pueden avanzar hacia plataformas centralizadas o en la nube y mantener protección local para sitios críticos. Esto reduce el riesgo de migración porque la nueva arquitectura no elimina toda independencia local. Combina eficiencia centralizada con continuidad a nivel de sitio.
En términos prácticos, la supervivencia local no es solo una función técnica. Es una medida de continuidad del negocio, una capa de apoyo a la seguridad y una forma de hacer que la arquitectura de comunicación distribuida tolere mejor los problemas reales de red.
Preguntas frecuentes
¿La supervivencia local solo es necesaria para grandes organizaciones?
No. Es útil para cualquier sitio donde la comunicación deba continuar durante una falla WAN o del servidor central. Sucursales pequeñas, instalaciones remotas, estaciones industriales, campus y sitios de transporte pueden necesitar respaldo local si el impacto de perder comunicación es alto.
¿La supervivencia local reemplaza la redundancia central?
No. La redundancia central protege la plataforma principal, mientras que la supervivencia local protege la comunicación del sitio cuando no puede alcanzar esa plataforma. Resuelven partes diferentes del problema de resiliencia y pueden usarse juntas.
¿Qué servicios suelen permanecer disponibles en modo superviviente?
Los servicios comunes incluyen llamadas entre extensiones locales, enrutamiento de emergencia, acceso a troncales locales, respaldo limitado de registro y rutas esenciales predefinidas. Los servicios centralizados avanzados solo permanecen disponibles si se diseñan específicamente para operación local.
¿Con qué frecuencia debe probarse la conmutación de supervivencia?
La frecuencia depende del nivel de riesgo, pero los sitios críticos deben probarla con regularidad y después de cambios importantes de red o configuración. La prueba debe verificar llamadas locales, rutas de emergencia, acceso a troncales, restauración y visibilidad del operador.
¿Cuál es el error de despliegue más común?
El error más común es habilitar una función de supervivencia sin diseñar todo el flujo de respaldo. El proyecto debe definir disparadores, enrutamiento local, comportamiento de emergencia, capacidad, expectativas de usuario, monitoreo y procedimientos de recuperación antes de depender de ella.







