La alta disponibilidad es un enfoque de diseño que mantiene un sistema, servicio, aplicación o red accesible incluso cuando fallan componentes individuales. En lugar de depender de un único servidor, una sola base de datos, una sola ruta de red, una única fuente de alimentación o un único proceso de software, un sistema de alta disponibilidad utiliza redundancia, monitorización, conmutación por error y planificación de recuperación para reducir el tiempo de inactividad y mantener la continuidad del servicio.
Para las empresas y organizaciones que dependen de las operaciones digitales, la alta disponibilidad no es solo un concepto de TI. Afecta a la experiencia del cliente, la eficiencia de la producción, la respuesta ante emergencias, la fiabilidad de las comunicaciones, el acceso a los datos, las operaciones de seguridad y los compromisos de nivel de servicio. Una breve interrupción puede ser aceptable para una herramienta interna de baja prioridad, pero esa misma interrupción puede ser inaceptable para un sistema hospitalario, una plataforma de despacho, una pasarela de pago, una red de control industrial, un servicio de comunicación pública o una aplicación en la nube utilizada por miles de usuarios.
Significado en el diseño práctico de sistemas
La alta disponibilidad, a menudo abreviada como HA, se refiere a la capacidad de un sistema para mantenerse utilizable durante un alto porcentaje de tiempo. Se suele discutir mediante objetivos de tiempo de actividad como 99,9 %, 99,99 % o 99,999 %. Sin embargo, la disponibilidad no solo consiste en si un servidor está encendido. Un sistema está realmente disponible solo cuando los usuarios pueden completar las acciones que necesitan, como realizar una llamada, enviar una transacción, abrir una aplicación, recibir una alarma, sincronizar registros o acceder a información en tiempo real.
Un servicio fiable depende de toda la cadena de servicio. Esta puede incluir recursos de cómputo, almacenamiento, motores de bases de datos, conmutadores de red, cortafuegos, DNS, servicios de identidad, certificados de seguridad, procesos de aplicación, herramientas de monitorización, enlaces de respaldo, infraestructura de alimentación y procedimientos operativos. Si una dependencia crítica carece de una ruta de respaldo, todo el servicio puede seguir siendo vulnerable.
La alta disponibilidad también se diferencia de una simple copia de seguridad. Una copia de seguridad ayuda a restaurar los datos después de un fallo, pero puede no mantener el servicio en funcionamiento durante el fallo. La HA se centra en la continuidad. Permite que otro nodo, ruta, instancia de servicio o sitio asuma el control antes de que los usuarios experimenten una interrupción prolongada.
Por qué las organizaciones diseñan para la continuidad
El valor de la alta disponibilidad se hace evidente cuando el tiempo de inactividad genera consecuencias reales. En el comercio electrónico, puede significar pedidos perdidos y fallos en los pagos. En las telecomunicaciones, puede implicar llamadas perdidas, extensiones inaccesibles o enrutamiento de emergencia interrumpido. En la fabricación, puede detener los flujos de trabajo de producción. En la atención sanitaria y la seguridad pública, puede retrasar la comunicación, la coordinación y la respuesta.
La disponibilidad también protege la confianza. Los clientes, empleados, socios y equipos de campo esperan que los sistemas modernos estén accesibles en cualquier momento. Cuando una plataforma se desconecta repetidamente, los usuarios pueden perder la confianza incluso si cada interrupción es breve. Para los proveedores de servicios y las plataformas empresariales, un tiempo de actividad estable forma parte de la experiencia general del producto.
Otra razón es el control operativo. Sin una planificación de HA, los equipos técnicos a menudo dependen de la resolución de problemas de emergencia después de que un fallo ya ha afectado a los usuarios. Con redundancia, comprobaciones de salud automatizadas, lógica de conmutación por error y procedimientos de incidencia claros, los fallos se convierten en eventos controlados en lugar de crisis inesperadas.
Un sistema de alta disponibilidad no asume que los fallos nunca ocurrirán. Asume que los fallos sucederán y prepara el servicio para seguir funcionando cuando ocurran.
Características principales que respaldan un funcionamiento fiable
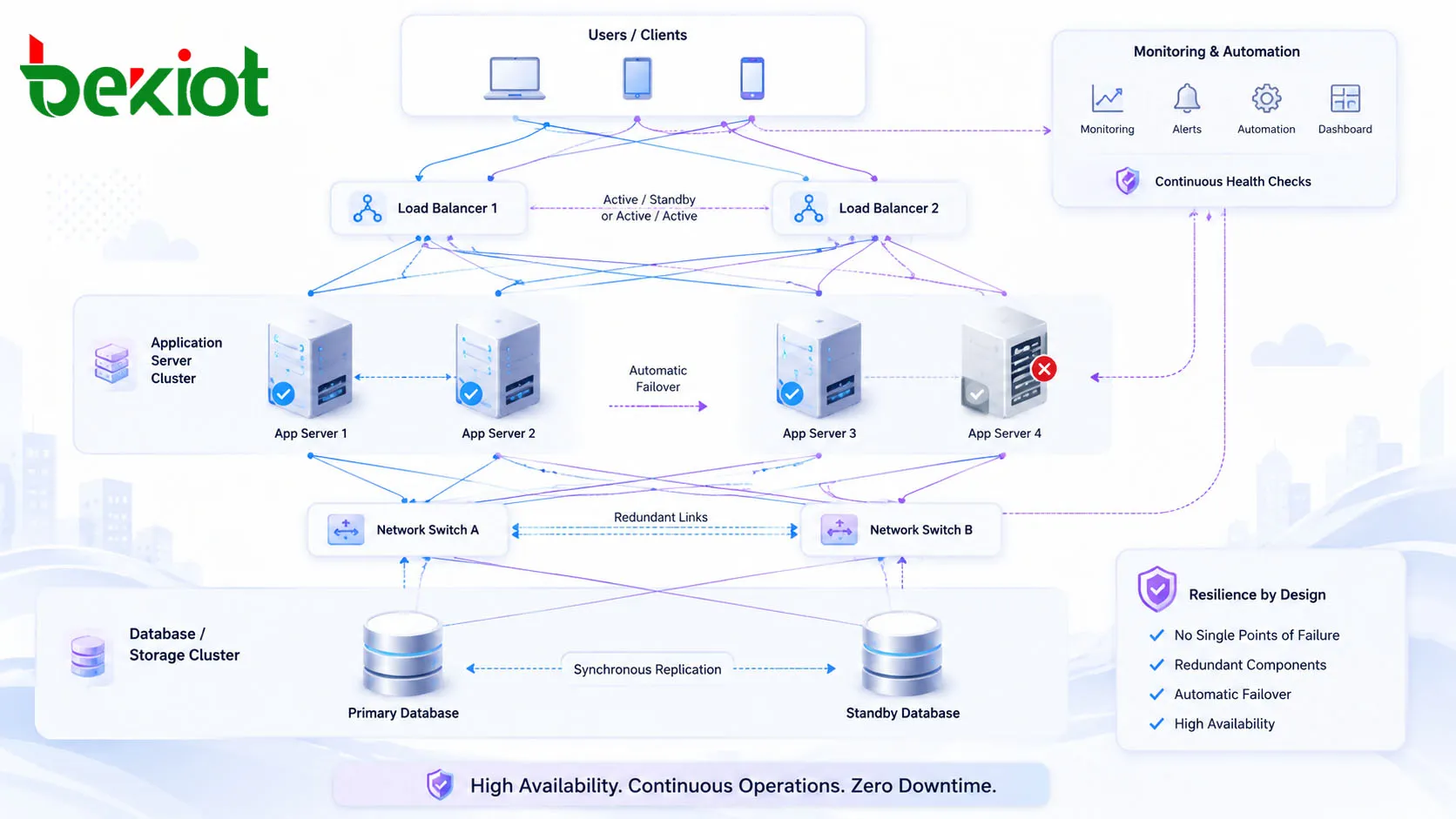
Infraestructura redundante
La redundancia es la base de la alta disponibilidad. Los componentes importantes se duplican para que otro componente pueda seguir funcionando si el activo falla. La redundancia puede incluir varios servidores, nodos de aplicación agrupados, almacenamiento en espejo, bases de datos replicadas, fuentes de alimentación duales, enrutadores de respaldo, conmutadores redundantes, múltiples conexiones a internet e instancias de servicio duplicadas en diferentes ubicaciones.
Una redundancia eficaz debe cubrir la ruta de servicio real. Dos servidores de aplicaciones no proporcionan protección completa si ambos dependen de una sola base de datos, una única matriz de almacenamiento, un único cortafuegos, un único circuito de alimentación o un proveedor externo. La planificación de HA debe revisar cada dependencia que el servicio necesita para funcionar.
Conmutación por error automática
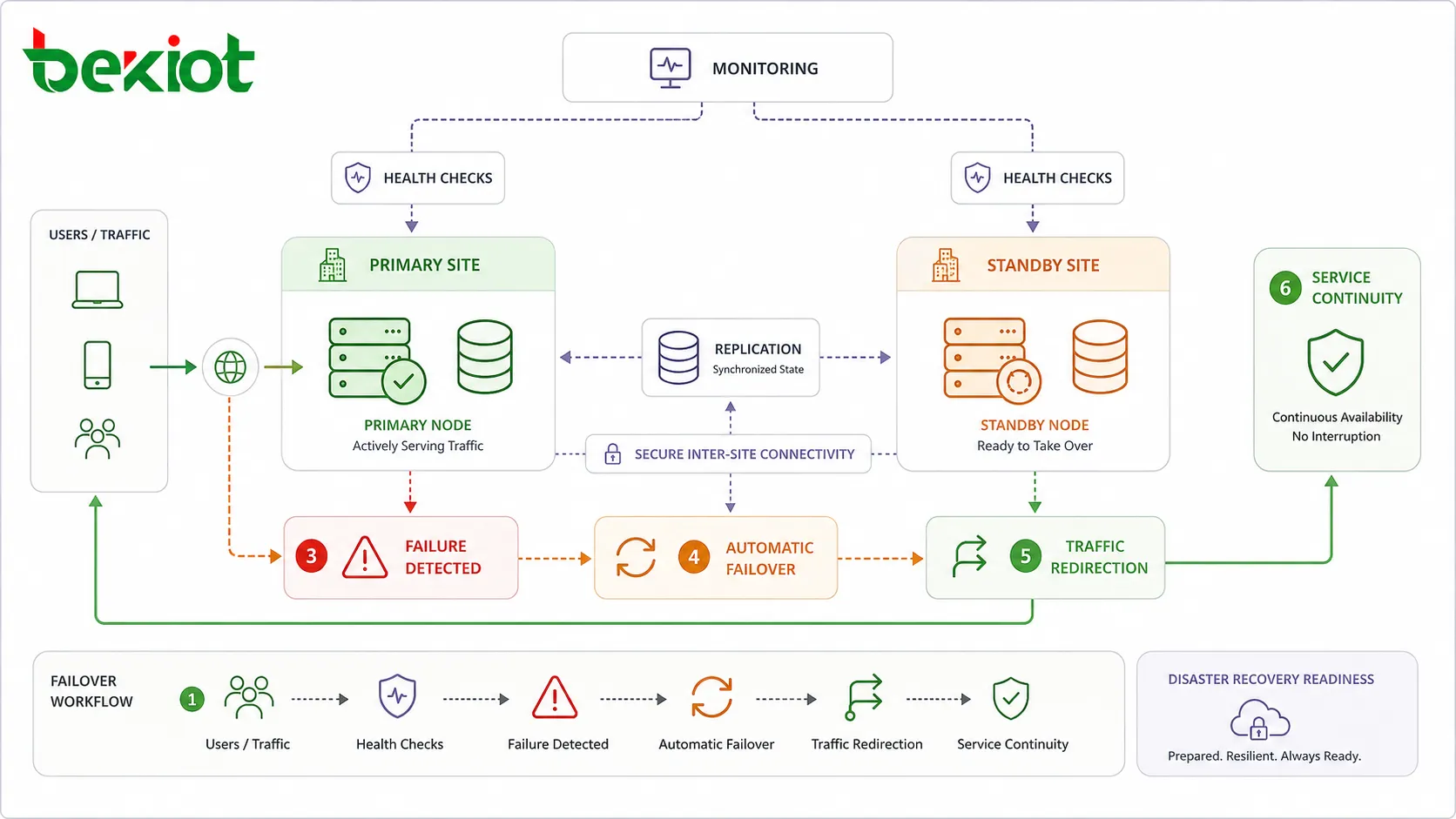
La conmutación por error es el proceso de trasladar el servicio de un componente fallido a un componente saludable. En muchos diseños de HA, este proceso ocurre automáticamente. Por ejemplo, un balanceador de carga puede eliminar un servidor no saludable de la rotación, una base de datos en espera puede convertirse en la base de datos principal o una ruta de red de respaldo puede tomar el control cuando el enlace principal se interrumpe.
La conmutación por error automática reduce el tiempo de recuperación porque no espera a que un ingeniero diagnostique el fallo manualmente. Sin embargo, la lógica de conmutación por error debe diseñarse cuidadosamente. Si las comprobaciones de salud son demasiado simples, el sistema podría cambiar innecesariamente. Si las reglas de conmutación por error son demasiado lentas, los usuarios pueden experimentar un tiempo de inactividad más largo del esperado.
Monitorización del estado del servicio
La monitorización permite al sistema y al equipo de operaciones detectar condiciones anormales de forma temprana. Una monitorización útil cubre la salud del servidor, el uso de CPU y memoria, el espacio en disco, el tiempo de respuesta del servicio, la replicación de la base de datos, la latencia de red, la pérdida de paquetes, la finalización de llamadas, la tasa de éxito de transacciones, la caducidad de certificados, el estado de las copias de seguridad y los eventos de seguridad.
Las comprobaciones de salud más útiles están conectadas al comportamiento real del servicio. Un dispositivo puede responder al ping mientras la aplicación está congelada. Un servidor web puede estar funcionando mientras la conexión a la base de datos está rota. Un servidor de comunicaciones puede estar en línea mientras el enrutamiento de llamadas está fallando. La monitorización debe confirmar si el servicio es realmente utilizable.
Distribución de carga
El balanceo de carga distribuye el tráfico entre varios servidores o instancias de servicio. Esto mejora el rendimiento durante el funcionamiento normal y respalda la continuidad durante los fallos. Si un nodo se sobrecarga o deja de estar disponible, el tráfico puede desviarse a otros nodos saludables.
El balanceo de carga se utiliza ampliamente para sitios web, API, aplicaciones en la nube, plataformas de comunicación, servicios de autenticación y sistemas empresariales internos. Según el diseño, puede admitir persistencia de sesión, enrutamiento geográfico, enrutamiento basado en el estado o dirección de tráfico consciente de la aplicación.
Replicación de datos
Muchos sistemas no pueden permanecer disponibles a menos que los datos también lo estén. La replicación de datos mantiene copias de información importante en varios nodos o ubicaciones. Esto permite que un servidor, sistema de almacenamiento o centro de datos secundario continúe el servicio si el entorno principal falla.
La replicación puede ser síncrona o asíncrona. La replicación síncrona confirma una escritura solo después de que los datos se hayan escrito en más de un lugar, lo que puede mejorar la consistencia pero puede aumentar la latencia. La replicación asíncrona suele ser más rápida, pero una pequeña cantidad de datos recientes puede estar en riesgo si ocurre un fallo repentino. La elección correcta depende del equilibrio necesario entre rendimiento, consistencia y pérdida de datos aceptable.
Mantenimiento sin apagado completo
Un buen diseño de HA también ayuda durante el mantenimiento planificado. Los sistemas necesitan actualizaciones, parches de seguridad, reemplazo de hardware, renovación de certificados, cambios de configuración y expansión de capacidad. Si la arquitectura admite actualizaciones progresivas o conmutación por error controlada, el mantenimiento puede completarse sin desconectar todo el servicio.
Esto es especialmente útil para servicios que funcionan las 24 horas. En lugar de esperar largas ventanas de mantenimiento, los equipos pueden actualizar un nodo a la vez mientras otros nodos continúan manejando el tráfico de producción.
Patrones de arquitectura comunes
Activo-en espera
En un diseño activo-en espera, un sistema maneja el tráfico de producción mientras que otro sistema permanece listo para tomar el control. Este modelo se utiliza a menudo para cortafuegos, bases de datos, centralitas PBX, pasarelas, aplicaciones industriales y plataformas de gestión central.
La ventaja de la arquitectura activo-en espera es la simplicidad y el comportamiento predecible de la conmutación por error. La desventaja es que los recursos en espera pueden no utilizarse plenamente durante el funcionamiento normal. El sistema en espera también debe probarse regularmente para confirmar que está sincronizado y listo.
Activo-activo
En un diseño activo-activo, varios sistemas manejan tráfico al mismo tiempo. Si un nodo falla, los nodos restantes continúan funcionando y absorben la carga de trabajo. Este modelo puede mejorar tanto la disponibilidad como el rendimiento porque la capacidad se utiliza de forma continua.
La arquitectura activo-activo generalmente requiere un diseño más cuidadoso. Las aplicaciones deben manejar sesiones distribuidas, consistencia de datos, comportamiento de enrutamiento y posibles escenarios de conflicto. Si el software no está diseñado para operación distribuida, el despliegue activo-activo puede crear complejidad en lugar de fiabilidad.
Servicios en clúster
Un clúster es un grupo de nodos que trabajan juntos como un solo servicio. Los sistemas en clúster pueden proteger aplicaciones, bases de datos, máquinas virtuales, plataformas de almacenamiento, cargas de trabajo en contenedores y servicios de comunicación. Los gestores de clúster monitorizan la salud de los nodos y coordinan la conmutación por error o la redistribución de la carga de trabajo.
Un clustering estable requiere una comunicación de latido adecuada, reglas de quórum, mecanismos de aislamiento y separación de red. Estos controles ayudan a prevenir situaciones de cerebro dividido, donde dos nodos creen incorrectamente que ambos son el sistema principal.
Despliegue multisitio
Para requisitos de resiliencia más altos, los sistemas pueden desplegarse en múltiples sitios, centros de datos, zonas de disponibilidad en la nube o regiones. Si un sitio queda indisponible debido a un fallo de alimentación, interrupción de red, daño físico o un incidente grave de infraestructura, otro sitio puede continuar el servicio.
El diseño multisitio es más complejo que la redundancia local. Requiere dirección de tráfico, conectividad segura, planificación de replicación, configuración consistente, coordinación operativa y pruebas periódicas de recuperación ante desastres. También requiere reglas claras sobre cuándo cambiar el tráfico entre sitios.
Métricas utilizadas para medir la continuidad del servicio
Porcentaje de tiempo de actividad
El porcentaje de tiempo de actividad mide cuánto tiempo permanece operativo un sistema durante un período específico. Se utiliza a menudo en acuerdos de nivel de servicio y objetivos internos de fiabilidad. Los objetivos de tiempo de actividad más altos requieren una arquitectura más sólida, una recuperación más rápida, una mejor monitorización y operaciones más disciplinadas.
Sin embargo, el tiempo de actividad debe medirse desde la perspectiva del usuario. Un sistema que técnicamente está en funcionamiento pero es incapaz de procesar solicitudes, completar llamadas, acceder a datos o responder en límites de tiempo aceptables no debe considerarse completamente disponible.
Objetivo de tiempo de recuperación (RTO)
El objetivo de tiempo de recuperación, o RTO, define la rapidez con la que debe restablecerse el servicio después de una interrupción. Un RTO corto generalmente requiere conmutación por error automatizada, capacidad en espera lista para usar, procedimientos probados y detección rápida.
El RTO debe coincidir con el impacto en el negocio. No todos los sistemas necesitan una recuperación inmediata. Algunos sistemas internos pueden tolerar un período de recuperación más largo, mientras que los servicios de misión crítica pueden requerir un funcionamiento casi continuo.
Objetivo de punto de recuperación (RPO)
El objetivo de punto de recuperación, o RPO, define cuánta pérdida de datos es aceptable después de un fallo. Un RPO bajo requiere una replicación frecuente o continua. Un RPO más alto puede permitir la recuperación a partir de copias de seguridad programadas.
El RPO es importante para registros de transacciones, registros de llamadas, historiales de eventos, datos de producción, información de usuarios, pistas de auditoría e informes operativos. Si la pérdida de datos es inaceptable, el diseño de replicación y copia de seguridad debe ser más estricto.
Tiempo medio de reparación (MTTR)
El tiempo medio de reparación, o MTTR, mide cuánto se tarda en restaurar el servicio normal después de un fallo. La alta disponibilidad mejora cuando se reduce el MTTR. Una mejor automatización, documentación más clara, operadores capacitados, recursos de repuesto y planes de recuperación probados ayudan a acortar el tiempo de reparación.
Reducir el tiempo de reparación suele ser más realista que intentar prevenir todos los fallos posibles. Incluso los sistemas bien diseñados fallarán eventualmente, pero una organización bien preparada puede recuperarse más rápido y con menor impacto en el usuario.
Aplicaciones en entornos del mundo real
Plataformas en la nube y aplicaciones SaaS
Los servicios en la nube y las plataformas SaaS utilizan el diseño de HA para mantener las aplicaciones accesibles a los usuarios en diferentes ubicaciones y zonas horarias. Las técnicas comunes incluyen grupos de autoescalado, balanceadores de carga, bases de datos replicadas, almacenamiento de objetos distribuido, comprobaciones de salud, regiones de respaldo y estrategias de despliegue progresivo.
Para los servicios basados en suscripción, la disponibilidad afecta directamente a la retención de clientes y la reputación de la marca. Es posible que los usuarios no conozcan los detalles de la arquitectura, pero notan rápidamente respuestas lentas, fallos de inicio de sesión, datos faltantes o interrupciones del servicio.
Sistemas de comunicación empresarial
Los sistemas de voz, vídeo, mensajería, localización y despacho a menudo requieren alta disponibilidad porque la comunicación puede ser necesaria tanto durante el trabajo rutinario como en incidentes urgentes. La planificación de HA puede incluir servidores de llamadas redundantes, troncales SIP de respaldo, pasarelas secundarias, rutas de red resilientes, sistemas de sucursal con supervivencia local y alimentación de respaldo.
La disponibilidad de la comunicación debe probarse de extremo a extremo. No basta con que un servidor esté en línea si los teléfonos no pueden registrarse, las llamadas no se pueden enrutar, el audio no puede atravesar la red o no se puede contactar con los números de emergencia.
Operaciones industriales y energéticas
Las instalaciones industriales, servicios públicos, minería, puertos, centros de transporte e instalaciones energéticas a menudo dependen de la monitorización y comunicación continuas. En estos entornos, la alta disponibilidad puede incluir anillos de fibra redundantes, enlaces inalámbricos de respaldo, servidores de control dual, capacidad de supervivencia local, equipos robustecidos y rutas de emergencia aisladas.
El diseño debe considerar tanto los fallos de TI como las condiciones físicas. Los entornos hostiles, las interferencias electromagnéticas, las ubicaciones remotas, la inestabilidad de la alimentación y el acceso limitado al mantenimiento pueden afectar la disponibilidad.
Atención sanitaria y servicios de emergencia
Los hospitales, centros de respuesta a emergencias, agencias de seguridad pública y salas de mando dependen de sistemas fiables para la coordinación. La alta disponibilidad puede respaldar el acceso a la información del paciente, la notificación de alarmas, la comunicación de emergencia, los flujos de trabajo de despacho, el control de acceso, la videovigilancia y la colaboración interna.
En estos entornos, el tiempo de inactividad no es solo un problema técnico. Puede afectar la velocidad de respuesta, la seguridad, la toma de decisiones y la continuidad de la atención. La alimentación de respaldo, las redes redundantes, los procedimientos de escalado claros y los simulacros regulares son especialmente importantes.
Finanzas, comercio minorista y transacciones en línea
Los bancos, procesadores de pagos, plataformas de trading y tiendas en línea requieren sistemas fiables para proteger las transacciones y el acceso de los clientes. Incluso las interrupciones breves pueden causar pagos fallidos, ventas perdidas, pedidos retrasados, problemas de liquidación o quejas de clientes.
Estos sistemas a menudo combinan la planificación de disponibilidad con una seguridad sólida, registro de auditoría, monitorización de fraudes, cifrado y controles de cumplimiento. La continuidad del servicio debe diseñarse junto con la integridad de los datos y la gestión de riesgos.
Consideraciones de diseño antes del despliegue
Mapear la cadena completa de dependencias
El primer paso es comprender cómo funciona realmente el servicio. Los equipos deben mapear aplicaciones, bases de datos, redes, almacenamiento, autenticación, DNS, cortafuegos, servicios de terceros, certificados, herramientas de monitorización y responsabilidades operativas. Esto ayuda a identificar dependencias ocultas que podrían convertirse en puntos únicos de fallo.
Un mapa de servicio también ayuda a los equipos a decidir qué componentes necesitan redundancia y qué riesgos se pueden aceptar. No todas las dependencias requieren el mismo nivel de protección, pero todas las dependencias críticas deben ser visibles.
Establecer objetivos de recuperación realistas
Los objetivos de disponibilidad deben basarse en las necesidades del negocio, no en el lenguaje de marketing. Una plataforma de misión crítica puede justificar una redundancia costosa y una replicación casi en tiempo real. Una herramienta de informes de baja prioridad puede necesitar solo copias de seguridad programadas y recuperación manual.
Unos objetivos de RTO y RPO claros ayudan a los equipos a elegir la arquitectura adecuada. También ayudan a evitar sobreingeniería en sistemas que no necesitan protección avanzada o a infraproteger servicios que son esenciales para las operaciones.
Probar la conmutación por error en condiciones controladas
Un plan de conmutación por error solo es valioso si funciona cuando se necesita. Las pruebas controladas verifican si la monitorización detecta el fallo, los recursos en espera se activan correctamente, el tráfico se redirige como se espera, los datos permanecen consistentes y los usuarios pueden seguir trabajando.
Las pruebas deben incluir la conmutación por error planificada, la simulación de fallo de nodo, el aislamiento de red, la restauración de copias de seguridad, la recuperación de la base de datos y los procedimientos de reversión. Los resultados deben documentarse para que las mejoras futuras se basen en evidencias y no en suposiciones.
Controlar los cambios de configuración
Muchas interrupciones son causadas por errores humanos en lugar de fallos de hardware. Reglas de cortafuegos incorrectas, certificados caducados, actualizaciones incompatibles, cambios de enrutamiento erróneos, errores de permisos en la base de datos y configuraciones inconsistentes pueden interrumpir el servicio.
El control de cambios, la gestión de versiones, los flujos de trabajo de aprobación, los entornos de prueba, los planes de reversión y las copias de seguridad de la configuración reducen este riesgo. En entornos de HA, tanto los sistemas principales como los de reserva deben mantenerse alineados.
Desafíos y limitaciones
La alta disponibilidad reduce el tiempo de inactividad, pero no hace que un sistema sea a prueba de fallos. Los errores de software, el ransomware, los errores de configuración, la corrupción de datos, las interrupciones de dependencias, los desastres regionales y los errores de los operadores aún pueden interrumpir el servicio. La HA debe trabajar junto con las copias de seguridad, la ciberseguridad, la recuperación ante desastres, la observabilidad y la respuesta a incidentes.
El costo es otro desafío. La arquitectura redundante puede requerir más servidores, dispositivos de red, recursos en la nube, licencias, sistemas de monitorización, capacidad de almacenamiento y experiencia operativa. Cuanto mayor sea el objetivo de disponibilidad, más importante es justificar la inversión.
La complejidad también puede convertirse en un riesgo. Un diseño de HA complicado que el equipo de operaciones no comprende puede fallar durante un incidente. La alta disponibilidad práctica debe ser documentada, comprobable y manejable por las personas responsables de su funcionamiento.
La mejor estrategia de disponibilidad no siempre es la más compleja. Es aquella que protege los servicios más importantes, puede probarse regularmente y puede operarse con confianza durante incidentes reales.
Mejores prácticas para la fiabilidad a largo plazo
Comience con la clasificación de servicios. Identifique qué sistemas son de misión crítica, cuáles son importantes para el negocio y cuáles pueden tolerar una recuperación más larga. Esto permite enfocar los recursos donde el tiempo de inactividad tiene el mayor impacto.
Utilice una monitorización que refleje los resultados reales del usuario. En lugar de verificar solo el estado del dispositivo, monitorice si los usuarios pueden iniciar sesión, realizar llamadas, acceder a registros, enviar formularios, recibir alertas o completar transacciones. Esto ofrece una visión más precisa del estado del servicio.
Mantenga la documentación actualizada. Los diagramas de arquitectura, los pasos de conmutación por error, las listas de contactos, las rutas de escalado, las ubicaciones de las copias de seguridad, la gestión de credenciales y los procedimientos de reversión deben actualizarse después de cada cambio importante. Durante un incidente, la documentación obsoleta puede retrasar la recuperación.
Revise la arquitectura regularmente. El volumen de tráfico, las versiones de software, los requisitos de seguridad, las dependencias de terceros y las prioridades comerciales cambian con el tiempo. Un sistema que cumplía los objetivos de disponibilidad en el pasado puede necesitar un rediseño a medida que aumentan el uso y el riesgo.
Conclusión
La alta disponibilidad es un método práctico para mantener accesibles los servicios importantes cuando ocurren fallos. Combina infraestructura redundante, conmutación por error automática, monitorización del estado, balanceo de carga, replicación de datos, planificación del mantenimiento y procedimientos de recuperación probados. Su valor es especialmente claro cuando el tiempo de inactividad afecta a la seguridad, los ingresos, la comunicación, la producción, el cumplimiento normativo o la confianza del cliente.
Una estrategia de HA exitosa no consiste simplemente en añadir más equipos. Requiere comprender toda la cadena de servicio, identificar puntos únicos de fallo, establecer objetivos de recuperación realistas, probar la conmutación por error y equilibrar la fiabilidad con el costo y la complejidad. Cuando se diseña correctamente, la alta disponibilidad ayuda a las organizaciones a construir sistemas que siguen siendo fiables en condiciones reales.
Preguntas frecuentes
¿Puede un sistema de alta disponibilidad seguir perdiendo datos?
Sí. La disponibilidad y la protección de datos están relacionadas pero no son idénticas. Si la replicación se retrasa o las políticas de copia de seguridad son débiles, un servicio puede recuperarse rápidamente perdiendo datos recientes. La planificación del RPO es necesaria para controlar este riesgo.
¿Es lo mismo alta disponibilidad que tolerancia a fallos?
No. La tolerancia a fallos generalmente significa que un sistema sigue funcionando con poca o ninguna interrupción incluso cuando falla un componente. La alta disponibilidad se centra en reducir el tiempo de inactividad, pero puede producirse un breve retraso en la conmutación por error según la arquitectura.
¿Deberían las pequeñas empresas usar alta disponibilidad?
Sí, pero el diseño debe ajustarse al impacto en el negocio. Una empresa pequeña puede no necesitar una arquitectura multirregional, pero aún puede beneficiarse de enlaces a internet redundantes, copias de seguridad fiables, conmutación por error en la nube, servicios monitorizados y alimentación de respaldo para sistemas críticos.
¿Puede la alta disponibilidad proteger contra ciberataques?
Solo en parte. La HA puede ayudar a mantener el servicio si un nodo se aísla o restaura, pero no puede reemplazar los controles de ciberseguridad. El ransomware, el robo de credenciales, los ataques DDoS y la manipulación de datos requieren monitorización de seguridad, control de acceso, aplicación de parches, aislamiento de copias de seguridad y respuesta a incidentes.
¿Todas las aplicaciones admiten el despliegue activo-activo?
No. Algunas aplicaciones no están diseñadas para sesiones distribuidas, estado compartido o escrituras multinodo. Antes de elegir la arquitectura activo-activo, los equipos deben confirmar que el software, la base de datos, el modelo de licencias y el diseño de red pueden soportarlo de forma segura.