HTTP, o Protocolo de Transferencia de Hipertexto, es el protocolo de capa de aplicación utilizado para transferir páginas web, datos de API, archivos, formularios, imágenes, scripts y otros recursos entre clientes y servidores. Es la base de la World Wide Web y uno de los protocolos de comunicación más usados en los sistemas modernos de Internet.
Cuando un usuario abre un sitio web, hace clic en un enlace, envía un formulario, carga una imagen o llama a una API, HTTP define cómo el cliente solicita un recurso y cómo responde el servidor. El protocolo no decide por sí mismo cómo se ve una página ni cómo se comporta una aplicación. Su función principal es ofrecer un método de comunicación estructurado entre las dos partes.
Una conversación de solicitud y respuesta
El principio básico es sencillo: un cliente envía una solicitud y un servidor devuelve una respuesta. El cliente suele ser un navegador web, una aplicación móvil, una aplicación de escritorio, una herramienta de API, un rastreador o un dispositivo embebido. El servidor es el sistema que aloja el recurso o servicio solicitado.
Por ejemplo, cuando un navegador visita un sitio web, envía una solicitud para pedir una página concreta. El servidor recibe la solicitud, comprueba qué recurso se solicita, procesa las reglas asociadas y devuelve una respuesta con contenido, información de estado y metadatos.
Este modelo se denomina comunicación de solicitud-respuesta. El cliente inicia el intercambio y el servidor contesta. Cada intercambio está estructurado para que ambas partes entiendan qué se solicita, cómo debe tratarse y qué resultado se devuelve.

Antes de que se mueva el primer byte
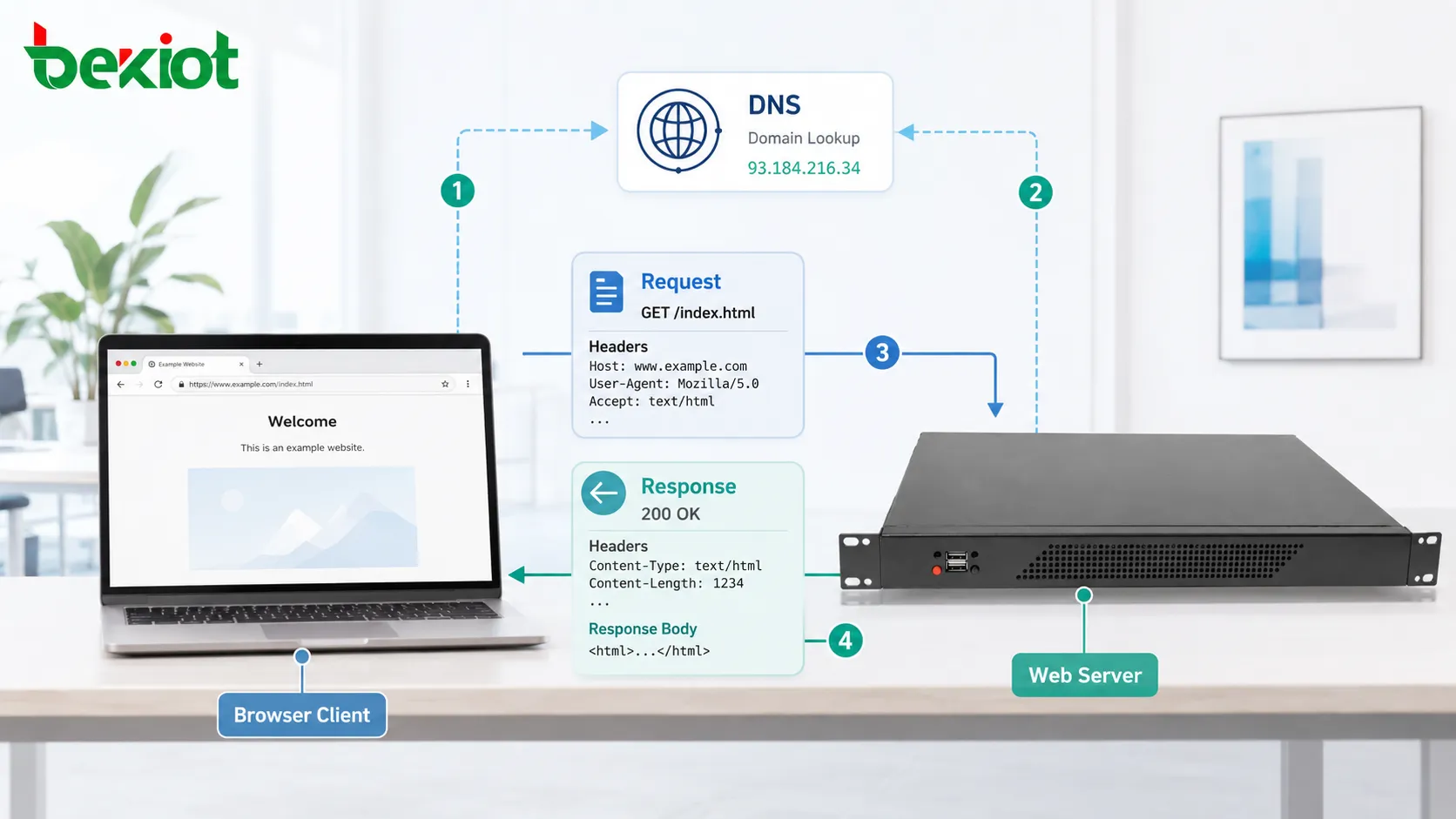
Antes de que una solicitud HTTP llegue al servidor, el cliente debe saber a dónde enviarla. Cuando un usuario introduce un nombre de dominio, el navegador normalmente realiza primero una resolución DNS. DNS traduce el nombre de dominio legible para las personas en una dirección IP.
Después, el cliente establece una conexión de red con el servidor. Con HTTP tradicional sobre TCP, esto significa abrir una conexión TCP. Con HTTPS también se realiza un intercambio TLS para que la comunicación pueda cifrarse y autenticarse.
Solo después de estos pasos puede intercambiarse el mensaje HTTP real. Esto significa que cargar una página web no depende solo del mensaje del protocolo. También depende de DNS, la conexión de transporte, el cifrado, la disponibilidad del servidor, el enrutamiento y el rendimiento de la red.
Anatomía de una solicitud del cliente
Una solicitud HTTP normalmente contiene un método, una ruta de destino, una versión, encabezados y a veces un cuerpo de mensaje. El método explica la acción prevista. La ruta identifica el recurso. Los encabezados aportan información adicional. El cuerpo transporta los datos enviados cuando es necesario.
Una solicitud simple puede pedir una página de inicio. Una solicitud más compleja puede enviar credenciales de inicio de sesión, cargar un archivo, enviar datos JSON a una API o pedir un recurso en caché solo si ha cambiado.
Los métodos de solicitud comunes incluyen GET, POST, PUT, PATCH, DELETE, HEAD y OPTIONS. Cada método tiene un significado distinto y debe usarse según el objetivo de la operación.
GET se usa comúnmente para recuperar datos. POST se utiliza a menudo para enviar datos. PUT y PATCH se usan para actualizar recursos. DELETE se usa para solicitar una eliminación. HEAD pide encabezados de respuesta sin el cuerpo completo. OPTIONS comprueba las opciones de comunicación admitidas.
Cómo interpreta el servidor el mensaje
Tras recibir la solicitud, el servidor lee el método, la ruta, los encabezados, el cuerpo, las cookies, los datos de autenticación y las reglas de enrutamiento. Luego decide qué debe ocurrir.
Si la solicitud es para un archivo estático, el servidor puede devolverlo directamente. Si es para una página dinámica o un endpoint de API, el servidor puede llamar a código de aplicación, consultar una base de datos, verificar permisos de usuario, ejecutar lógica de negocio o comunicarse con otro servicio.
El servidor también puede aplicar reglas de seguridad antes de devolver cualquier contenido. Puede comprobar si la solicitud está autenticada, si el usuario tiene permiso, si la solicitud está mal formada, si la fuente está bloqueada o si se han superado los límites de velocidad.
El resultado final se empaqueta en una respuesta HTTP.
Estructura y significado de la respuesta
Una respuesta HTTP normalmente contiene un código de estado, encabezados y un cuerpo opcional. El código de estado indica al cliente si la solicitud tuvo éxito, falló, fue redirigida o requiere más acciones.
Los encabezados describen la respuesta. Pueden incluir tipo de contenido, longitud de contenido, reglas de caché, cookies, información del servidor, método de compresión, política de seguridad y ubicación de redirección.
El cuerpo transporta el contenido real devuelto. Puede ser HTML, JSON, XML, datos de imagen, segmentos de video, archivos de texto, hojas de estilo, scripts o descargas binarias.
Un navegador usa el cuerpo y los encabezados de la respuesta para decidir qué mostrar, qué almacenar en caché, qué ejecutar, qué descargar y si se necesitan solicitudes adicionales.
Códigos de estado como señales de tráfico
Los códigos de estado ayudan a los clientes a entender rápidamente el resultado. Se agrupan por categorías.
| Rango de códigos | Significado general | Uso de ejemplo |
|---|---|---|
| 100-199 | Respuesta informativa | Continuar el procesamiento o aviso a nivel de protocolo |
| 200-299 | Respuesta satisfactoria | Página cargada, API devolvió datos, archivo entregado |
| 300-399 | Redirección | El recurso se movió o el cliente debe solicitar otra URL |
| 400-499 | Error del lado del cliente | Solicitud incorrecta, acceso no autorizado, recurso inexistente |
| 500-599 | Error del lado del servidor | Fallo de aplicación, error de pasarela, sobrecarga del servidor |
Una respuesta 200 suele significar que la solicitud se completó correctamente. Una respuesta 301 o 302 indica que el cliente debe ir a otra ubicación. Una respuesta 404 significa que no se encontró el recurso solicitado. Una respuesta 500 indica que el servidor encontró un problema interno.
Los códigos de estado no son solo para navegadores. Los clientes de API, sistemas de monitorización, rastreadores, proxies y balanceadores de carga también los usan para tomar decisiones.
Los encabezados llevan el contexto
Los encabezados son campos clave-valor que aportan contexto al intercambio. Ayudan a ambas partes a describir formato de datos, preferencia de idioma, compresión, autenticación, comportamiento de caché, cookies, comportamiento de conexión y requisitos de seguridad.
Por ejemplo, el encabezado Accept puede indicar al servidor qué tipos de contenido prefiere el cliente. Content-Type indica al receptor qué formato usa el cuerpo. Authorization puede transportar credenciales o tokens. Cache-Control define el comportamiento de caché.
Los encabezados hacen flexible al protocolo. El mismo modelo de solicitud-respuesta puede admitir sitios web, API, descargas de archivos, segmentos de streaming, flujos de autenticación e integraciones de servicios porque los encabezados añaden instrucciones sin cambiar la estructura básica del mensaje.
Diseño sin estado y gestión de sesiones
HTTP suele describirse como sin estado. Esto significa que cada solicitud es independiente de forma predeterminada. El servidor no recuerda automáticamente las solicitudes anteriores como parte del modelo básico del protocolo.
Sin embargo, la mayoría de los sitios web y aplicaciones reales necesitan comportamiento de sesión. Los usuarios inician sesión, añaden artículos a carritos, cambian ajustes y continúan flujos de trabajo a través de muchas solicitudes. Para admitirlo, los sistemas usan cookies, ID de sesión, tokens, almacenamiento local, sesiones del lado del servidor y encabezados de autenticación.
El protocolo sigue basado en solicitudes, pero las aplicaciones construyen continuidad sobre él. Por eso un sitio web puede recordar a un usuario aunque el intercambio subyacente siga formado por solicitudes y respuestas separadas.
Identificación de recursos con URL
Una URL indica al cliente dónde se encuentra un recurso y cómo solicitarlo. Normalmente incluye un esquema, host, ruta, cadena de consulta y a veces un puerto o fragmento.
El esquema puede ser http o https. El host identifica el dominio. La ruta apunta a un recurso o ruta específica. La cadena de consulta lleva parámetros adicionales. El fragmento suele gestionarse en el lado del cliente y no necesita enviarse al servidor del mismo modo que la ruta principal.
Las URL hacen que los recursos web sean direccionables. Permiten que navegadores, API, motores de búsqueda, aplicaciones y usuarios se refieran a recursos en un formato coherente.
Qué ocurre cuando se carga una página web
La carga de una sola página puede implicar muchos intercambios HTTP. La primera solicitud puede recuperar el documento HTML principal. Tras leerlo, el navegador descubre recursos adicionales como archivos CSS, JavaScript, imágenes, fuentes, iconos, scripts de analítica, llamadas API y archivos multimedia.
Cada recurso puede requerir otra solicitud. Algunos recursos pueden venir del mismo servidor, mientras que otros pueden venir de CDN, servicios de terceros, sistemas publicitarios, proveedores de mapas o pasarelas API.
Después, el navegador combina los recursos recibidos, construye la estructura de la página, aplica estilos, ejecuta scripts y renderiza la interfaz visual final. Por eso una página web puede requerir decenas o incluso cientos de intercambios de protocolo detrás de una sola acción visible.
Caché y mejora del rendimiento
La caché permite a clientes, navegadores, proxies, CDN y servidores reutilizar recursos descargados anteriormente cuando corresponde. Esto reduce transferencias repetidas de datos, baja la latencia, ahorra ancho de banda y mejora la experiencia del usuario.
El comportamiento de caché se controla mediante encabezados como Cache-Control, ETag, Last-Modified y Expires. Estos encabezados ayudan a determinar si un recurso puede reutilizarse, debe revalidarse o debe descargarse de nuevo.
Para archivos estáticos como imágenes, scripts y hojas de estilo, la caché puede reducir mucho el tiempo de carga. Para datos dinámicos, debe usarse con cuidado porque el contenido desactualizado puede producir resultados incorrectos.
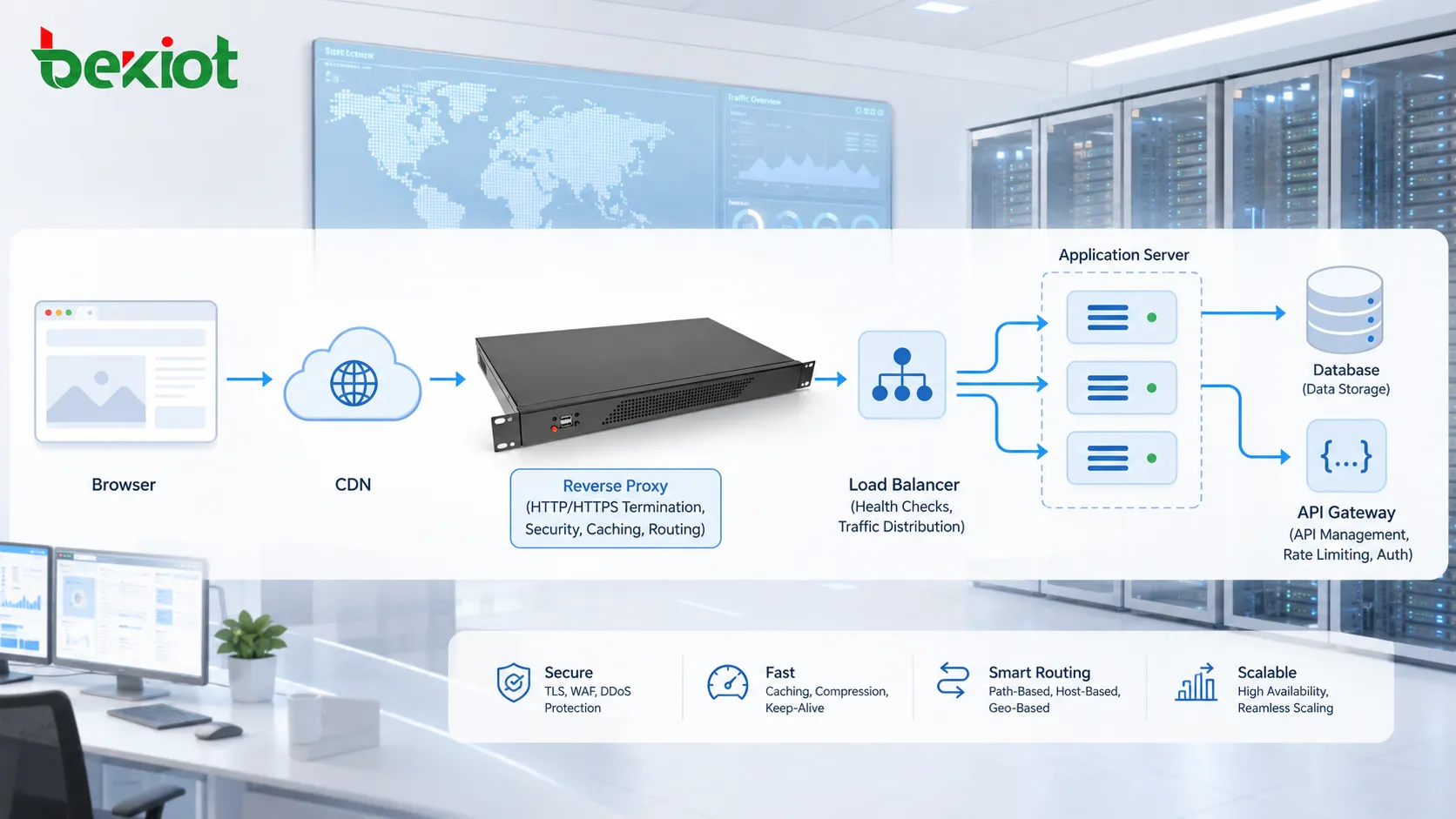
Papel de proxies, pasarelas y CDN
El tráfico HTTP no siempre viaja directamente del navegador al servidor de origen. Puede pasar por proxies inversos, proxies directos, pasarelas API, balanceadores de carga, cortafuegos, nodos de borde CDN o sistemas de inspección de seguridad.
Un proxy inverso puede recibir solicitudes en nombre de servidores backend. Un balanceador puede distribuir tráfico entre varios servidores de aplicación. Una CDN puede almacenar contenido más cerca de los usuarios. Una pasarela API puede verificar tokens, limitar tasas de solicitud, transformar encabezados o enrutar tráfico a microservicios.
Estos sistemas intermedios mejoran escalabilidad, seguridad, rendimiento y capacidad de gestión. También hacen más compleja la resolución de problemas, porque los errores pueden producirse en distintas capas.
HTTPS y comunicación segura
HTTPS es HTTP transportado sobre cifrado TLS. Protege los datos en tránsito cifrando la comunicación entre cliente y servidor. También ayuda a verificar la identidad del servidor mediante certificados digitales.
Sin cifrado, información sensible como contraseñas, tokens, datos personales y cookies de sesión podría quedar expuesta a atacantes en la red. HTTPS reduce este riesgo y se ha convertido en el estándar normal para sitios web y API modernos.
La comunicación segura también depende de una configuración correcta de certificados, versiones de protocolo fuertes, cookies seguras, redirecciones adecuadas y ajustes seguros del servidor. HTTPS es esencial, pero debe configurarse correctamente.
Evolución de las versiones del protocolo
HTTP ha evolucionado para mejorar rendimiento y eficiencia. Las versiones tempranas usaban un manejo de solicitudes más simple. Las versiones posteriores introdujeron conexiones persistentes, multiplexación, compresión de encabezados, conceptos de server push y un comportamiento de transporte mejorado.
HTTP/1.1 mejoró la reutilización de conexiones y se desplegó ampliamente. HTTP/2 introdujo multiplexación, permitiendo que varias solicitudes y respuestas compartan una conexión de forma más eficiente. HTTP/3 usa QUIC sobre UDP para mejorar el establecimiento de conexión y reducir ciertos problemas de latencia en algunas condiciones de red.
El principio de funcionamiento sigue siendo la comunicación de solicitud-respuesta, pero los mecanismos de transporte y rendimiento se han vuelto más avanzados.
API y comunicación máquina a máquina
HTTP no se usa solo en navegadores. También es el estilo de protocolo dominante para muchas API. Aplicaciones móviles, aplicaciones web, plataformas IoT, servicios en la nube, sistemas de pago, herramientas de monitorización y sistemas empresariales suelen intercambiar datos JSON o XML sobre HTTP.
En la comunicación API, el cuerpo de la respuesta puede no ser una página HTML. Puede ser datos estructurados para que otro programa los procese. Los códigos de estado, encabezados, tokens de autenticación y métodos de solicitud se vuelven especialmente importantes para una integración predecible.
Por eso los desarrolladores deben entender tanto el modelo básico de funcionamiento como las convenciones prácticas usadas en el diseño de API.
Problemas comunes y sus causas
Una página lenta puede deberse a retraso DNS, archivos grandes, mala caché, sobrecarga del servidor, latencia de base de datos, congestión de red, demasiadas solicitudes o scripts ineficientes.
Un error 404 puede indicar un archivo faltante, URL incorrecta, ruta eliminada, regla de reescritura incorrecta o enlace roto. Un error 500 puede apuntar a fallo de código del servidor, problema de base de datos, problema de permisos o servicio backend mal configurado.
Los fallos de autenticación pueden implicar tokens caducados, cookies ausentes, credenciales incorrectas, configuraciones de origen cruzado bloqueadas o manejo incorrecto de encabezados.
Comprender la ruta de solicitud-respuesta ayuda a localizar dónde ocurre el problema.
Método práctico de resolución de problemas
Empiece comprobando la URL y el método de solicitud. Después inspeccione el código de estado. Luego revise encabezados de solicitud, encabezados de respuesta, cookies y cuerpo de respuesta. Las herramientas de desarrollador del navegador son útiles para este proceso.
Para problemas del lado del servidor, revise registros de acceso, registros de error, registros de aplicación, registros de proxy inverso y estado de servicios backend. En sistemas distribuidos, los ID de traza y de solicitud ayudan a seguir una solicitud a través de varios servicios.
Para problemas de rendimiento, compruebe tiempo DNS, tiempo de conexión, tiempo TLS, tiempo de respuesta del servidor, tiempo de descarga de contenido, comportamiento de caché y tamaño de recursos. Estos detalles muestran si el problema está relacionado con la red, el servidor o el frontend.
Por qué el modelo sigue siendo importante
El principio de funcionamiento de HTTP sigue siendo importante porque casi todos los servicios digitales modernos dependen de él. Sitios web, API, aplicaciones móviles, paneles en la nube, plataformas de gestión, sistemas de pago, servicios de inicio de sesión, sistemas de monitorización y plataformas IoT usan la misma idea básica: solicitar, procesar y responder.
Su fortaleza proviene de la simplicidad, extensibilidad, legibilidad y amplia compatibilidad. Puede transportar muchos tipos de contenido y admitir muchos tipos de aplicaciones manteniendo una estructura de comunicación coherente.
Al mismo tiempo, un buen diseño requiere atención a seguridad, caché, encabezados, códigos de estado, manejo de errores, compatibilidad de versiones y arquitectura de red.
Resumen
HTTP funciona permitiendo que un cliente envíe una solicitud estructurada a un servidor y reciba una respuesta estructurada. Alrededor de este modelo simple, los sistemas web modernos añaden DNS, TLS, caché, proxies, CDN, API, autenticación, optimización de rendimiento y controles de seguridad.
Preguntas frecuentes
¿HTTP es lo mismo que HTTPS?
No. HTTP define el modelo de intercambio de mensajes, mientras que HTTPS añade cifrado TLS y verificación de identidad basada en certificados para proteger la comunicación en tránsito.
¿Por qué una página web activa muchas solicitudes?
Una página suele depender de archivos separados como imágenes, scripts, hojas de estilo, fuentes, llamadas API y recursos multimedia. El navegador solicita estos recursos después de leer el documento principal.
¿Puede usarse HTTP sin navegador?
Sí. Aplicaciones móviles, servidores, herramientas de línea de comandos, dispositivos IoT, sistemas de monitorización y API pueden usar HTTP sin un navegador web tradicional.
¿Por qué algunas llamadas API devuelven datos en lugar de páginas web?
Las API suelen devolver datos estructurados como JSON o XML. El programa receptor procesa esos datos en lugar de mostrarlos como una página web.
¿Qué debe revisarse primero cuando falla una solicitud HTTP?
Revise la URL, el método de solicitud, el código de estado, los encabezados, el estado de autenticación, la conexión de red, los registros del servidor y si algún proxy o pasarela está cambiando la solicitud.