

La detección de actividad de voz, normalmente abreviada como VAD, es una tecnología que determina si una señal de audio contiene habla humana o contenido no verbal, como silencio, ruido de fondo, música, sonidos de teclado, respiración o interferencias del entorno. Se utiliza ampliamente en sistemas VoIP, asistentes de voz con IA, reconocimiento de voz, plataformas de conferencia, grabación de llamadas, radios bidireccionales, aplicaciones móviles y dispositivos de comunicación integrados.
Qué significa la detección de actividad de voz en sistemas de audio
En un sistema de audio en tiempo real, el micrófono recibe sonido de forma continua. No todo sonido debe transmitirse, grabarse, procesarse o enviarse a un motor de reconocimiento de voz. La VAD ayuda al sistema a decidir cuándo una persona realmente está hablando y cuándo el flujo de audio puede tratarse como silencio o ruido de fondo.
Esta decisión puede parecer simple, pero es técnicamente importante. Una VAD mal ajustada puede cortar el inicio o el final de una frase, enviar demasiado ruido al servidor, generar activaciones falsas o hacer que el usuario sienta que el sistema responde tarde. Una VAD bien diseñada mejora la calidad de voz, ahorra ancho de banda, reduce el coste de cómputo y hace que la interacción por voz sea más natural.

Cómo funciona la detección de actividad de voz
Análisis de la señal de audio
La VAD comienza analizando tramas cortas de audio, normalmente medidas en milisegundos. Esto permite tomar decisiones rápidas sin esperar una grabación larga. Cada trama puede evaluarse por nivel de energía, distribución de frecuencias, variación de señal, tasa de cruces por cero, rasgos espectrales o probabilidad de habla calculada por aprendizaje automático.
Los métodos tradicionales de VAD suelen basarse en umbrales acústicos. Por ejemplo, si la energía del audio supera el piso de ruido, el sistema puede considerarlo habla. Los sistemas modernos pueden usar redes neuronales o modelos estadísticos para distinguir con mayor precisión la voz del ruido, especialmente en entornos con ventiladores, tráfico, maquinaria, música o varios hablantes.
Decisión entre habla y silencio
Después de analizar la trama de audio, el motor VAD decide si hay habla, silencio o una condición incierta. En sistemas reales, esta decisión se suaviza a lo largo del tiempo. Sin suavizado, el resultado puede cambiar demasiado rápido entre habla y silencio, provocando cortes de audio poco naturales.
La mayoría de despliegues reales usa parámetros como umbral de inicio, umbral de fin, duración mínima de habla, tiempo de silencio y tiempo de retención. El tiempo de retención hace que el sistema siga tratando el audio como habla durante un breve periodo después de que baja la energía detectada. Esto ayuda a evitar que la última sílaba se corte demasiado pronto.
Integración con el procesamiento de voz
La VAD rara vez se usa de forma aislada. Suele trabajar con supresión de ruido, cancelación de eco, control automático de ganancia, reconocimiento de voz, detección de palabra de activación, grabación de llamadas, compresión de audio y protocolos de comunicación en tiempo real. En un sistema de voz con IA, la VAD puede decidir cuándo iniciar el envío de audio al ASR y cuándo dejar de escuchar la frase del usuario.
En un sistema VoIP o de conferencia, la VAD puede reducir la transmisión de paquetes durante el silencio. En sistemas de grabación, puede marcar segmentos con habla activa para facilitar la reproducción y la búsqueda. En dispositivos integrados, puede reducir el uso de CPU y el consumo de batería al evitar procesamiento innecesario.
Características principales de la detección de actividad de voz
Detección de habla en tiempo real
La característica más importante de la VAD es la detección en tiempo real. El sistema debe reconocer el habla con rapidez suficiente para mantener una comunicación natural. Si el retardo es demasiado alto, el usuario puede notar una respuesta lenta, una conversación interrumpida o una interacción con IA retrasada.
La VAD en tiempo real es especialmente importante para asistentes de voz, atención al cliente con IA, comunicaciones de despacho, sistemas push-to-talk, videoconferencias e intercomunicadores manos libres. Estos escenarios requieren detección rápida del inicio del habla y detección estable del silencio al final de una frase.
Robustez frente al ruido
Los entornos reales de audio rara vez son silenciosos. Un sistema VAD puede tener que funcionar en oficinas, fábricas, vehículos, calles, hospitales, escuelas, almacenes, centros de llamadas, salas de control o sitios exteriores. El ruido de fondo dificulta la detección de habla, sobre todo cuando su nivel cambia con el tiempo.
Una VAD robusta frente al ruido puede adaptarse a condiciones sonoras cambiantes y reducir falsas activaciones. Por ejemplo, no debería interpretar la escritura en teclado, el aire acondicionado, impactos breves o conversaciones lejanas como la voz principal. Esto mejora la precisión y reduce transmisiones de audio innecesarias.
| Capacidad VAD | Qué hace | Por qué importa |
|---|---|---|
| Detección de inicio de habla | Identifica cuándo un usuario empieza a hablar | Ayuda al sistema a responder rápido y a no perder las primeras palabras |
| Detección de fin por silencio | Detecta cuándo el habla ha terminado | Permite que ASR, grabación o lógica de IA se detengan en el momento correcto |
| Filtrado de ruido | Reduce falsas detecciones por sonidos de fondo | Mejora la precisión en entornos reales |
| Control de retención | Mantiene el habla activa brevemente cuando baja la señal | Evita que el final de palabras o frases se corte |
| Análisis por tramas | Procesa continuamente segmentos cortos de audio | Soporta decisiones en tiempo real con baja latencia |
Sensibilidad configurable
Diferentes aplicaciones necesitan distinta sensibilidad de VAD. Un asistente de voz en una oficina tranquila puede usar un ajuste más sensible, mientras que un intercomunicador industrial necesita filtrado más fuerte para evitar activaciones por maquinaria. Ajustar la sensibilidad ayuda a equilibrar habla perdida y falsas detecciones.
Los parámetros habituales incluyen umbral de energía de audio, longitud mínima de habla, duración máxima de silencio, retardo de fin de habla, adaptación del piso de ruido y puntuación de confianza. Estos ajustes deben adaptarse a la distancia del micrófono, el ruido de fondo, el estilo de habla y los requisitos de respuesta del sistema.
Por qué importa la detección de actividad de voz
Mejor experiencia de usuario
En la interacción por voz, el tiempo es crítico. Si el sistema empieza a escuchar demasiado tarde, puede perder la primera palabra. Si se detiene demasiado pronto, puede cortar al usuario. Si espera demasiado después de que el usuario termina, el sistema parece lento. La VAD ayuda a crear turnos más fluidos entre humanos y máquinas.
Esto es especialmente importante en atención al cliente con IA, asistentes inteligentes, búsqueda por voz, dictado y control manos libres. Los usuarios esperan que el sistema entienda cuándo hablan sin pulsar botones ni iniciar o detener manualmente la grabación.
Menor ancho de banda y coste de procesamiento
La transmisión y el procesamiento de audio consumen ancho de banda, recursos de servidor y energía del dispositivo. Al enviar o procesar solo los segmentos con habla activa, la VAD reduce carga innecesaria. Esto es útil en plataformas de voz a gran escala, servicios ASR en la nube, conferencias y aplicaciones móviles.
En dispositivos de borde, la VAD también puede reducir el consumo eléctrico. El dispositivo puede mantener inactivos los módulos de procesamiento de mayor coste hasta detectar habla, algo valioso para productos con batería y terminales de voz integrados.
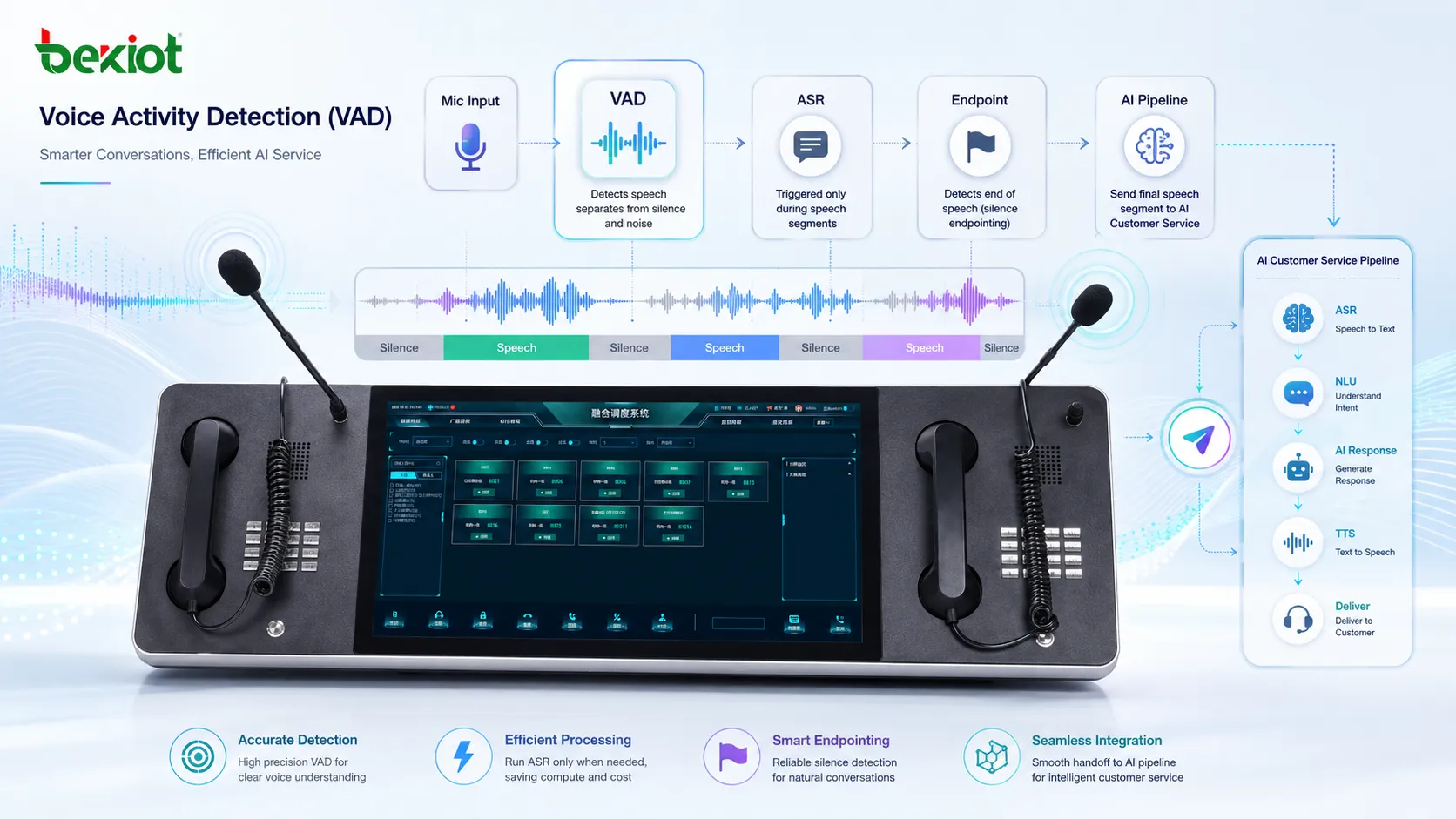
Grabaciones más limpias y revisión más fácil
En sistemas de grabación, la VAD ayuda a separar el habla útil de largos periodos de silencio. Esto hace que los archivos de audio sean más fáciles de revisar y reduce desperdicio de almacenamiento. En centros de llamadas, reuniones, entrevistas, salas de despacho y grabación de cumplimiento, la segmentación mejora la búsqueda y reproducción.
Algunos sistemas usan marcadores VAD para resaltar en una línea de tiempo las secciones con habla activa. Los revisores pueden saltar directamente a los segmentos de voz en lugar de escuchar intervalos largos de silencio.
Aplicaciones comunes
Reconocimiento automático de voz
Los sistemas ASR usan VAD para decidir qué parte de un flujo de audio debe reconocerse como habla. Sin VAD, el motor ASR puede recibir demasiado silencio o ruido, aumentando el coste de procesamiento y reduciendo la estabilidad del reconocimiento.
En IA conversacional, la VAD también se utiliza para la detección de fin de frase. Cuando el sistema detecta que el usuario ha dejado de hablar, puede enviar el enunciado completo al modelo de lenguaje o motor de diálogo. Una buena detección de fin hace que la conversación se sienta más rápida y natural.
VoIP y videoconferencia
Los teléfonos VoIP, softphones, plataformas de conferencia y aplicaciones WebRTC pueden usar VAD para optimizar la transmisión de audio. Durante el silencio, el sistema puede reducir el envío de paquetes o marcar el flujo como inactivo. Esto reduce el uso de red, especialmente en reuniones grandes o entornos de bajo ancho de banda.
La VAD también puede apoyar la detección de hablante activo en videoreuniones. Cuando el sistema sabe quién habla, puede resaltarlo, ajustar la disposición o mejorar la mezcla de audio.
Centros de llamadas y control de calidad
Los centros de llamadas usan VAD para analizar patrones de habla de agentes y clientes. Puede identificar periodos de silencio, interrupciones, pausas largas, habla simultánea y retrasos de respuesta. Estos datos ayudan a revisar la calidad del servicio, optimizar guiones y formar agentes.
Combinada con analítica de voz, la VAD también ayuda a segmentar conversaciones antes de transcribir, detectar palabras clave, analizar sentimiento o realizar controles de cumplimiento.
Radio, intercomunicador y sistemas push-to-talk
En comunicación por radio e intercomunicador, la VAD puede controlar la activación de audio, reducir ruido de canal abierto y mejorar el funcionamiento manos libres. Puede utilizarse en sistemas de despacho, intercomunicadores industriales, transporte, salas de seguridad y redes de respuesta a emergencias.
Sin embargo, estos entornos suelen tener mucho ruido de fondo. Los ajustes VAD deben afinarse cuidadosamente para evitar activaciones falsas por sirenas, motores, alarmas, maquinaria, viento u otros sonidos no verbales.
Consideraciones de implementación
Calidad y ubicación del micrófono
El rendimiento de la VAD depende mucho de la calidad de entrada de audio. Incluso un buen algoritmo puede fallar si el micrófono está demasiado lejos del hablante, expuesto al viento, cerca de una fuente de ruido o afectado por eco. La selección y ubicación del micrófono deben formar parte del diseño de VAD.
Los micrófonos direccionales, el aislamiento acústico, la cancelación de eco y la supresión de ruido pueden mejorar la calidad de detección. En salas de conferencia y entornos industriales, la distribución de micrófonos puede ser tan importante como la configuración del software.
Latencia y temporización de final de frase
La baja latencia es importante, pero cortar la voz de forma agresiva puede dañar la experiencia del usuario. El sistema debe equilibrar respuesta rápida y captura completa del habla. Por ejemplo, un asistente de IA puede necesitar un tiempo de silencio corto, mientras que un software de dictado puede requerir uno más largo para permitir pausas naturales.
La temporización de fin debe coincidir con la aplicación. Una frase de comando, una conversación de atención al cliente, una transcripción de reunión y un mensaje de despacho por radio pueden necesitar duraciones de silencio diferentes.
Pruebas en condiciones acústicas reales
La VAD debe probarse con audio realista, no solo con grabaciones limpias de laboratorio. Las pruebas de campo deben incluir hablantes distintos, acentos, velocidades de habla, distancias al micrófono, niveles de ruido, condiciones de eco y estados de red.
También deben revisarse casos límite como respuestas cortas, voz susurrada, hablantes solapados, ruido repentino, pausas largas y habla después del silencio. Estos casos revelan si la configuración de VAD es adecuada para producción.

Conclusión
La detección de actividad de voz es una tecnología base para los sistemas de voz modernos. Ayuda a identificar cuándo empieza el habla, cuándo termina y qué partes de un flujo de audio deben transmitirse, grabarse o procesarse. Aunque trabaja en segundo plano, tiene un impacto directo en experiencia de usuario, eficiencia de ancho de banda, precisión ASR, calidad de grabación y rendimiento de comunicación en tiempo real.
Una implementación exitosa de VAD requiere más que activar una función. Debe considerar calidad del micrófono, entorno acústico, sensibilidad, objetivos de latencia, temporización de fin, supresión de ruido y flujo de trabajo de la aplicación. Cuando se diseña y prueba correctamente, la VAD hace que los sistemas de voz sean más rápidos, limpios, eficientes y naturales.
FAQ
¿La detección de actividad de voz es lo mismo que la detección de palabra de activación?
No. VAD detecta si hay habla, mientras que la detección de palabra de activación busca una frase concreta, como el nombre del dispositivo o una orden de activación. Un sistema puede usar VAD antes de esa detección para reducir procesamiento innecesario, pero las dos funciones no son iguales.
¿Puede VAD entender lo que dice una persona?
No. VAD no reconoce palabras ni significado. Solo decide si el audio probablemente contiene habla. Se necesita reconocimiento de voz o procesamiento del lenguaje natural para convertir la voz en texto y entender la intención del usuario.
¿Por qué un sistema VAD a veces se detiene antes de que el usuario termine?
Normalmente ocurre cuando el tiempo de silencio es demasiado corto, el usuario pausa entre palabras, el nivel del micrófono es bajo o el ruido de fondo vuelve inestable la detección. Ajustar el retardo de final, la ganancia y el tiempo de retención puede reducir el problema.
¿Funciona bien VAD cuando varias personas hablan al mismo tiempo?
VAD puede detectar que existe habla, pero no separa automáticamente a los hablantes. En entornos con varias personas, puede ser necesaria la diarización de hablantes, formación de haces o separación de fuentes de audio para identificar quién habla.
¿Debe ejecutarse VAD en el dispositivo o en la nube?
Ambas opciones son posibles. La VAD en el dispositivo reduce ancho de banda, mejora privacidad y baja el coste de nube. La VAD en la nube puede ofrecer modelos más potentes y actualizaciones más fáciles. La mejor opción depende de latencia, privacidad, capacidad de hardware y arquitectura del sistema.







