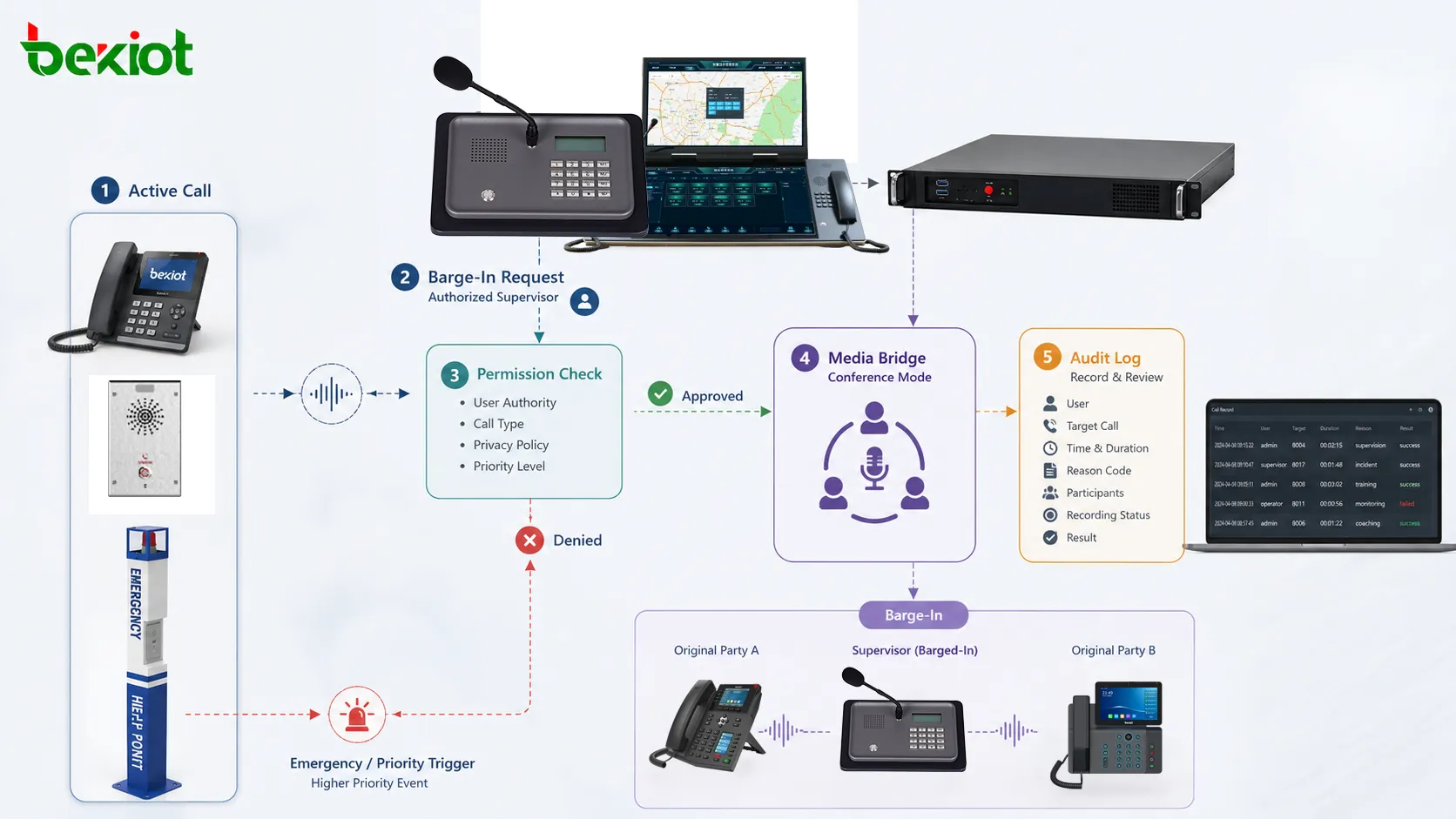
Un SLA resulta útil cuando las expectativas de servicio deben pasar de una promesa verbal a una operación medible.
El cliente puede esperar disponibilidad estable, recuperación rápida, respuesta de soporte clara, ventanas de mantenimiento previsibles e informes transparentes. El proveedor necesita límites de responsabilidad, metas medibles, reglas de escalación y evaluación basada en evidencia. El SLA conecta ambos lados al definir qué se entrega, cómo se mide y qué ocurre si no se alcanza el nivel acordado.
La lógica operativa detrás de compromisos medibles
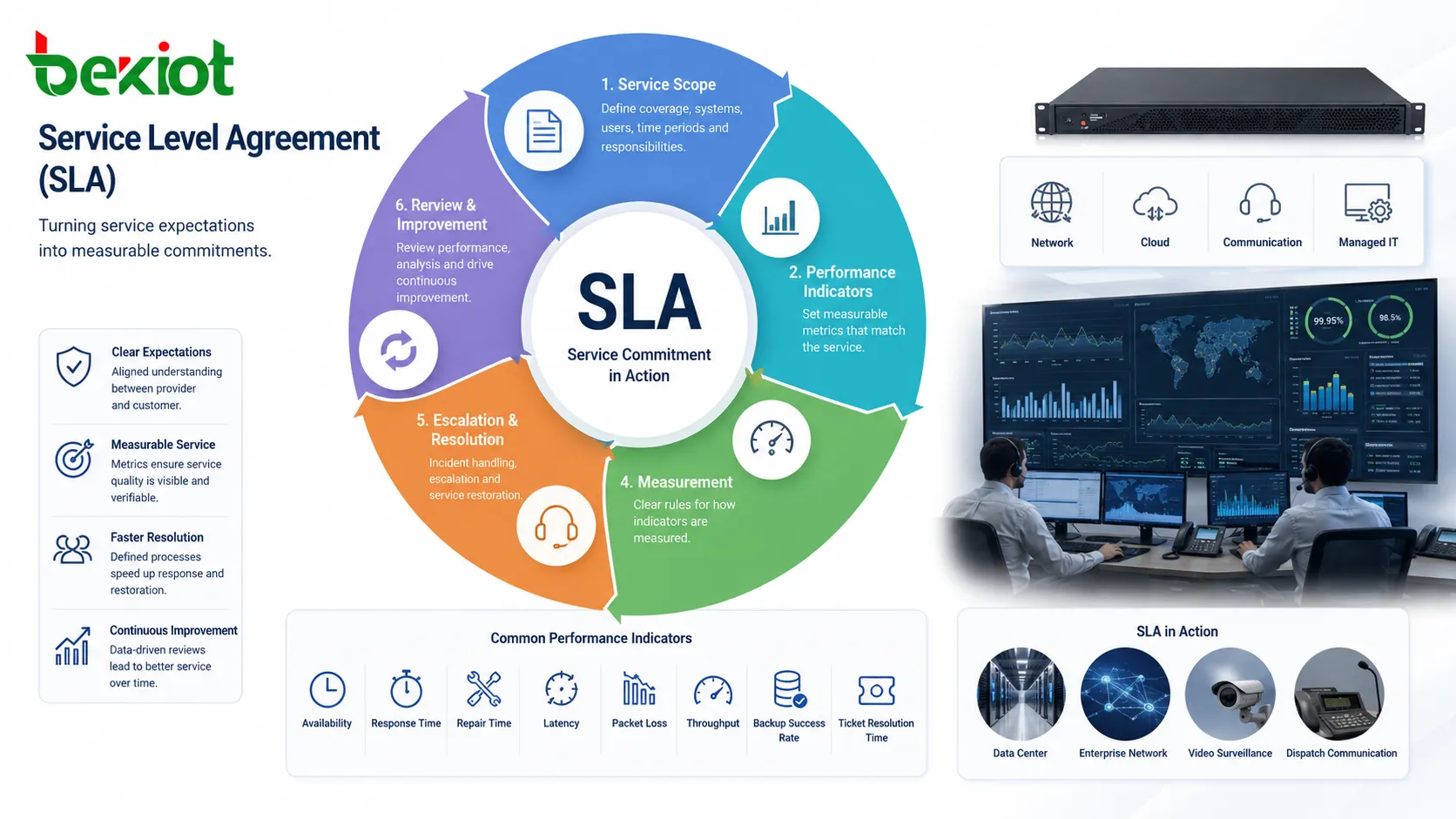
Un Acuerdo de Nivel de Servicio, o SLA, es un acuerdo formal que define el nivel esperado entre proveedor y cliente. Puede aplicarse a redes, nubes, centros de datos, comunicaciones, servicios gestionados, plataformas de software, mantenimiento y seguridad. Su propósito es convertir expectativas en compromisos medibles.
El funcionamiento empieza con el alcance del servicio: qué se cubre, qué sistemas o sedes entran, qué usuarios son atendidos, qué horarios aplican y qué responsabilidades corresponden a cada parte. Sin ese alcance, evaluar el desempeño se vuelve confuso.
Después se definen indicadores de desempeño. Pueden incluir disponibilidad, tiempo de respuesta, reparación, restauración, tratamiento de incidentes, éxito de copias de seguridad, resolución de tickets, latencia, pérdida de paquetes, rendimiento o cobertura de soporte. Los indicadores deben corresponder al tipo de servicio.
El SLA también define cómo se miden esos indicadores. La disponibilidad, por ejemplo, puede calcularse mensual o anualmente, desde el borde del proveedor o desde el extremo del cliente, y puede excluir o no mantenimientos programados. La operación correcta depende de reglas transparentes.
En la práctica, el SLA actúa como un marco continuo de gestión. Fija expectativas antes del inicio, guía el monitoreo, apoya la escalación durante fallas y ofrece evidencia para la revisión posterior. Es a la vez contrato y método operativo.
Del texto del acuerdo a la ejecución diaria
Un SLA suele escribirse como documento, pero su valor aparece cuando se convierte en trabajo diario. Debe influir en monitoreo, tickets, respuesta de equipos, actualizaciones al cliente y revisiones de desempeño. Si queda solo firmado, no mejora la calidad.
La ejecución diaria normalmente empieza con monitoreo. En redes se observan disponibilidad, latencia, jitter, pérdida de paquetes, interfaces y salud de dispositivos. En nube o software se revisan disponibilidad de aplicaciones, éxito de transacciones, respuesta API, uso de recursos y tasa de errores.
La gestión de incidentes es otro elemento central. El SLA debe indicar en cuánto tiempo se reconoce el problema, cómo se categoriza, cómo se escala y qué objetivo de restauración aplica. Un incidente crítico exige respuesta inmediata y actualizaciones frecuentes; una solicitud menor puede seguir otra ventana.
El SLA también condiciona personal y estructura de soporte. Si promete atención 24/7, el proveedor debe tener personas, herramientas y procedimientos para cumplirla. Si promete reparación rápida de equipos críticos, repuestos, acceso remoto y servicio de campo deben planificarse antes.
La comunicación con el cliente forma parte de la ejecución. Durante una incidencia, el cliente necesita saber si el caso fue recibido, qué impacto se espera, qué acciones están en curso y cuándo llegará la próxima actualización. Un buen SLA reduce incertidumbre.
Indicadores que dan significado real al acuerdo
La calidad del SLA depende mucho de sus indicadores. Frases como alta confiabilidad, soporte rápido o operación estable son positivas, pero no se evalúan de manera consistente. Los indicadores medibles permiten saber si el servicio cumple lo prometido.
La disponibilidad es uno de los indicadores más comunes. Expresa cuánto tiempo el servicio está utilizable en un período definido. El cálculo debe aclarar si se excluyen mantenimiento programado, fallas del cliente, fuerza mayor o problemas de terceros.
El tiempo de respuesta indica con qué rapidez el proveedor reconoce o inicia el tratamiento tras recibir un reporte. No es lo mismo que el tiempo de reparación. Se puede responder en quince minutos y tardar horas en restaurar; ambos valores miden fases distintas.
El tiempo de resolución o restauración mide cuánto tarda el servicio en volver a un estado normal o aceptable. Es clave para sistemas críticos. Muchos contratos asignan objetivos distintos según la severidad: una caída total requiere más rapidez que una solicitud menor.
Otros indicadores pueden ser latencia, jitter, pérdida de paquetes, throughput, éxito de transacciones, copias de seguridad, punto de recuperación, disponibilidad de mesa de ayuda, atención de incidentes de seguridad o mantenimiento preventivo. Deben reflejar lo que realmente importa al cliente.
Cómo los niveles de severidad orientan la respuesta
Muchos SLA usan niveles de severidad para clasificar incidentes. Así se evita tratar igual una caída total, degradación parcial, falla menor, consulta o cambio planificado. La clasificación ajusta los recursos de respuesta al impacto de negocio.
Un incidente de alta severidad puede implicar interrupción completa, impacto de seguridad, pérdida relevante o función crítica fuera de servicio. Normalmente requiere reconocimiento inmediato, escalación rápida, especialistas, actualizaciones frecuentes y meta estricta de restauración.
La severidad debe definirse por impacto, no por emoción. El cliente puede sentir que todo es urgente y el proveedor puede clasificar de forma conservadora. El SLA debe describir los niveles con claridad para reducir disputas durante situaciones tensas.
La severidad también guía la escalación. Si una falla no se resuelve en el tiempo definido, puede pasar a un nivel de soporte superior, involucrar gerencia o generar reportes adicionales. Esto evita que problemas graves queden atascados en primera línea.
En operaciones maduras, los datos de severidad se revisan periódicamente. Muchos incidentes críticos pueden revelar problemas de diseño o estabilidad. Re-clasificaciones frecuentes señalan definiciones poco claras. Por eso la revisión de severidad forma parte del ciclo SLA.
Monitoreo e informes como capa de evidencia
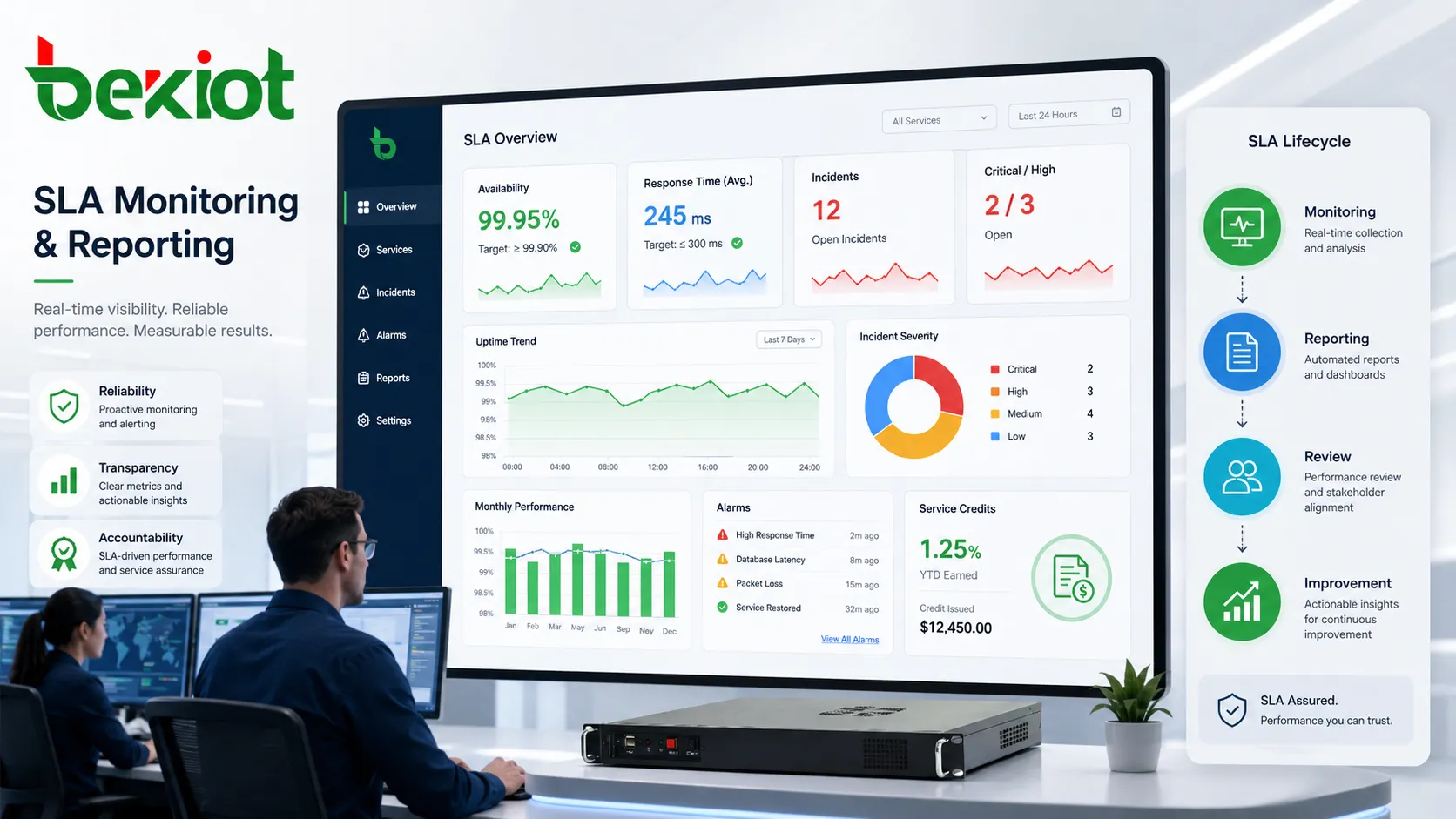
Sin evidencia, un SLA es difícil de aplicar o mejorar. El monitoreo y los informes muestran si las metas se cumplieron, dónde cambió la calidad, qué incidentes ocurrieron, qué tan rápido respondió el equipo y si aparecen problemas recurrentes.
El monitoreo puede ser automatizado o manual. Las herramientas registran disponibilidad, tráfico, estado de dispositivos, salud de servidores, transacciones, alarmas, tiempos de respuesta y errores. Los registros manuales incluyen visitas, comentarios, notas de soporte, inspecciones e informes post-incidente.
La frecuencia del informe debe ajustarse al servicio. Servicios críticos pueden requerir paneles en tiempo real, resúmenes diarios o avisos inmediatos. Servicios gestionados estándar pueden usar informes mensuales y contratos de mantenimiento pueden usar revisiones trimestrales.
La exactitud de los datos es esencial. Medir solo dentro del centro de datos del proveedor puede ocultar problemas de acceso del cliente. Medir disponibilidad sin verificar transacciones puede ocultar fallas funcionales. El SLA debe definir dónde y cómo se recopilan datos.
Un buen informe crea transparencia. Reduce disputas porque ambas partes discuten la misma evidencia. También ayuda a mejorar: interrupciones repetidas, respuestas lentas o módulos fallidos muestran dónde concentrar acciones correctivas.
Escalación, remedios y créditos de servicio
Un SLA debe definir qué ocurre cuando no se alcanzan los objetivos. La escalación, los remedios y los créditos de servicio crean responsabilidad y motivan a ambas partes a tratar los problemas con seriedad, aunque no evitan las fallas por sí solos.
La escalación describe cómo los casos no resueltos avanzan en la estructura de soporte. Un ingeniero de primera línea puede iniciar el diagnóstico; luego el caso puede pasar a especialistas, fabricante, centro de operaciones o gerencia. Deben existir umbrales, contactos, dueños y reglas de actualización.
Los remedios describen las consecuencias de incumplir niveles. Pueden ser créditos, planes de acción correctiva, extensiones de mantenimiento, revisión gerencial o derechos de terminación ante fallas repetidas. La medida correcta depende del servicio y de la relación comercial.
Los créditos de servicio deben diseñarse con cuidado. Compensan financieramente, pero rara vez cubren todo el impacto empresarial. En sistemas críticos, restaurar y prevenir suele importar más que un crédito pequeño; el crédito es una herramienta de responsabilidad, no sustituto de ingeniería confiable.
También deben definirse exclusiones. Los créditos pueden no aplicar si la causa está en configuración del cliente, cambios no autorizados, energía fuera del control del proveedor, mantenimiento programado, fuerza mayor o servicios de terceros. La claridad reduce disputas.
Ventajas para clientes y proveedores
Para el cliente, la ventaja principal es previsibilidad. Sabe qué nivel esperar, cuánto tardan las respuestas, qué servicios están cubiertos y qué evidencia se usará para evaluar. Esto ayuda a planificar negocio, gestionar riesgos y exigir responsabilidades.
El SLA también permite comparar proveedores. Dos servicios pueden parecer iguales en precio y funciones, pero diferir en disponibilidad, respuesta, escalación, informes o mantenimiento. El SLA muestra esas diferencias en términos operativos.
Para el proveedor, el SLA define límites. Aclara qué está incluido, qué se excluye, cómo se clasifican incidentes y qué debe aportar el cliente. Esto reduce expectativas irreales y permite planificar personal, monitoreo, repuestos y procesos.
También mejora la gestión interna. Soporte prioriza según severidad y contrato; operaciones detecta problemas repetidos; ventas explica mejor el valor; finanzas evalúa riesgos de créditos o penalizaciones. El SLA se vuelve una herramienta de gestión.
Para ambas partes, la mayor ventaja es la alineación. Las expectativas del cliente y el proceso de entrega del proveedor se conectan mediante métricas y procedimientos acordados, reduciendo ambigüedad y creando una referencia común.
Valor operativo más allá de la protección contractual
Algunas organizaciones ven el SLA principalmente como documento legal, pero su valor operativo suele ser mayor. Un buen SLA impulsa monitoreo, documentación, escalación, análisis de causa raíz, capacidad y mejora continua.
Si el SLA exige respuestas estrictas, el proveedor debe monitorear canales de soporte. Si define disponibilidad, debe mantener redundancia, respaldos y detección de incidentes. Si exige informes, debe reunir y organizar datos. Todo ello eleva la madurez del servicio.
Los clientes también se benefician. Sus equipos pueden usar informes para entender dependencias, justificar mejoras, planificar mantenimiento y evaluar riesgos. Si una unidad depende de un servicio débil, la dirección puede detectar la brecha antes de un incidente importante.
En entornos complejos, los SLA ayudan a coordinar varios proveedores: nube, red, seguridad y mantenimiento en sitio. Compromisos claros muestran dónde se unen responsabilidades y dónde pueden existir huecos.
Bien utilizado, el SLA forma parte del gobierno del servicio. Mueve la gestión desde quejas reactivas hacia control estructurado del desempeño y genera valor duradero más allá del texto contractual.
Errores comunes en el diseño de un SLA
Un error común es usar números impresionantes sin reglas de medición prácticas. Una alta disponibilidad parece fuerte, pero se debilita si excluye demasiadas condiciones o se mide en un punto que no refleja la experiencia del cliente.
Otro error es elegir demasiadas métricas. Una lista larga parece completa, pero complica y dispersa la gestión. Las mejores métricas son las relacionadas directamente con impacto de negocio, calidad de servicio o riesgo del cliente.
También son comunes las definiciones pobres de severidad. Si los niveles son vagos, habrá disputa en cada incidente. El acuerdo debe describir impactos e incluir ejemplos cuando sea posible para clasificar más rápido y con coherencia.
Algunos SLA fallan por responsabilidades unilaterales. La calidad depende de proveedor y cliente: acceso, reportes exactos, ventanas aprobadas, contactos, energía o apoyo de configuración pueden ser necesarios. Si no se definen, la restauración se retrasa.
El último error es no revisar el SLA cuando cambia el servicio. Necesidades, usuarios, arquitectura, seguridad y dependencias evolucionan. Un SLA adecuado al inicio puede quedar obsoleto; las revisiones regulares lo mantienen alineado.
Cómo evaluar si un SLA es efectivo
Un SLA efectivo debe ser claro, medible, relevante, realista y aplicable. La claridad significa que ambas partes entienden alcance, metas, medición, severidad, informes y remedios. Si necesita interpretación constante, no es fuerte operacionalmente.
La medición significa que el desempeño puede verificarse con datos confiables. El acuerdo debe indicar fuente de datos, cálculo y resolución de disputas. Una meta que no se mide de forma consistente no permite juicio justo.
La relevancia significa medir lo que realmente importa a la operación del cliente. Una métrica técnica puede ser útil si se conecta con experiencia o impacto empresarial. No conviene medir lo fácil e ignorar lo crítico.
El realismo significa que las metas coinciden con arquitectura, presupuesto, personal, riesgo y entorno. Objetivos demasiado agresivos pueden ser insostenibles; objetivos débiles protegen al proveedor pero no al cliente. Un buen SLA equilibra ambición y viabilidad.
La aplicabilidad significa que el incumplimiento produce acciones definidas. No siempre son penalizaciones: pueden ser escalación, acciones correctivas, créditos, revisión gerencial o planes de mejora. Lo importante es que el SLA provoque seguimiento.

Preguntas frecuentes
¿Un SLA solo se necesita para servicios subcontratados?
No. Los SLA sirven para servicios subcontratados y también para acuerdos internos entre TI, instalaciones, áreas de negocio o centros de servicios compartidos. Ayudan a definir expectativas y responsabilidad aunque no haya proveedor externo.
¿Cuál es la diferencia entre SLA y KPI?
Un SLA es un acuerdo de compromisos de servicio entre partes. Un KPI es un indicador para medir progreso o resultado. Los objetivos de SLA suelen usar KPI, pero no todo KPI forma parte de un compromiso contractual.
¿Un SLA puede garantizar que nunca habrá fallas?
No. Un SLA no elimina fallas; define desempeño esperado, respuesta, medición y remedios. El buen diseño reduce riesgos, mientras el SLA establece cómo se juzga y gestiona el servicio.
¿Quién debe revisar los informes de SLA?
Deben revisarlos equipos operativos y gerencia. Los técnicos necesitan detalle para solucionar y mejorar; los directivos necesitan tendencias, visibilidad de riesgo y evidencia de apoyo al negocio.
¿Con qué frecuencia debe actualizarse un SLA?
Debe revisarse cuando cambian alcance, arquitectura, escala de usuarios, dependencia del negocio, requisitos de cumplimiento o responsabilidades del proveedor. Incluso sin cambios mayores, una revisión periódica mantiene el acuerdo actualizado.