Un problema de base de datos rara vez se queda dentro de la base de datos. Cuando la única copia de los datos se vuelve lenta, inaccesible, corrupta o sobrecargada, el sistema de negocio que depende de ella lo nota de inmediato: no se pueden registrar pedidos, no se generan informes, los dispositivos no suben registros, los usuarios no inician sesión y la recuperación se convierte en una carrera contra el tiempo.
La replicación de bases de datos existe precisamente por esta razón. Crea una o varias copias adicionales de los datos y las mantiene sincronizadas con la base de origen, de modo que los sistemas puedan leer más rápido, recuperarse con mayor rapidez, distribuir cargas de trabajo y seguir funcionando cuando un único nodo de base de datos ya no es suficiente.
La idea básica detrás de la replicación de bases de datos
La replicación de bases de datos es el proceso de copiar datos de un nodo de base de datos a otro y mantener esas copias actualizadas cuando se producen cambios. La base de origen puede llamarse primaria, maestra, publicadora o líder, según la tecnología utilizada. La base receptora puede llamarse réplica, base en espera, suscriptora, secundaria o seguidora. Los nombres cambian, pero el propósito es similar: entregar los cambios realizados en un lugar a otro lugar de forma controlada.
Los datos copiados pueden incluir bases completas, tablas seleccionadas, particiones, esquemas, registros de transacciones o flujos de datos específicos. En algunos sistemas, la réplica solo se usa para respaldo o conmutación por error. En otros, las réplicas atienden tráfico de lectura, análisis, informes, acceso regional o procesamiento descendente. Por tanto, la replicación no es una función única y fija, sino un método de diseño para distintos objetivos operativos.
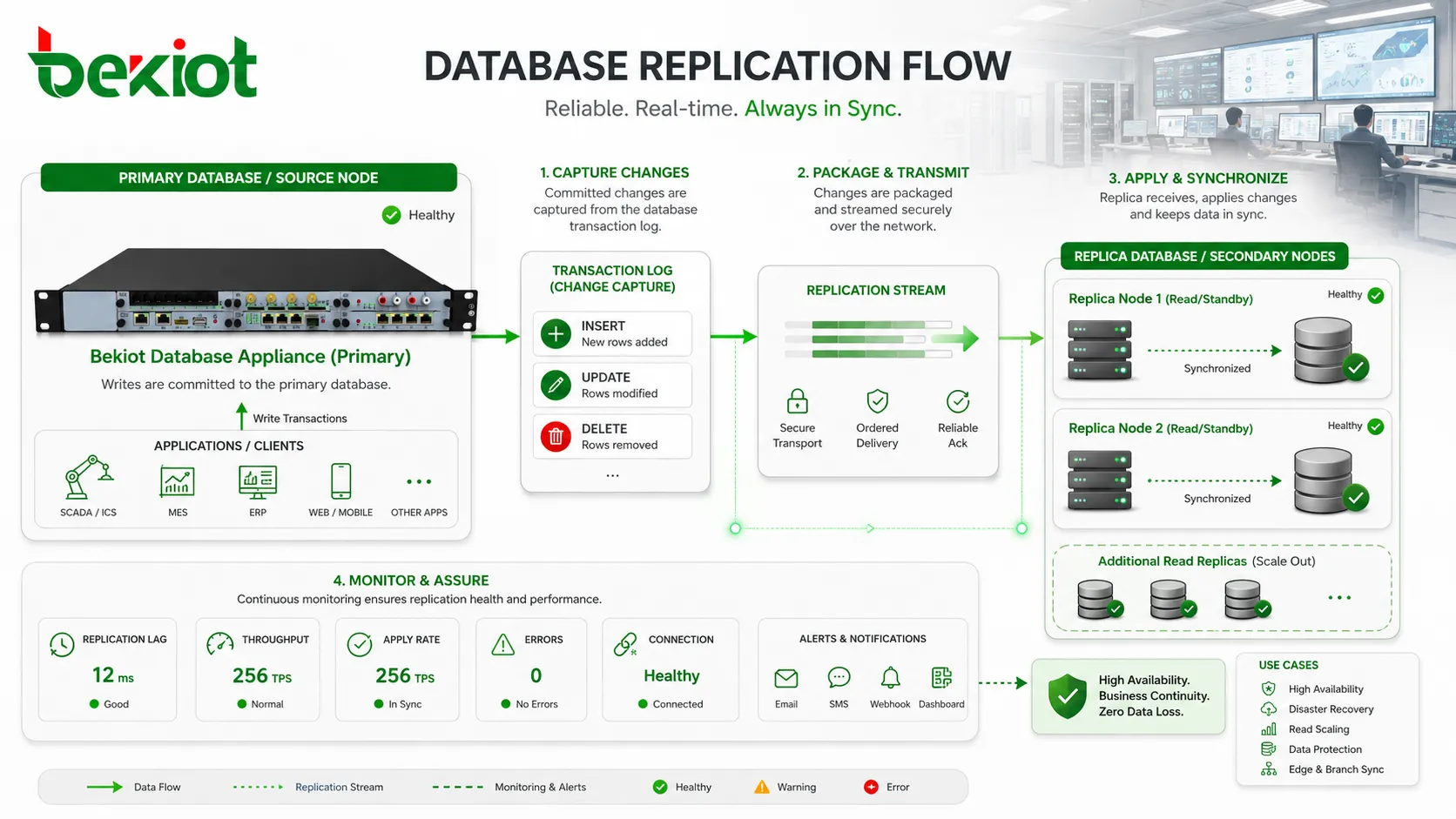
En el centro de la replicación está el seguimiento de cambios. Cuando se inserta, actualiza o elimina información, la base de datos debe identificar el cambio, empaquetarlo de forma fiable, enviarlo a otro nodo y aplicarlo en el orden correcto. Si este proceso se maneja mal, la réplica puede quedar inconsistente. Si es demasiado lento, la réplica se retrasa. Si no se supervisa, el equipo puede descubrir el problema solo cuando necesita recuperar el servicio.
Un buen diseño de replicación responde preguntas prácticas: qué datos deben copiarse, con qué rapidez deben llegar, quién puede escribir, cómo se resuelven los conflictos, qué ocurre durante una falla de red y cómo deben comportarse las aplicaciones cuando un nodo no está disponible. Estas respuestas determinan si la replicación será una herramienta de resiliencia o una fuente oculta de confusión.
Qué se mueve realmente entre los nodos de base de datos
La replicación no siempre es una simple copia de archivos. En la mayoría de los sistemas de producción, la base de datos no vuelve a enviar todo el conjunto de datos cada vez que cambia un registro. En su lugar, captura el cambio y transfiere solo lo necesario para reproducirlo en la réplica. Esto reduce el uso de ancho de banda y permite que la réplica permanezca cerca del estado de origen sin reconstruirse desde cero.
Un método común es la replicación basada en registros. La base primaria guarda los cambios en registros de transacciones, registros binarios, registros de escritura anticipada o registros de rehacer. La réplica lee esos registros y aplica las mismas operaciones en secuencia. Este método se usa mucho porque el registro ya representa el orden autorizado de los cambios de la base de datos.
Otro método es la replicación basada en sentencias, en la que se envían sentencias SQL a la réplica. Puede ser más simple en algunos sistemas, pero puede generar diferencias si la sentencia depende de funciones no deterministas, valores de tiempo, números aleatorios o comportamiento propio del entorno. La replicación basada en filas evita muchos de estos problemas al enviar los cambios reales de las filas, no solo la sentencia que los produjo.
Algunos sistemas usan replicación por instantáneas. Se toma una copia completa o parcial de los datos en un momento determinado y se entrega a otra ubicación. Esto es útil para sincronización inicial, bases de informes o distribución periódica de datos. Sin embargo, las instantáneas por sí solas no bastan para sistemas que necesitan actualizaciones casi en tiempo real.
Las arquitecturas modernas también pueden usar captura de datos de cambio, o CDC. CDC extrae cambios de la base de datos y los envía a plataformas analíticas, índices de búsqueda, colas de mensajes o lagos de datos. En ese caso, la replicación ya no solo mantiene otra copia de base de datos; se convierte en parte de la tubería de movimiento de datos de la organización.
Replicación primaria-réplica en la operación diaria
El patrón más conocido es la replicación primaria-réplica. Un nodo de base de datos acepta escrituras, mientras una o varias réplicas reciben copias de los cambios. Las aplicaciones envían operaciones de inserción, actualización y eliminación a la primaria. Las consultas de solo lectura pueden enviarse a las réplicas si la aplicación y la arquitectura lo permiten.
Este patrón es fácil de entender y se usa ampliamente porque mantiene clara la propiedad de escritura. La primaria es la autoridad para los cambios y las réplicas siguen su estado. Si una réplica falla, la primaria puede seguir operando. Si falla la primaria, una réplica puede promoverse como nueva primaria, según el diseño de conmutación.
El beneficio es la separación práctica de cargas. Las escrituras transaccionales, operaciones de usuario y actualizaciones de negocio permanecen en la primaria, mientras informes, paneles, búsquedas o servicios con muchas lecturas pueden usar réplicas. Esto reduce presión sobre la base principal y mejora tiempos de respuesta.
Aun así, las aplicaciones deben entender que las réplicas no siempre están completamente actualizadas, sobre todo en replicación asíncrona. Si un usuario escribe en la primaria y lee inmediatamente desde una réplica retrasada, quizá no vea el cambio más reciente. No siempre es una falla; es una compensación de diseño que debe tratarse con cuidado.
Patrones multi-primarios y distribuidos
Algunos entornos requieren más de un nodo con capacidad de escritura. En la replicación multi-primaria, varios nodos aceptan escrituras y luego replican los cambios entre sí. Esto puede apoyar sedes distribuidas, operaciones regionales, escritura local o alta disponibilidad entre centros de datos. Suena atractivo, pero es más complejo que la replicación primaria-réplica.
El principal reto es el conflicto. Si dos nodos actualizan el mismo registro al mismo tiempo, el sistema debe decidir qué cambio gana o cómo se fusionan los cambios. Las reglas pueden basarse en marcas de tiempo, números de versión, lógica de aplicación, prioridad del nodo o resolución manual. Un manejo deficiente de conflictos daña la calidad de los datos.
La replicación distribuida también se usa en sistemas de borde, tiendas, sitios industriales, aplicaciones móviles u operaciones remotas donde los datos locales deben seguir disponibles aunque la red central sea inestable. Un nodo local puede guardar y actualizar datos temporalmente y sincronizarlos con el sistema central después. Esto mejora la continuidad local, pero exige reglas de sincronización estrictas.
Los diseños multi-primarios solo deberían elegirse cuando la necesidad del negocio justifique la complejidad. Para muchas aplicaciones, una primaria de escritura con réplicas de lectura es más fácil de operar. Cuando realmente se requieren escrituras locales en varios lugares, la gestión de conflictos, la propiedad de datos y la supervisión deben diseñarse antes del despliegue.
Replicación síncrona y asíncrona
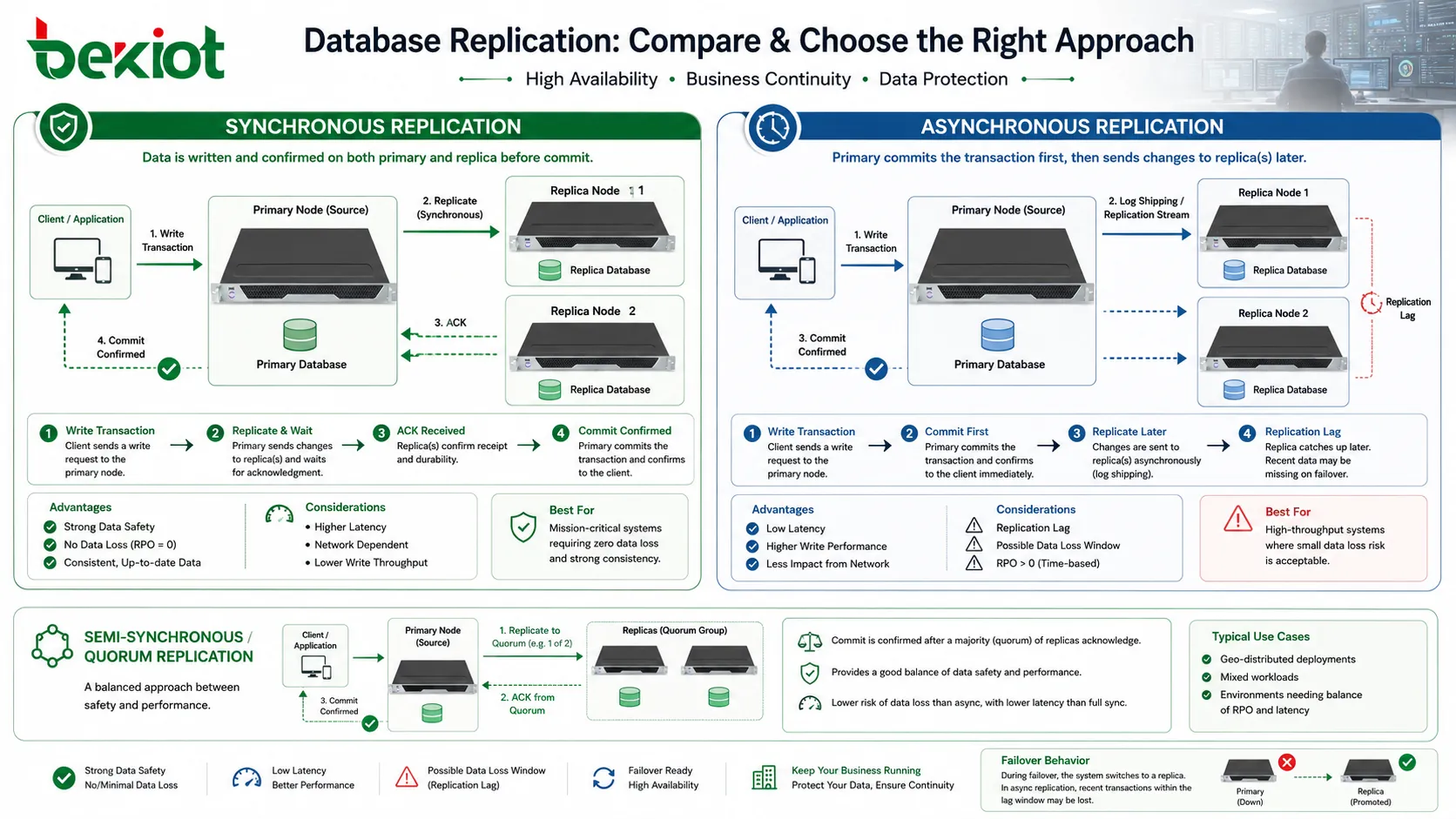
El momento de la replicación es una de las decisiones de diseño más importantes. En la replicación síncrona, una transacción no se considera plenamente confirmada hasta que otro nodo de base de datos confirma el cambio. Esto mejora la seguridad de los datos porque la réplica tiene el cambio antes de que la aplicación reciba confirmación de éxito. Si la primaria falla poco después, es más probable que el dato confirmado exista en otro nodo.
El costo es la latencia. Si la réplica está lejos o la red es lenta, la primaria debe esperar más para completar la transacción. Esto puede afectar el tiempo de respuesta de la aplicación. La replicación síncrona suele usarse cuando la tolerancia a pérdida de datos es muy baja y el enlace entre nodos es lo bastante fiable.
En la replicación asíncrona, la primaria confirma primero la transacción y envía el cambio a las réplicas después. Esto mejora el rendimiento de escritura porque la aplicación no espera confirmación remota. Es común cuando las réplicas se usan para informes, escalado de lectura o recuperación ante desastres a larga distancia.
La compensación es el retraso de replicación. Si la primaria falla antes de que los cambios lleguen a la réplica, algunas transacciones recientes pueden perderse o requerir recuperación desde registros. Por eso la replicación asíncrona debe alinearse con objetivos claros de recuperación. El equipo debe saber cuánta pérdida de datos es aceptable y con qué rapidez debe ponerse al día la réplica.
Algunos sistemas usan métodos semisíncronos o basados en quórum para equilibrar rendimiento y seguridad. Estas soluciones confirman la transacción después de que una o varias réplicas respondan, pero no necesariamente esperan a todas. La mejor opción depende del riesgo de negocio, la calidad de red, el volumen transaccional y los requisitos de recuperación.
Ventajas de disponibilidad y conmutación por error
El beneficio más directo de la replicación es mejorar la disponibilidad. Si la base primaria falla, una réplica puede promoverse para continuar el servicio. Sin replicación, la recuperación puede depender de restaurar una copia de seguridad, lo que tarda más y puede perder más datos recientes. La replicación da al equipo una copia activa o casi activa para restaurar con mayor rapidez.
La conmutación por error puede ser manual o automática. La conmutación manual da más control a los administradores, útil en entornos complejos o cuando debe evitarse el riesgo de cerebro dividido. La automática reduce el tiempo de caída, pero debe diseñarse con cuidado para que dos nodos no se crean primarios a la vez. En alta disponibilidad, la decisión suele apoyarse en monitoreo, comprobaciones de salud, reglas de quórum o gestión de clúster.
La disponibilidad también depende del comportamiento de la aplicación. Promover una réplica no basta si las aplicaciones no pueden reconectarse, si el DNS tarda en actualizarse, si los pools de conexión siguen usando la dirección fallida o si los usuarios deben cambiar ajustes manualmente. La replicación debe planearse junto con enrutamiento de aplicaciones, balanceadores, cadenas de conexión, descubrimiento de servicio y procedimientos operativos.
Una réplica también puede apoyar el mantenimiento. Durante actualizaciones, parches, sustitución de hardware o migraciones de almacenamiento, algunas cargas pueden moverse a otro nodo. Esto reduce paradas planificadas y da más flexibilidad a los administradores. Los mejores diseños sirven tanto para recuperación de emergencia como para mantenimiento rutinario.
Escalado de lectura sin cambiar el modelo de datos principal
Muchos sistemas de base de datos se sobrecargan no porque las escrituras sean excesivas, sino porque las consultas de lectura crecen con el tiempo. Paneles, informes, páginas de búsqueda, portales de clientes, herramientas de monitoreo y llamadas API pueden leer de la misma base. Si todas las lecturas llegan a la primaria, las transacciones normales se ralentizan. La replicación permite distribuir lecturas entre réplicas.
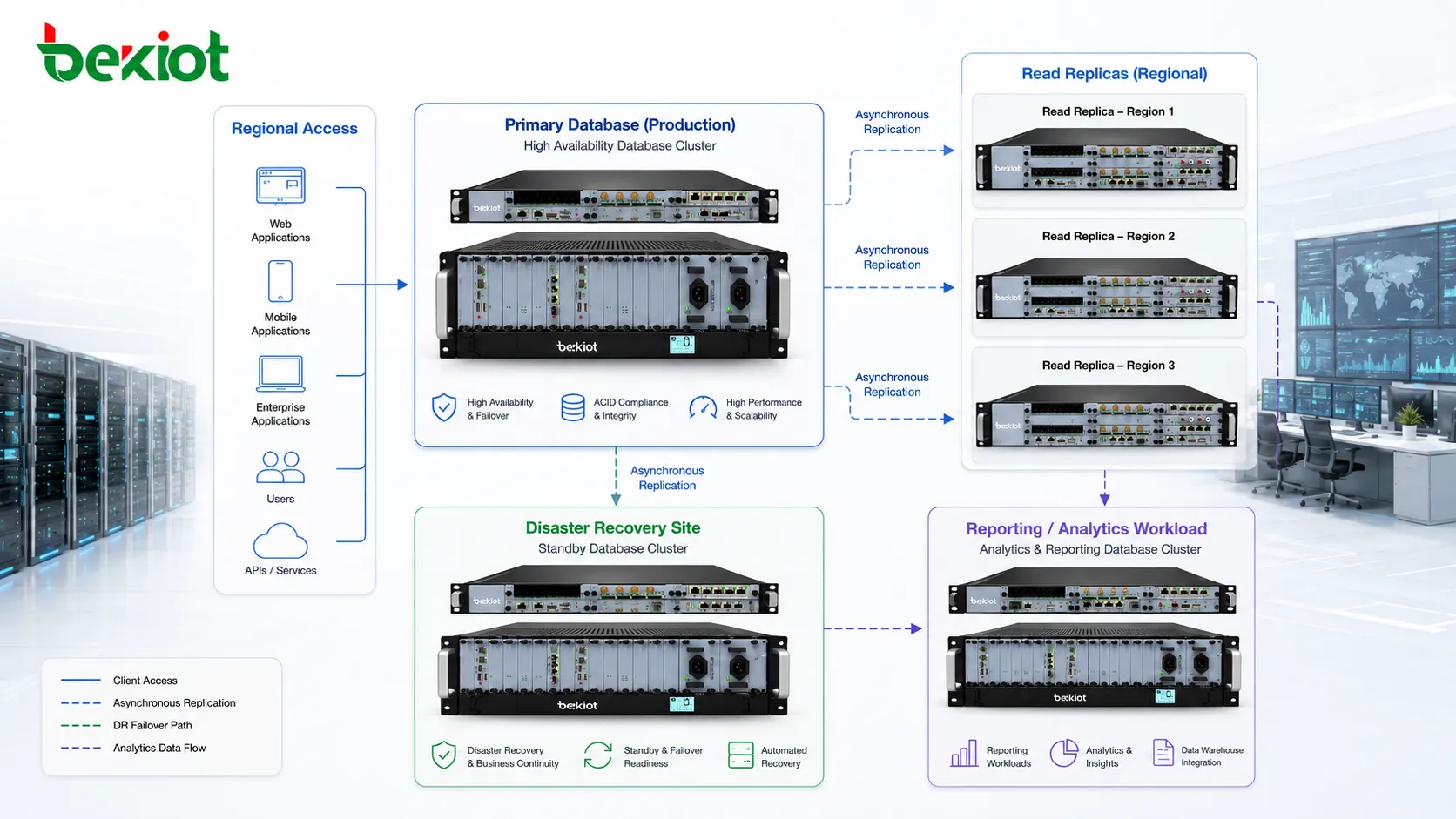
Las réplicas de lectura se usan a menudo para informes y análisis. Las consultas largas pueden ejecutarse en réplicas sin bloquear ni frenar el trabajo transaccional crítico en la primaria. Esto es útil cuando los equipos de negocio necesitan informes frecuentes y la base de producción debe seguir respondiendo a usuarios.
La separación de lectura y escritura en la aplicación también mejora la escalabilidad. La aplicación envía escrituras a la primaria y algunas lecturas a réplicas. Debe hacerse con cuidado porque las réplicas pueden retrasarse. Los datos que requieren consistencia inmediata quizá deban leerse de la primaria; los datos que toleran leve retraso son adecuados para réplicas.
Este enfoque aumenta la capacidad de lectura sin rediseñar todo el modelo de datos. En lugar de migrar de inmediato a otra arquitectura, el equipo puede añadir réplicas, optimizar el enrutamiento de consultas y separar cargas de informes. Suele ser un paso intermedio práctico en el escalado de bases de datos.
Recuperación ante desastres y resiliencia geográfica
La replicación se usa con frecuencia para recuperación ante desastres. Una réplica en otro centro de datos, región de nube o ubicación física puede proteger contra incendios, cortes de energía, fallas de red, problemas de almacenamiento o desastres de sitio. Si la ubicación primaria queda fuera de servicio, la réplica remota puede ofrecer una ruta de recuperación.
La replicación geográfica requiere planificación cuidadosa porque la distancia aumenta la latencia. La replicación síncrona a larga distancia puede ser demasiado lenta para algunas aplicaciones. La asíncrona es más común para recuperación remota, pero introduce posible pérdida de datos si el sitio primario falla antes de copiar todos los cambios.
La planificación debe definir el objetivo de tiempo de recuperación y el objetivo de punto de recuperación. RTO describe cuán rápido debe restaurarse el servicio. RPO describe cuánta pérdida de datos es aceptable. Un sistema con RPO estricto puede necesitar protección más síncrona o retraso muy bajo. Un sistema con RPO flexible puede usar replicación asíncrona con verificaciones periódicas.
La recuperación ante desastres también necesita pruebas. Una réplica que nunca se promovió, nunca se revisó con la aplicación o nunca se restauró en condiciones realistas quizá no sea fiable durante un desastre real. La replicación aporta la base técnica; los simulacros demuestran si el proceso funciona.
Localidad de datos y rendimiento regional
La replicación puede acercar los datos a usuarios, sucursales o aplicaciones regionales. Cuando los usuarios en distintas ubicaciones leen desde una réplica cercana, el tiempo de respuesta puede mejorar. Esto sirve para aplicaciones globales, servicios multirregión, cadenas minoristas, redes logísticas, plataformas financieras y sistemas empresariales distribuidos.
Las réplicas regionales también reducen presión sobre enlaces centrales. En lugar de enviar cada consulta por una conexión de larga distancia, usuarios o servicios locales pueden leer desde una copia cercana. Esto resulta especialmente útil cuando el tráfico de lectura es alto y los requisitos de frescura de datos son manejables.
La localidad de datos también apoya informes locales. Una oficina regional puede analizar sus transacciones, inventario, registros de servicio o datos operativos sin cargar constantemente la base central de producción. Una base replicada local puede proporcionar ese acceso mientras el sistema central se centra en transacciones críticas.
Sin embargo, la replicación regional debe respetar las reglas de gobierno de datos. Algunos datos pueden estar restringidos por leyes de privacidad, políticas internas, contratos de clientes o regulaciones del sector. Copiar datos a otra región o país puede requerir aprobación, cifrado, control de acceso o minimización de datos. La replicación debe mejorar el rendimiento sin debilitar el gobierno.
La copia de seguridad no es lo mismo que la replicación
Replicación y copia de seguridad suelen mencionarse juntas, pero resuelven problemas diferentes. La replicación mantiene otra copia de base de datos actualizada, normalmente para disponibilidad, rendimiento o distribución de datos. La copia de seguridad crea copias históricas recuperables que pueden restaurarse tras borrados, corrupción, ransomware, cambios accidentales o pérdida de datos a largo plazo.
Una réplica puede copiar fielmente un error. Si un usuario borra registros importantes en la primaria, la replicación puede eliminarlos rápidamente en la réplica. Si una aplicación escribe datos corruptos, la réplica puede recibir el mismo estado corrupto. En ese caso, la replicación no protege a la organización salvo que existan recuperación a punto en el tiempo, replicación retardada o copias de seguridad.
Las copias de seguridad tardan más en restaurarse, pero son más seguras para recuperación histórica. Permiten volver a un punto anterior en el tiempo. La replicación es más rápida para continuidad del servicio, pero no siempre ofrece retroceso histórico. Una estrategia sólida normalmente incluye replicación y copias de seguridad, no una u otra.
La diferencia debe quedar clara en la planificación operativa. Si el objetivo es conmutación rápida, la replicación es útil. Si el objetivo es recuperar datos de la semana pasada, se necesita copia de seguridad. Si se desean ambos objetivos, la organización debe diseñar y probar ambos procesos con regularidad.
Supervisión de la salud de la replicación
La replicación debe supervisarse continuamente. Una réplica con horas de retraso puede aparecer en línea, pero ser inútil para failover o inexacta para informes. Los puntos habituales de supervisión incluyen retraso de replicación, estado de la réplica, progreso de envío de registros, velocidad de aplicación, errores, conectividad, uso de disco, demora transaccional y eventos de sincronización fallidos.
El retraso de replicación es especialmente importante. Mide la demora entre un cambio en la primaria y su disponibilidad en la réplica. Un pequeño retraso puede aceptarse para informes. Un retraso grande puede romper supuestos de aplicación o aumentar el riesgo de pérdida de datos durante failover. Los umbrales aceptables deben definirse por caso de uso.
El almacenamiento y la capacidad también deben vigilarse. La replicación puede generar registros, archivos temporales, relay logs, archivos de archivo o datos de preparación. Si se agota el disco, la replicación puede detenerse. Si la réplica tiene pocos recursos, quizá no aplique cambios con suficiente rapidez en picos de carga. Una réplica debe dimensionarse para su carga, no tratarse como un repuesto ligero.
Las alertas operativas deben ser útiles. No basta con indicar que la replicación falló; la alerta debería ayudar a distinguir si la causa es conectividad, autenticación, posición de registro, capacidad de disco, desajuste de esquema, permisos o escrituras en conflicto. Cuanto antes se identifique la causa, antes se restaura el flujo de datos.
Seguridad y control de acceso
La replicación aumenta el número de lugares donde existen datos sensibles. Cada réplica debe protegerse con la misma seriedad que la base primaria. Si una réplica es menos segura, puede convertirse en el camino más fácil para una fuga de datos. La planificación debe incluir cifrado, control de acceso, auditoría, restricciones de red y gestión de credenciales para cada nodo.
El tráfico de replicación debe protegerse, especialmente cuando cruza centros de datos, regiones de nube, redes públicas o enlaces de terceros. El cifrado en tránsito ayuda a evitar interceptaciones. La autenticación entre nodos impide que sistemas no autorizados se unan a la relación de replicación. La segmentación de red reduce la exposición frente a sistemas no relacionados.
Los permisos deben revisarse por separado para las réplicas. Una réplica de informes puede ser de solo lectura para analistas, pero eso no significa que todas las tablas deban ser visibles para todos. Los campos sensibles pueden requerir enmascaramiento, filtrado o políticas de acceso separadas. En algunos casos, una réplica solo debe contener los datos necesarios para su propósito.
El acceso administrativo también necesita control. Los usuarios que pueden detener la replicación, promover una réplica, cambiar filtros o modificar credenciales tienen mucho poder. Estas acciones deben registrarse y limitarse a personal autorizado. La replicación forma parte del perímetro de confianza de la base de datos, no es solo un movimiento de datos en segundo plano.
Errores comunes durante el despliegue
Un error frecuente es desplegar replicación sin definir el propósito real. Si el objetivo es disponibilidad, el diseño debe incluir procedimiento de failover y reconexión de aplicaciones. Si el objetivo es informar, debe manejar carga de consultas y frescura de datos. Si el objetivo es recuperación ante desastres, debe incluir ubicación remota, RTO, RPO y simulacros. Un objetivo vago produce una arquitectura vaga.
Otro error es suponer que la réplica siempre está actualizada. Las réplicas asíncronas pueden retrasarse. Escrituras intensas, inestabilidad de red, discos lentos, cambios de esquema o transacciones largas pueden demorar la replicación. Las aplicaciones que leen de réplicas deben diseñarse con este retraso en mente.
Algunos equipos no prueban la promoción. Crean réplicas, pero nunca practican el cambio hacia ellas. En una emergencia descubren problemas de permisos, conexión de aplicaciones, tareas faltantes, configuración incompleta o datos inconsistentes. El failover debe probarse antes de necesitarlo.
Los filtros de replicación también pueden generar confusión. Si solo se replican ciertas tablas o bases, el equipo debe saber exactamente qué se incluye y qué se excluye. Un equipo de informes puede asumir que todos los datos están disponibles cuando solo se copia parte del esquema. La documentación clara evita supuestos falsos.
Por último, muchas implantaciones subestiman el mantenimiento. La replicación debe sobrevivir actualizaciones, cambios de esquema, renovación de certificados, rotación de contraseñas, crecimiento de almacenamiento, cambios de red y diferencias de versión. No es una función de configurar y olvidar. Necesita un responsable.
Cuándo aporta más valor la replicación
La replicación aporta más valor cuando la organización necesita claramente disponibilidad, escalado de lectura, recuperación ante desastres, distribución de datos o separación de cargas. Es menos útil cuando la base es pequeña, la tolerancia a caídas es alta, el tráfico de lectura es bajo y la recuperación desde backup es suficiente. Como toda decisión de arquitectura, debe ajustarse al problema.
Para sistemas críticos de negocio, puede reducir el tiempo de inactividad y ampliar opciones de recuperación. Para aplicaciones en crecimiento, puede alejar informes y lecturas de la primaria. Para organizaciones distribuidas, puede apoyar acceso regional. Para equipos de datos, puede entregar información operativa a sistemas analíticos sin perturbar la producción.
Los diseños más fuertes suelen ser modestos y claros. Definen qué nodo acepta escrituras, qué nodos atienden lecturas, cómo se supervisa el retraso, cómo funciona el failover, cómo se mantienen los backups y quién es responsable de la relación de replicación. La complejidad debe añadirse solo cuando exista una razón de negocio suficiente.
La replicación no es una copia mágica de seguridad. Es una forma disciplinada de mantener datos disponibles en más de un lugar. Sus beneficios aparecen cuando el diseño técnico, el comportamiento de la aplicación, la supervisión, la seguridad y el proceso de recuperación se planifican juntos.
Preguntas frecuentes
¿La replicación de bases de datos se usa principalmente para backup?
No. La replicación puede apoyar la recuperación, pero no sustituye a las copias de seguridad. Una réplica puede copiar eliminaciones accidentales o datos corruptos de la primaria. Los backups siguen siendo necesarios para recuperación histórica y restauración a un punto en el tiempo.
¿Qué es el retraso de replicación?
Es la demora entre la confirmación de un cambio en la base primaria y la aparición del mismo cambio en la réplica. Es común en replicación asíncrona y debe supervisarse cuando las réplicas se usan para lectura o failover.
¿Las aplicaciones pueden escribir en réplicas?
En diseños primaria-réplica, las réplicas suelen ser de solo lectura. Los sistemas multi-primarios permiten escrituras en más de un nodo, pero requieren gestión de conflictos y mayor control operativo. El modelo correcto depende de los requisitos de consistencia de la aplicación.
¿La replicación mejora el rendimiento de la base de datos?
Puede mejorar el rendimiento al mover lecturas, informes y análisis fuera de la primaria. No acelera automáticamente todas las cargas. Los sistemas con muchas escrituras pueden necesitar índices, optimización de consultas, particionamiento, mejor hardware o cambios de arquitectura.
¿Qué debe probarse antes de confiar en la replicación?
Deben probarse la sincronización inicial, el retraso bajo carga, el failover, la promoción de réplicas, la reconexión de aplicaciones, la recuperación desde backup, las alertas, los permisos de seguridad y el comportamiento durante interrupciones de red.