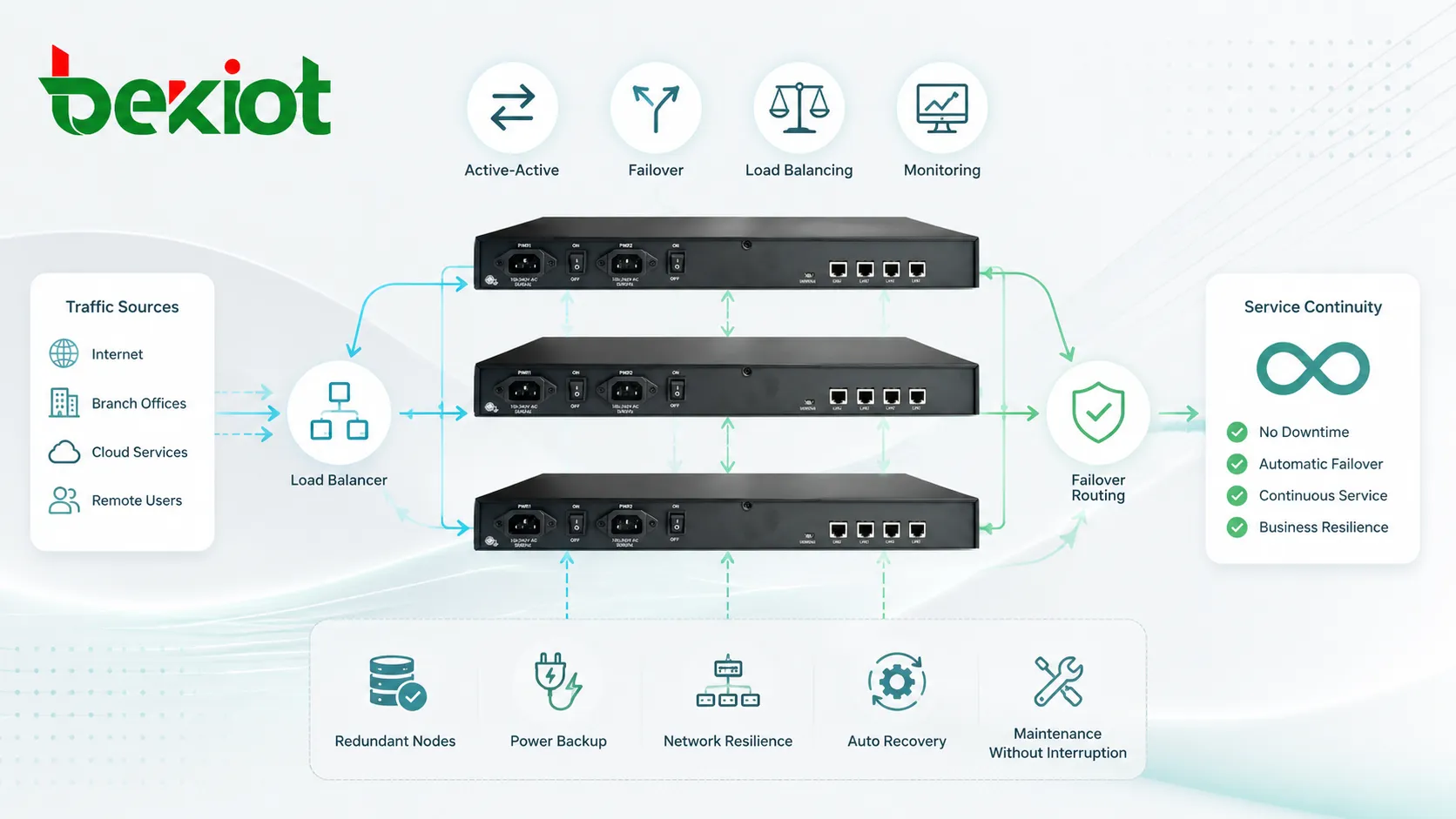
Un clúster es un grupo de computadoras, servidores, gateways, dispositivos, aplicaciones o nodos de red conectados que trabajan juntos como un sistema coordinado. En lugar de depender de una sola unidad independiente, un diseño en clúster distribuye cargas de trabajo, mejora la disponibilidad, permite la conmutación por error y ayuda a mantener los servicios cuando una parte del sistema deja de estar disponible.
La palabra “clúster” se usa en muchos campos, como infraestructura de TI, computación en la nube, bases de datos, plataformas de comunicación, telefonía, redes de radio, automatización industrial, almacenamiento y edge computing. Aunque el diseño técnico cambie, la idea principal es la misma: varios componentes cooperan para que el sistema completo sea más fiable, escalable y fácil de gestionar.

La idea básica detrás de los sistemas agrupados
En un sistema autónomo sencillo, un solo servidor o dispositivo atiende el servicio. Si esa unidad falla, el servicio puede detenerse. Si crece la demanda, puede saturarse. Si se requiere mantenimiento, puede ser difícil evitar una interrupción.
Un sistema en clúster cambia este modelo. Varios nodos se conectan por red y se administran bajo reglas comunes. Un nodo puede atender la carga actual, otro puede quedar como respaldo, o todos pueden procesar tráfico al mismo tiempo. El diseño depende del objetivo del sistema.
Por ejemplo, en una plataforma de comunicaciones empresariales, varios servidores pueden compartir registro de usuarios, enrutamiento de llamadas, grabación o procesamiento de medios. En un entorno Radio over IP, varios gateways pueden conectar canales de radio distribuidos, centros de despacho y redes IP para mantener la comunicación entre sitios.
Cómo trabajan juntos los nodos agrupados
Participación de los nodos
Un nodo es una unidad participante dentro del sistema. Puede ser un servidor físico, una máquina virtual, un gateway, un controlador, un dispositivo de almacenamiento, un terminal de comunicación o un servicio de software. Cada nodo tiene un rol definido y se comunica con los demás por la red.
Algunos nodos pueden realizar la misma función, mientras que otros tienen tareas especializadas. En una base de datos, un nodo puede aceptar escrituras y otros replicar datos. En un sistema de comunicación, un nodo puede manejar señalización y otro medios, grabación o acceso a gateways.
Heartbeat y comprobación de salud
Muchos sistemas en clúster usan señales heartbeat para comprobar si los nodos están vivos. Un heartbeat es un mensaje de estado enviado con regularidad entre nodos o hacia un controlador de gestión. Si un nodo deja de responder, el sistema asume que puede haber fallado.
La comprobación de salud también puede vigilar uso de CPU, memoria, red, respuesta de la aplicación, estado de procesos, espacio en disco, conexión de gateway o registro de dispositivos. Esto ayuda a decidir si un nodo debe seguir recibiendo tráfico o retirarse temporalmente.
Distribución de carga
Algunos clústeres reparten trabajo entre varios nodos mediante balanceadores de carga, políticas de enrutamiento, colas compartidas, bases de datos distribuidas o coordinación de aplicación. El objetivo es evitar que un nodo se sobrecargue mientras otros quedan inactivos.
La distribución de carga mejora rendimiento y escalabilidad, pero exige manejar bien sesiones, sincronización de datos, capacidad de red y monitorización. Un método mal diseñado puede crear carga desigual o inestabilidad del servicio.
Comportamiento de conmutación por error
La conmutación por error significa que, cuando un nodo falla, otro toma su función. En un diseño activo-pasivo, el nodo de respaldo puede permanecer inactivo hasta que falle el principal. En un diseño activo-activo, varios nodos ya atienden tráfico y pueden absorber carga adicional si uno queda fuera de línea.
La conmutación debe probarse con cuidado. Un nodo de respaldo solo es útil si tiene la configuración correcta, datos actuales, acceso de red, capacidad de licencia y estado de aplicación necesarios para continuar el servicio.
Un diseño en clúster no consiste solo en añadir más equipos; consiste en coordinar nodos para manejar fallos, crecimiento y mantenimiento sin interrupciones innecesarias.
Patrones de arquitectura habituales
Diseño activo-pasivo
En un diseño activo-pasivo, un nodo presta el servicio y otro espera como respaldo. Si el nodo activo falla, el pasivo toma el control. Este modelo es común cuando la consistencia y la conmutación controlada son más importantes que usar todos los nodos al mismo tiempo.
Su ventaja es la simplicidad. La desventaja es que los recursos de respaldo pueden estar infrautilizados durante la operación normal. En sistemas críticos, esta capacidad reservada suele ser aceptable porque mejora la continuidad.
Diseño activo-activo
En un diseño activo-activo, varios nodos prestan servicio simultáneamente y el tráfico o las tareas se reparten entre ellos. Si un nodo falla, los demás continúan atendiendo usuarios, aunque la capacidad total pueda reducirse.
Este modelo mejora la utilización de recursos y la escalabilidad. Se usa con frecuencia en plataformas cloud, aplicaciones web, sistemas de comunicación, bases de datos distribuidas y plataformas de varios nodos.
Despliegue con balanceo de carga
Un despliegue con balanceo de carga usa un componente frontal para distribuir tráfico entre varios nodos backend. El balanceador puede aplicar reglas como round-robin, menos conexiones, estado de salud, dirección de origen, prioridad de servicio o ubicación geográfica.
Este diseño es habitual en servicios web, plataformas SIP, API, servidores de aplicaciones, sistemas de medios y portales empresariales. El balanceador también debe diseñarse con redundancia para no convertirse en un punto único de fallo.
Diseño de borde distribuido
Algunos sistemas sitúan nodos en ubicaciones diferentes en lugar de concentrarlos en un solo centro de datos. Es común en comunicaciones de sucursales, sitios industriales, transporte, integración de radio, IoT y seguridad pública.
El borde distribuido reduce la dependencia de un sitio central y mejora la respuesta local. Aun así, requiere sincronización fiable, monitorización remota, controles de seguridad y procedimientos de mantenimiento claros.
Por qué las organizaciones usan este diseño
Mayor disponibilidad
La disponibilidad es una de las razones principales para usar sistemas agrupados. Si una unidad autónoma falla, el servicio puede detenerse. Si existen varios nodos coordinados, otro nodo puede continuar el servicio o asumir la carga afectada.
Esto es importante para plataformas de comunicación, servicios de emergencia, aplicaciones empresariales, sistemas financieros, salud, control industrial y servicios orientados al cliente, donde una caída genera impacto operativo o comercial.
Escalabilidad para crecer
Cuando aumenta la demanda, las organizaciones pueden necesitar más procesamiento, más capacidad de llamadas, más rendimiento de base de datos, más almacenamiento, más canales de gateway o más puntos de servicio. Un clúster permite crecer añadiendo nodos en lugar de sustituir todo el sistema.
La escalabilidad es especialmente valiosa cuando el tráfico cambia con el tiempo. Un sistema puede empezar pequeño y ampliarse a medida que crecen sitios, usuarios, canales, servicios o demanda de clientes.
Mantenimiento con menos interrupción
Los clústeres facilitan el mantenimiento. Los administradores pueden retirar un nodo del servicio, actualizarlo, probarlo y devolverlo a operación mientras otros nodos siguen manejando tráfico.
Esto no elimina la necesidad de planificación. El mantenimiento debe considerar compatibilidad, sincronización, sesiones de usuario, comportamiento de failover y reversión, pero ofrece más flexibilidad que un sistema de un solo nodo.
Mejor utilización de recursos
En sistemas activo-activo o balanceados, varios nodos comparten trabajo. Esto mejora la utilización porque la capacidad no se limita a una sola máquina o dispositivo.
Por ejemplo, varios servidores de aplicaciones pueden atender más usuarios que uno solo; varios gateways de medios pueden soportar más canales de voz; y varios nodos de almacenamiento pueden aportar más capacidad y resiliencia.
Mayor resiliencia del servicio
La resiliencia significa que el sistema puede seguir funcionando bajo presión, fallo parcial, mantenimiento o cambios de tráfico. El clúster distribuye responsabilidades y reduce la dependencia de un componente único.
En entornos de misión crítica, la resiliencia también debe incluir respaldo eléctrico, redundancia de red, separación geográfica, monitorización, endurecimiento de seguridad y procedimientos de recuperación probados.
Componentes técnicos importantes
Configuración compartida
Los nodos necesitan una configuración consistente para comportarse de forma predecible. Esto puede incluir parámetros de red, datos de usuarios, reglas de enrutamiento, certificados, parámetros de servicio, licencias y políticas de aplicación.
Si las configuraciones se desvían, el failover o el reparto de carga pueden volverse poco fiables. La gestión centralizada de configuración o el despliegue automatizado reducen este riesgo.
Sincronización de datos
Algunos sistemas necesitan sincronizar datos entre nodos: sesiones de usuario, estados de llamada, registros de base de datos, estado de colas, registros de dispositivos, buzón de voz, permisos o alarmas.
El diseño de sincronización es crítico. Si los datos no están actualizados, un nodo de respaldo puede tomar el control sin ofrecer el estado esperado; si la sincronización es excesiva, puede añadir sobrecarga.
Quórum y protección contra split-brain
En ciertos clústeres, el quórum se usa para decidir qué nodos pueden tomar decisiones. Esto ayuda a evitar situaciones split-brain, donde dos partes del sistema creen estar activas al mismo tiempo tras una separación de red.
El split-brain puede causar datos conflictivos, control duplicado del servicio o failover inestable. Un buen diseño de quórum, fencing y redundancia de red ayuda a reducir ese riesgo.
Monitorización y alertas
La monitorización es esencial porque un clúster puede ocultar fallos parciales. El servicio puede parecer en línea aunque un nodo, enlace, disco, gateway o proceso haya fallado.
Los administradores deben vigilar salud de nodos, distribución de tráfico, eventos de failover, sincronización, uso de recursos, logs de error e indicadores de nivel de servicio. Las alertas deben indicar no solo que algo falló, sino qué componente requiere atención.
Control de seguridad
Los sistemas agrupados suelen tener más comunicación interna que los sistemas aislados. Los nodos pueden intercambiar estado, configuración, datos, credenciales o mensajes de control, y esos canales deben protegerse con autenticación, cifrado, segmentación y control de acceso.
El acceso administrativo también debe controlarse. Si un nodo se ve comprometido, el atacante no debería obtener automáticamente el control de todo el entorno.
Escenarios de comunicación y gateways
En redes de comunicación, el concepto de clúster aparece en plataformas PBX, servidores SIP, sistemas de despacho, gateways, redes Radio over IP, plataformas de grabación, contact centers y sistemas de comunicación de emergencia. Estos servicios necesitan continuidad porque los fallos de comunicación afectan operaciones diarias, seguridad o atención al cliente.
Para integración de radio y despacho, un diseño de gateways en clúster puede conectar múltiples canales de radio, redes IP y centros de control. Un grupo de gateways puede ofrecer expansión de canales, failover, acceso remoto y administración centralizada entre sitios.
Por ejemplo, el gateway en clúster de la serie BK-ROIP de Becke Telcom puede usarse en proyectos donde los sistemas de radio deben conectarse con plataformas de despacho IP, centros de mando multisede o redes empresariales. En estos escenarios, la capa de gateway une voz de radio, transmisión IP y flujos operativos de despacho, manteniendo la solución escalable y más fácil de gestionar.
Aplicaciones en distintos sectores
Sistemas de TI empresariales
Las empresas usan servidores en clúster para aplicaciones de negocio, bases de datos, servicios de archivos, correo, identidad y portales internos. Estos sistemas deben permanecer disponibles durante fallos de hardware, actualizaciones o picos de tráfico.
En TI empresarial, los objetivos principales son tiempo de actividad, rendimiento predecible, mantenimiento más sencillo y continuidad del negocio. El diseño debe ajustarse a la importancia de cada aplicación.
Nube y centros de datos
Las plataformas cloud dependen fuertemente de recursos agrupados. Nodos de cómputo, almacenamiento, controladores de red y servicios se distribuyen para que las cargas escalen y se recuperen de fallos.
En centros de datos, este diseño soporta alta disponibilidad, agrupación de recursos, virtualización, orquestación de contenedores y migración automatizada de cargas.
Telefonía y comunicaciones unificadas
Las plataformas de voz pueden usar servidores agrupados para registro, enrutamiento de llamadas, servicios de medios, buzón de voz, grabación, colas de contact center o control de troncales SIP. Así se reduce el riesgo de que un fallo de servidor interrumpa a todos los usuarios.
En negocios multisede, los nodos de comunicación distribuidos también mejoran la supervivencia local. Una sucursal puede mantener comunicación interna aunque la conexión con el sitio central esté temporalmente caída.
Instalaciones industriales y energéticas
Plantas industriales, utilities, sitios de petróleo y gas, minas, puertos y centrales eléctricas pueden usar sistemas agrupados para monitorización, despacho, alarmas, integración de radio, control de acceso y comunicación de sala de control.
En estos entornos, el tiempo de actividad y la resiliencia son especialmente importantes. El sistema debe planificarse junto con energía redundante, protección de red, condiciones ambientales y procedimientos de mantenimiento.
Seguridad pública y respuesta a emergencias
Las organizaciones de emergencia pueden usar servidores de comunicación agrupados, plataformas de despacho, gateways de radio, sistemas de grabación y herramientas de notificación. El objetivo es mantener la comunicación cuando aumenta la demanda o falla parte de la infraestructura.
Estos sistemas deben probarse en condiciones realistas, con failover, energía de respaldo, alto volumen de llamadas, coordinación multiagencia e interrupciones de red.

Planificación de la configuración adecuada
Definir primero el objetivo del servicio
Antes de elegir un diseño en clúster, la organización debe definir el objetivo del servicio: alta disponibilidad, reparto de carga, redundancia geográfica, flexibilidad de mantenimiento, expansión de canales, recuperación ante desastres o integración multisede.
Cada objetivo conduce a una arquitectura distinta. Un sistema diseñado principalmente para failover no siempre es igual a otro diseñado para escalado de rendimiento.
Identificar puntos de fallo
Un clúster aún puede fallar si otros componentes no son redundantes. Alimentación, switches, routers, almacenamiento, firewalls, balanceadores, licencias, bases de datos y plataformas de gestión pueden ser puntos únicos de fallo.
La planificación debe ir más allá de los nodos. Debe revisarse la ruta completa del servicio.
Comprobar compatibilidad de aplicaciones
No todas las aplicaciones o dispositivos están diseñados para clustering. Algunos requieren licencias especiales, soporte de base de datos, lógica de sincronización, almacenamiento compartido o arquitectura específica del proveedor.
La compatibilidad debe confirmarse antes del despliegue. Un diseño correcto en papel puede fallar si la aplicación no soporta operación activo-activo o sincronización de estado.
Probar el comportamiento de recuperación
El failover debe probarse antes de producción. Las pruebas deben incluir fallo de nodo, interrupción de red, reinicio de servicio, retraso de base de datos, pérdida de energía, modo de mantenimiento y retorno a operación normal.
Las pruebas de recuperación revelan problemas ocultos como failover lento, sincronización incompleta, enrutamiento incorrecto o pérdida de sesiones de usuario.
Desafíos comunes
Un desafío común es la complejidad. Más nodos, más enlaces y más reglas de sincronización crean más elementos que configurar y monitorizar. Un clúster mal administrado puede ser más difícil de diagnosticar que un sistema autónomo simple.
Otro desafío es la falsa confianza. Algunas organizaciones asumen que añadir nodos crea alta disponibilidad automáticamente. En realidad, el diseño completo debe incluir redundancia, monitorización, lógica de failover, recuperación probada y mantenimiento experto.
El coste también importa. Nodos adicionales, licencias, almacenamiento, switches, gateways, módulos de software y soporte pueden elevar el coste del proyecto. La inversión debe corresponder al riesgo de negocio por caída o falta de capacidad.
Un sistema en clúster debe diseñarse según requisitos reales de servicio, no bajo la idea de que más nodos significan automáticamente más fiabilidad.
Mantenimiento y operación
El mantenimiento regular debe incluir comprobaciones de salud de nodos, revisión de configuración, validación de copias, pruebas de failover, análisis de logs, monitorización de rendimiento y actualizaciones de seguridad. Un clúster que nunca se prueba puede fallar cuando más se necesita.
Los administradores también deben vigilar la deriva de configuración. Si un nodo se actualiza manualmente y otro no, el comportamiento puede volverse inconsistente. Las herramientas automáticas y el control de cambios documentado reducen este riesgo.
La capacidad debe revisarse con el tiempo. Si un nodo falla, los nodos restantes deben tener capacidad suficiente para cargas críticas. De lo contrario, el failover puede mantener el servicio en línea con un rendimiento inaceptable.
Cómo elegir una solución adecuada
La solución correcta depende del tipo de carga, importancia del servicio, escala de usuarios, distribución de sitios, requisitos de recuperación y presupuesto. Una aplicación de oficina pequeña puede necesitar solo respaldo básico, mientras que una plataforma de comunicaciones carrier-grade puede requerir redundancia activo-activo multisede.
En proyectos de comunicación, la selección debe considerar capacidad de llamadas, capacidad de canales, compatibilidad SIP, manejo de medios, integración de radio, redundancia de gateways, gestión centralizada, registros y comportamiento de failover. Si la solución conecta radio, despacho IP y comunicaciones empresariales, la escalabilidad del gateway y la resiliencia por sitio son especialmente importantes.
Las organizaciones también deben considerar el mantenimiento a largo plazo. La solución debe ser comprensible, documentada, monitorizada y soportable por el equipo responsable de la operación diaria.
FAQ
¿Puede una pequeña empresa usar sistemas en clúster?
Sí. Una pequeña empresa quizá no necesite una plataforma compleja de muchos nodos, pero puede usar diseños simples de alta disponibilidad como firewalls redundantes, servidores de respaldo, almacenamiento replicado o servicios administrados en la nube.
¿El clustering siempre requiere hardware idéntico?
No siempre. Algunos sistemas requieren hardware o versiones de software idénticas, mientras que otros permiten nodos mixtos. Sin embargo, diferencias de capacidad o versión pueden afectar rendimiento, failover y soporte.
¿Cuál es la diferencia entre redundancia y clustering?
Redundancia significa tener componentes de respaldo. Clustering es un diseño coordinado en el que varios componentes trabajan bajo una lógica compartida. Un clúster suele incluir redundancia, pero la redundancia por sí sola no siempre significa que el sistema sea un clúster.
¿Por qué el failover a veces tarda más de lo esperado?
El failover puede retrasarse por temporizadores de salud, sincronización de base de datos, arranque de servicios, convergencia de rutas, caché DNS, recuperación de sesiones o aprobaciones manuales. Estos factores deben probarse antes de producción.
¿Qué debe documentarse después del despliegue?
La documentación debe incluir roles de nodos, direcciones IP, dependencias de servicio, reglas de failover, cuentas de administración, umbrales de monitorización, procedimientos de respaldo, ventanas de mantenimiento, pasos de recuperación y responsabilidades de contacto.