

El tiempo medio de reparación, conocido comúnmente como MTTR, es una métrica de mantenimiento y fiabilidad que mide el tiempo promedio necesario para devolver a operación normal un activo, dispositivo, máquina, servicio de software, componente de red o sistema de producción que ha fallado. Se centra en el proceso de reparación después de que ocurre una falla, por lo que es un indicador importante para controlar el tiempo de inactividad, mejorar la eficiencia del servicio, reforzar la resiliencia operativa y planificar el mantenimiento.
En fábricas, centros de datos, redes de telecomunicaciones, sistemas de transporte, instalaciones eléctricas, hospitales, edificios y entornos de TI, las fallas no siempre pueden evitarse. Lo importante es la rapidez con la que la organización puede detectar el problema, diagnosticar la causa, completar la reparación, probar el resultado y devolver el sistema al servicio. MTTR ayuda a los equipos a comprender el rendimiento de recuperación de una manera medible.
Significado básico en la gestión de fiabilidad
Mean Time to Repair representa la duración media de reparación en múltiples eventos de falla. No es el tiempo entre fallas ni el tiempo total de inactividad de todo un sistema durante un periodo largo. En cambio, responde a una pregunta práctica: cuando algo falla, ¿cuánto tarda normalmente en repararse?
Esta métrica es utilizada por ingenieros de mantenimiento, responsables de instalaciones, equipos de soporte de TI, ingenieros de fiabilidad, fabricantes de equipos y gerentes de operaciones. Un MTTR más bajo suele significar una restauración más rápida, mejor respuesta de mantenimiento, mayor preparación de repuestos, procedimientos más claros y una resolución de problemas más eficaz.
Qué mide realmente el MTTR
MTTR normalmente incluye el tiempo activo de reparación necesario para devolver un activo a su condición de funcionamiento. Según cómo la organización defina la métrica, puede incluir confirmación de falla, diagnóstico, sustitución de repuestos, recuperación de configuración, pruebas funcionales y restauración final del servicio.
Por ejemplo, si una máquina de producción se detiene por un sensor defectuoso, el tiempo de reparación puede incluir el envío del técnico, la inspección del sensor, el reemplazo, la calibración y la verificación del reinicio. Si falla un servidor, el tiempo de reparación puede incluir análisis del incidente, cambio de componentes, recuperación de datos, reinicio y validación del servicio.
Por qué la definición debe ser clara
Diferentes organizaciones pueden calcular MTTR de formas ligeramente distintas. Algunos equipos cuentan desde el momento en que se reporta la falla. Otros cuentan desde el momento en que comienza el trabajo de reparación. Algunos incluyen el tiempo de espera de repuestos, mientras que otros solo incluyen el tiempo técnico de reparación manual.
Por eso MTTR debe definirse claramente antes de usarlo para comparar desempeño. Sin una definición uniforme, la métrica puede resultar engañosa. Un equipo de mantenimiento puede parecer lento simplemente porque su cálculo incluye espera, aprobaciones o desplazamiento, mientras otro equipo solo mide la actividad de reparación real.
Cómo funciona el cálculo
La fórmula estándar de MTTR es sencilla. Se suma el tiempo de reparación de todos los eventos durante un periodo específico y se divide por el número total de eventos de reparación. El resultado muestra el tiempo promedio necesario para restaurar el activo o sistema fallido.
Por ejemplo, si cinco reparaciones tardan 2 horas, 3 horas, 1 hora, 4 horas y 5 horas, el tiempo total de reparación es de 15 horas. Al dividir 15 horas entre cinco eventos de reparación se obtiene un MTTR de 3 horas. Esto significa que cada reparación tarda, en promedio, 3 horas.
Recopilación del tiempo de reparación
Un MTTR preciso depende de registros de reparación precisos. Los equipos deben registrar cuándo se detecta una falla, cuándo empieza la reparación, qué acciones se realizan, cuándo se restaura el servicio y si la reparación fue verificada. Sistemas de gestión de mantenimiento, plataformas de tickets, registros SCADA, mesas de servicio y sistemas computarizados de mantenimiento pueden ayudar a recopilar esta información.
Los registros manuales también pueden funcionar, pero deben ser consistentes. Si los técnicos olvidan cerrar órdenes de trabajo, registran tiempos incompletos o clasifican incidentes de forma diferente, el valor final de MTTR puede no reflejar el desempeño operativo real.
Ejemplo sencillo de reparación de equipos
Imagine que una instalación tiene una unidad de ventilación que falla tres veces en un mes. La primera reparación tarda 90 minutos, la segunda 120 minutos y la tercera 60 minutos. El tiempo total de reparación es de 270 minutos.
Aplicando la fórmula de MTTR, 270 minutos divididos entre 3 eventos de reparación equivalen a 90 minutos. Por tanto, el MTTR de esa unidad de ventilación es de 90 minutos. Los responsables de instalaciones pueden usar este dato para evaluar la eficiencia de respuesta, la carga de trabajo de los técnicos, la disponibilidad de repuestos y la necesidad de mantenimiento preventivo.
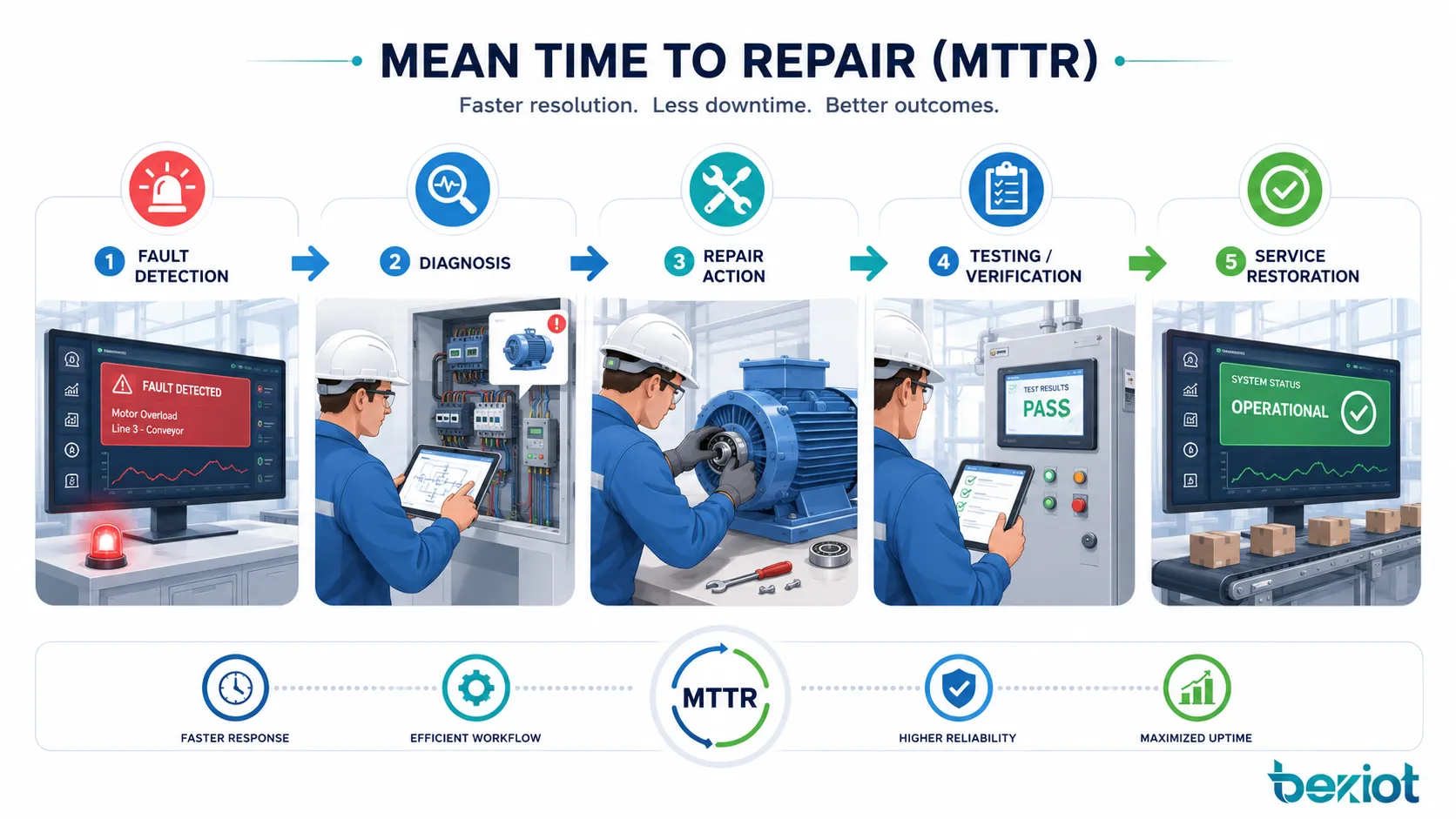
Qué ocurre durante un ciclo de reparación
MTTR no es solo un promedio matemático. Refleja el flujo completo de reparación detrás de cada falla. Un tiempo de reparación largo puede deberse a detección lenta, pasos de diagnóstico poco claros, falta de repuestos, documentación deficiente, acceso difícil al equipo o falta de personal capacitado.
Comprender el ciclo de reparación ayuda a los equipos a mejorar las causas reales del tiempo de inactividad, en lugar de mirar únicamente el número final.
Detección y reporte de fallas
El ciclo de reparación comienza cuando se detecta una falla. En algunos sistemas, la detección es automática mediante alarmas, sensores, paneles de monitoreo, autodiagnóstico o códigos de falla. En otros casos, un operador, usuario o técnico observa el problema y lo reporta manualmente.
Una detección rápida puede reducir el impacto total de una falla. Si una falla de máquina se descubre de inmediato, la reparación puede empezar antes de que el problema afecte la calidad de producción, la seguridad o los equipos posteriores. En operaciones de TI y redes, las alertas automáticas pueden acortar significativamente el tiempo de respuesta a incidentes.
Diagnóstico e identificación de causa raíz
Después de la detección, técnicos o ingenieros deben identificar la causa. El diagnóstico puede incluir inspección visual, análisis de registros, pruebas eléctricas, revisión mecánica, evaluación de software, trazado de red o comparación con historiales de fallas.
El diagnóstico suele ser uno de los factores más importantes que afectan al MTTR. Un equipo con buena documentación, códigos de falla claros, monitoreo remoto y técnicos experimentados puede identificar problemas más rápido que un equipo que depende solo de prueba y error.
Reparación, reemplazo y verificación
La reparación real puede implicar sustitución de componentes, reinicio de software, corrección de configuración, reparación de cables, ajuste mecánico, recuperación de firmware, limpieza, lubricación, recalibración o reemplazo completo del equipo.
Una vez terminada la reparación, el sistema debe probarse antes de volver al uso normal. La verificación puede incluir pruebas de arranque, controles de seguridad, pruebas de producción, pruebas de conectividad de red, confirmación de reinicio de alarmas o aceptación del usuario. Sin verificación, un sistema puede parecer reparado y fallar de nuevo poco después.
Por qué esta métrica importa
MTTR importa porque el tiempo de inactividad tiene consecuencias reales. Puede detener la producción, retrasar la entrega de servicios, reducir la satisfacción del cliente, aumentar los costos operativos, crear riesgos de seguridad y afectar la continuidad del negocio. Al seguir el tiempo de reparación, las organizaciones pueden identificar puntos débiles del mantenimiento y mejorar el rendimiento de recuperación.
MTTR es más útil cuando conduce a acciones. El objetivo no es solo calcular el tiempo promedio de reparación, sino entender por qué las reparaciones tardan tanto y cómo puede mejorarse el proceso.
Reducir el impacto del tiempo de inactividad
Un MTTR más bajo significa que los equipos o sistemas vuelven a operar más rápido después de una falla. En fabricación, esto puede reducir pérdidas de producción. En telecomunicaciones y TI, puede reducir interrupciones del servicio. En edificios e infraestructura, puede mejorar comodidad, seguridad y disponibilidad del servicio.
Reducir el tiempo de inactividad es especialmente importante para sistemas críticos. Plataformas de comunicación de emergencia, equipos de distribución eléctrica, sistemas médicos, infraestructura de control de tráfico, sistemas de seguridad y líneas de producción industrial suelen requerir restauración rápida porque la interrupción puede generar consecuencias operativas serias.
Mejorar la eficiencia del mantenimiento
MTTR ofrece a los equipos de mantenimiento una forma de evaluar cuán eficientemente responden a los problemas. Si el tiempo medio de reparación aumenta, los gerentes pueden investigar si la causa está en retrasos de repuestos, capacitación insuficiente, acceso difícil al equipo, escalamiento lento o instrucciones de reparación poco claras.
Al comparar MTTR por tipo de equipo, ubicación, turno o equipo de servicio, las organizaciones pueden identificar dónde se necesitan más mejoras. Esto apoya una mejor asignación de personal, capacitación más enfocada, documentación mejorada y planificación más inteligente de repuestos.
Apoyar metas de fiabilidad y disponibilidad
La disponibilidad del sistema depende tanto de la frecuencia de fallas como de la velocidad de recuperación. Aunque el equipo falle ocasionalmente, una reparación rápida puede mantener una disponibilidad aceptable del servicio. Por eso MTTR se usa a menudo junto con Mean Time Between Failures, porcentaje de uptime, objetivos de nivel de servicio y metas de fiabilidad.
Por ejemplo, un sistema con fallas frecuentes y reparaciones largas tendrá baja disponibilidad. Un sistema con fallas raras y reparaciones rápidas suele rendir mucho mejor desde la perspectiva de continuidad operativa.
Beneficios para equipos de operaciones y mantenimiento
MTTR aporta valor práctico porque conecta el desempeño técnico del mantenimiento con resultados empresariales. Ayuda a los equipos a pasar de la reparación reactiva a la mejora estructurada. En lugar de hablar del tiempo de inactividad en términos generales, los gerentes pueden usar datos de tiempo de reparación para tomar decisiones.
Mejor planificación de repuestos
Si las reparaciones tardan demasiado porque no hay repuestos disponibles, los datos de MTTR pueden revelar el problema. Los equipos de mantenimiento pueden identificar componentes críticos, fijar niveles mínimos de inventario, mejorar acuerdos con proveedores o usar módulos de reemplazo para recuperar más rápido.
Para activos de alto valor o relacionados con la seguridad, el costo de mantener repuestos en stock puede ser mucho menor que el costo de un tiempo de inactividad prolongado. El análisis de MTTR ayuda a justificar esa decisión con evidencia medible.
Gestión de niveles de servicio más clara
En mantenimiento subcontratado, soporte de TI, servicios de telecomunicaciones y operación de instalaciones, MTTR puede respaldar acuerdos de nivel de servicio. Proporciona tanto a proveedores como a clientes un indicador medible del desempeño de reparación.
Sin embargo, los objetivos de servicio deben ser realistas. Un objetivo de reparación para un lector de control de acceso simple no es igual al de una línea de producción compleja, un gran sistema HVAC o una falla de red multisede. Deben considerarse complejidad del equipo, ubicación, nivel de riesgo y condiciones de acceso.
Capacitación y documentación más efectivas
Un MTTR alto puede indicar que los técnicos necesitan mejor capacitación o instrucciones de reparación más claras. Si el mismo tipo de falla tarda repetidamente demasiado en resolverse, la organización puede crear guías estándar de diagnóstico, instrucciones visuales de trabajo, listas de verificación o procedimientos de soporte remoto.
Una buena documentación reduce la dependencia de la experiencia individual. También ayuda a los técnicos nuevos a reparar con más confianza y disminuye el riesgo de errores repetidos.
Aplicaciones comunes en distintas industrias
Mean Time to Repair se usa en muchas industrias porque casi toda organización depende de activos, sistemas, dispositivos o servicios que pueden fallar. El proceso de reparación específico puede variar, pero la necesidad de medir y mejorar el tiempo de restauración es universal.
Fabricación y equipos industriales
En plantas de fabricación, MTTR se usa para medir el desempeño de reparación en líneas de producción, motores, bombas, transportadores, robots, máquinas CNC, equipos de embalaje, sensores, gabinetes de control y sistemas auxiliares.
Reducir MTTR en entornos industriales puede mejorar la continuidad productiva, reducir horas extra, aumentar la utilización de activos y apoyar programas de mantenimiento lean. También ayuda a identificar qué máquinas generan mayor carga de reparación.
Sistemas de TI y centros de datos
En operaciones de TI, MTTR puede aplicarse a servidores, almacenamiento, aplicaciones, bases de datos, servicios en la nube, firewalls, switches, routers y plataformas orientadas al usuario. Es común en la gestión de incidentes y la ingeniería de fiabilidad del sitio.
Para servicios digitales, la reparación puede implicar restaurar funcionalidad de software en lugar de reemplazar componentes físicos. El proceso puede incluir revisión de logs, rollback, aplicación de parches, failover, corrección de configuración, reinicio o recuperación desde copia de seguridad.
Telecomunicaciones e infraestructura de red
Operadores de telecomunicaciones y equipos de red empresarial usan MTTR para evaluar la velocidad de recuperación de estaciones base, enlaces de fibra, equipos de transmisión, redes IP, gateways de comunicación, routers, switches y plataformas de servicio.
Las fallas de red pueden afectar a muchos usuarios al mismo tiempo. La reparación rápida y la localización precisa de fallas son esenciales para mantener la calidad del servicio. Monitoreo remoto, enlaces redundantes, rutas claras de escalamiento y coordinación de campo ayudan a reducir MTTR.
Instalaciones, edificios y servicios públicos
Los administradores de instalaciones usan MTTR para sistemas HVAC, ascensores, bombas, control de iluminación, control de acceso, interfaces de alarma contra incendios, equipos de seguridad, distribución eléctrica, sistemas de agua y automatización de edificios.
En edificios y servicios públicos, MTTR está estrechamente relacionado con la comodidad de los ocupantes, la seguridad, el cumplimiento normativo y la continuidad del servicio. Reparaciones largas pueden afectar a inquilinos, visitantes, áreas de producción o usuarios de infraestructura pública.
MTTR comparado con métricas relacionadas
MTTR suele analizarse junto con otras métricas de fiabilidad y mantenimiento. Comprender la diferencia ayuda a elegir el indicador adecuado para cada propósito. MTTR se centra en la velocidad de reparación, mientras otras métricas pueden enfocarse en frecuencia de fallas, disponibilidad del servicio o tiempo de respuesta a incidentes.
| Métrica | Significado | Propósito principal |
|---|---|---|
| MTTR | Tiempo medio de reparación | Mide el tiempo promedio necesario para restaurar un activo o sistema fallido |
| MTBF | Tiempo medio entre fallas | Mide el tiempo promedio de operación entre fallas |
| MTTF | Tiempo medio hasta la falla | Estima la vida esperada antes de la falla en elementos no reparables |
| MTTA | Tiempo medio de reconocimiento | Mide cuánto se tarda en advertir y reconocer un incidente |
| Availability | Relación de tiempo operativo | Muestra con qué frecuencia un sistema está disponible para su uso |
MTTR y MTBF
MTBF mide con qué frecuencia ocurren las fallas, mientras MTTR mide con qué rapidez se reparan. Ambos son importantes. Un sistema puede tener un MTBF alto y aun así causar una interrupción grave si cada reparación tarda mucho tiempo.
Por ejemplo, una máquina que falla solo dos veces al año puede seguir siendo problemática si cada falla requiere tres días de reparación. En cambio, un dispositivo menos crítico puede fallar más seguido y repararse en minutos. MTBF y MTTR deben revisarse juntos para obtener una visión completa de fiabilidad.
MTTR y disponibilidad
La disponibilidad está fuertemente influida por MTTR. Si el tiempo de reparación disminuye, la disponibilidad puede mejorar, suponiendo que la tasa de fallas permanezca igual. Por eso reducir MTTR es una estrategia común para sistemas que no pueden rediseñarse de inmediato para fallar con menor frecuencia.
En términos prácticos, los equipos pueden mejorar disponibilidad evitando fallas, reparando más rápido, agregando redundancia, mejorando el monitoreo o diseñando sistemas que continúen operando en modo degradado mientras se realiza la reparación.
Cómo reducir el tiempo de reparación
Reducir MTTR requiere más que pedir a los técnicos que trabajen más rápido. La mejora sostenible suele venir de mejor diseño del sistema, mejor información, mejor preparación y mejor coordinación. El objetivo es eliminar demoras del proceso de reparación.
Usar monitoreo y detección temprana de fallas
El monitoreo automático puede detectar condiciones anormales antes de que se conviertan en fallas mayores. Sensores, logs, alarmas, paneles, sistemas de monitoreo de condición y herramientas de mantenimiento predictivo ayudan a responder antes y diagnosticar más rápido.
La detección temprana es especialmente útil cuando el equipo muestra señales como vibración, aumento de temperatura, cambio de presión, fluctuación de voltaje, códigos de error o inestabilidad de comunicación. Actuar sobre estas señales puede reducir tanto el tiempo de reparación como el impacto de la falla.
Estandarizar procedimientos de diagnóstico
La velocidad de reparación mejora cuando los técnicos siguen procedimientos claros. Listas de verificación, árboles de fallas, manuales de mantenimiento, diagramas de cableado, listas de repuestos, pasos de recuperación de software y reglas de escalamiento reducen la incertidumbre.
Los procedimientos estándar también hacen que el desempeño sea más consistente entre técnicos y turnos. Ayudan a garantizar que el mismo problema se maneje de la misma forma confiable cada vez.
Mejorar el acceso a repuestos y herramientas
Muchas reparaciones se retrasan no porque la falla sea difícil, sino porque no está disponible la pieza, herramienta, contraseña, imagen de software, cable o instrumento de prueba requerido. Preparar kits de reparación y almacenar repuestos críticos puede reducir mucho el tiempo de restauración.
En sitios distribuidos, repuestos locales, centros regionales de servicio o estrategias de reemplazo modular evitan largos desplazamientos y demoras de envío. En sistemas digitales, copias de seguridad listas para usar y plantillas de configuración cumplen una función similar.
Límites y mal uso de MTTR
Aunque MTTR es útil, no debe tratarse como el único indicador de desempeño del mantenimiento. Un MTTR bajo no siempre significa que el sistema sea fiable. Puede indicar simplemente que el equipo repara bien fallas repetidas. Si el mismo activo sigue fallando, la causa raíz aún requiere atención.
MTTR también puede ocultar variaciones. Un promedio puede parecer aceptable aunque algunos incidentes críticos tarden mucho más de lo esperado. Para sistemas importantes, los equipos deben revisar distribución de tiempos de reparación, peores incidentes, fallas repetidas y equipos de alto riesgo por separado.
No ignorar la prevención de fallas
La velocidad de reparación es importante, pero prevenir fallas evitables suele ser mejor. Mantenimiento preventivo, monitoreo de condición, mejora de diseño, instalación correcta, capacitación de operadores y protección ambiental pueden reducir la frecuencia de fallas.
Una estrategia de mantenimiento sólida debe equilibrar reparación rápida y mejora de fiabilidad a largo plazo. MTTR indica cuán rápido se recupera el equipo, pero no explica por qué las fallas ocurren si no se combina con análisis de causa raíz.
No comparar sin contexto
Comparar MTTR entre sistemas diferentes puede ser engañoso. Reemplazar un sensor simple no es comparable con reparar una turbina, una caída de red, una falla de ascensor o una recuperación de base de datos. Cada tipo de activo tiene complejidad, nivel de riesgo, condición de acceso y requisito de reparación propios.
Las comparaciones significativas deben realizarse dentro de grupos de equipos similares, condiciones de servicio similares o el mismo activo a lo largo del tiempo. Así los equipos identifican mejoras reales sin crear juicios de desempeño injustos.
Buenas prácticas para uso práctico
Para usar MTTR eficazmente, las organizaciones deben definir claramente la métrica, recopilar datos confiables, analizar las causas de reparaciones largas y conectar los hallazgos con acciones de mejora. La métrica debe apoyar mejores decisiones, no convertirse solo en un número de informe.
Definir puntos de inicio y fin
Cada organización debe decidir cuándo comienza y termina el tiempo de reparación. Puede empezar cuando se informa la falla, se abre el ticket, llega el técnico o comienza la reparación activa. Puede terminar cuando el activo reinicia, se completan las pruebas o el usuario confirma la restauración del servicio.
La definición elegida debe coincidir con el propósito de medición. Si el objetivo es mejorar el servicio al cliente, el tiempo total de inactividad puede ser más relevante. Si el objetivo es medir eficiencia técnica, el tiempo activo de reparación puede ser más apropiado.
Segmentar los datos
En lugar de calcular un MTTR amplio para todos los activos, los equipos deben segmentar datos por tipo de equipo, ubicación, categoría de falla, nivel de severidad, equipo, turno, proveedor o función del sistema. Esto hace que la métrica sea más útil y accionable.
Por ejemplo, una instalación puede descubrir que las bombas se reparan rápido, pero los ascensores tardan porque los repuestos se subcontratan. Un equipo de TI puede encontrar que los incidentes de aplicación se resuelven rápido, mientras los de red requieren más diagnóstico. La segmentación muestra dónde debe empezar la mejora.
Conectar MTTR con análisis de causa raíz
Cuando los tiempos de reparación son altos, los equipos deben investigar la razón. ¿La falla fue difícil de diagnosticar? ¿Faltaba documentación? ¿No estaba disponible el repuesto? ¿Se demoró la aprobación? ¿No había acceso remoto? ¿El equipo era difícil de alcanzar?
El análisis de causa raíz convierte MTTR de una medición pasiva en una herramienta activa de mejora. Con el tiempo, esto puede reducir el tiempo de inactividad, mejorar la fiabilidad y hacer más predecible la planificación de mantenimiento.
FAQ
¿Qué significa Mean Time to Repair?
Mean Time to Repair es el tiempo promedio necesario para restaurar un activo, sistema, dispositivo o servicio fallido a operación normal. Se calcula dividiendo el tiempo total de reparación entre el número de eventos de reparación durante un periodo definido.
¿MTTR es lo mismo que tiempo de inactividad?
No siempre. MTTR normalmente se centra en la duración de reparación, mientras que el tiempo de inactividad puede incluir detección, demora de reporte, espera, retraso de repuestos, aprobación y reinicio. La organización debe definir exactamente qué incluye antes de usar la métrica.
¿Cuál es un buen valor de MTTR?
Un buen MTTR depende del equipo, la industria, el requisito de servicio y la gravedad de la falla. Para reiniciar un servicio digital pueden esperarse pocos minutos, mientras varias horas pueden ser razonables en equipos industriales complejos. La mejor referencia suele ser comparar activos similares o el desempeño anterior.
¿Cómo puede una empresa reducir MTTR?
Una empresa puede reducir MTTR mejorando el monitoreo, acelerando la detección de fallas, estandarizando diagnóstico, capacitando técnicos, manteniendo repuestos críticos disponibles, usando diagnóstico remoto, mejorando documentación y simplificando el acceso a equipos.
¿Por qué MTTR es importante para la fiabilidad?
MTTR es importante porque la velocidad de reparación afecta directamente el tiempo de inactividad y la disponibilidad del sistema. Incluso los sistemas fiables pueden fallar, por lo que una recuperación rápida reduce impacto operativo, interrupción del servicio, pérdidas de producción e insatisfacción del cliente.
¿Cuál es la diferencia entre MTTR y MTBF?
MTTR mide cuánto tardan las reparaciones después de una falla. MTBF mide el tiempo promedio entre fallas. MTTR se centra en velocidad de recuperación, mientras MTBF se centra en frecuencia de fallas. Ambas métricas son útiles para entender la fiabilidad y disponibilidad generales.







