Una empresa con una sola oficina suele resolver sus problemas de red añadiendo un switch, actualizando un router o ajustando una regla del firewall. Una organización con muchas ubicaciones afronta un reto distinto: cada sucursal, planta, almacén, campus, centro de datos, región de nube y punto de acceso remoto forma parte de un mismo sistema operativo. Si estos sitios se conectan sin planificación, pueden aparecer accesos fragmentados, recursos duplicados, seguridad inconsistente, diagnóstico lento y colaboración inestable.
Perspectiva del sector:el valor de una red distribuida ya no se limita a la conectividad básica. Las organizaciones modernas la utilizan para acceso a la nube, comunicaciones unificadas, supervisión remota, videovigilancia, plataformas IoT, gestión centralizada, recuperación ante desastres, acceso de confianza cero y aplicaciones de negocio en tiempo real. La cuestión no es solo conectar lugares diferentes, sino convertir esas conexiones en una base de servicios controlable e inteligente.
Aprovechar plenamente esta arquitectura significa tratarla como una plataforma digital estratégica. Cada sede no debe funcionar como una isla separada. Debe compartir los recursos adecuados, seguir las reglas de seguridad correctas, intercambiar los datos necesarios y mantenerse resiliente cuando fallen enlaces, equipos o servicios.
De la conectividad de sucursales a la integración operativa
El objetivo inicial de conectar varias ubicaciones solía ser sencillo: permitir que los usuarios de las sucursales accedieran a los sistemas de la sede central. Este modelo empleaba líneas arrendadas, túneles VPN, enlaces WAN privados o conexiones punto a punto. Resolvía el acceso, pero no siempre creaba operaciones digitales flexibles.
Hoy el entorno operativo es más complejo. Las aplicaciones pueden ejecutarse en nube pública, nube privada, servidores de borde, centros de datos locales o plataformas SaaS. Los usuarios pueden trabajar desde oficinas, vehículos, hogares remotos, sitios de campo y dispositivos móviles. Las amenazas pueden venir de Internet, terminales comprometidos, servicios de nube mal configurados o movimiento lateral interno.
Por este cambio, una arquitectura distribuida debe soportar más que el transporte de tráfico. Debe respaldar rendimiento de aplicaciones, acceso basado en identidad, políticas centralizadas, segmentación, supervisión, automatización y resiliencia en todas las sedes conectadas.

Definir el papel de cada ubicación
No todas las ubicaciones tienen la misma función. La sede central puede alojar sistemas críticos, equipos directivos, salas de datos y seguridad central. Una fábrica puede priorizar tecnología operativa, supervisión de producción, terminales industriales y control local. Un almacén puede centrarse en códigos de barras, logística, cámaras, cobertura inalámbrica y dispositivos de mano. Una oficina pequeña quizá solo necesite acceso seguro a aplicaciones en la nube y servicios de voz compartidos.
Antes de optimizar, cada sede debe clasificarse por rol de negocio, dependencia de aplicaciones, número de usuarios, tipo de tráfico, requisito de disponibilidad y sensibilidad de seguridad. Esta clasificación ayuda a decidir ancho de banda, enrutamiento, redundancia, segmentación, selección de equipos, profundidad de monitoreo y modelo de soporte.
Sin este paso, las organizaciones pueden sobredimensionar sedes pequeñas y proteger insuficientemente sedes críticas. Un diseño sólido ajusta el nivel de red a la importancia empresarial de cada ubicación.
Construir un modelo de conectividad claro
Un entorno distribuido puede usar MPLS, Internet de banda ancha, 4G/5G, fibra privada, microondas, satélite, VPN, SD-WAN o conectividad híbrida. Cada opción tiene características diferentes de rendimiento, coste, fiabilidad y gestión.
Los enlaces WAN privados tradicionales ofrecen rendimiento controlado, pero pueden ser costosos y lentos de desplegar. La VPN por Internet es flexible y económica, aunque su rendimiento puede variar. SD-WAN puede combinar varios enlaces, dirigir tráfico según políticas de aplicación y ofrecer orquestación centralizada. Los enlaces celulares sirven para despliegue rápido o respaldo. El satélite cubre sitios remotos sin enlaces terrestres.
El mejor modelo suele ser híbrido. Las sedes críticas pueden usar enlaces duales. Las sucursales pequeñas pueden usar banda ancha con respaldo celular. Los sitios industriales remotos pueden usar fibra privada o retorno inalámbrico. El tráfico de nube puede ir directamente a plataformas cloud en lugar de pasar por la sede central.
Usar gestión centralizada sin perder resiliencia local
La gestión centralizada permite configurar, supervisar, actualizar y proteger muchas sedes desde una sola plataforma. Reduce errores manuales, mejora la estandarización y hace más eficiente la operación a gran escala.
Sin embargo, la centralización no debe crear un punto único de fallo. Una sucursal no debería dejar de funcionar por completo si pierde temporalmente contacto con el controlador central. Según la importancia del sitio, pueden ser necesarios salida local, políticas en caché, rutas de respaldo, DHCP local, reenvío DNS local y rutas de comunicación de emergencia.
El objetivo es equilibrar el control. La organización debe administrar de forma coherente desde el centro y permitir que las sedes mantengan funciones esenciales durante fallos de enlace o del controlador.
Segmentar el tráfico por función y riesgo
La segmentación es esencial en una arquitectura distribuida. Tráfico de usuarios, voz, videovigilancia, Wi-Fi de invitados, control industrial, pagos, servidores, interfaces de gestión y dispositivos IoT no deben compartir el mismo espacio de seguridad.
VLAN, VRF, zonas de firewall, listas de control de acceso, microsegmentación, políticas de confianza cero y grupos de seguridad definidos por software ayudan a separar el tráfico. El objetivo es reducir riesgos, controlar accesos y evitar que un área comprometida afecte a toda la organización.
La segmentación debe seguir la lógica del negocio. Por ejemplo, un usuario de Wi-Fi invitado no debe llegar a servidores internos. Una red de cámaras puede enviar vídeo a almacenamiento, pero no acceder a equipos de oficina. Los terminales industriales pueden necesitar rutas estrictas hacia sistemas de control y servidores de monitoreo.
Optimizar las rutas de las aplicaciones
El rendimiento de las aplicaciones es una de las principales razones para modernizar la conectividad entre ubicaciones. Los usuarios no juzgan la red por diagramas de enlaces, sino por llamadas claras, paneles que cargan rápido, archivos que se sincronizan, vídeo estable y sistemas que responden sin demora.
El enrutamiento consciente de aplicaciones puede seleccionar rutas según latencia, pérdida de paquetes, jitter, ancho de banda y prioridad del servicio. Voz y vídeo necesitan baja latencia y bajo jitter. Las transferencias grandes toleran demora, pero requieren ancho de banda. Las aplicaciones cloud pueden beneficiarse de salida directa a Internet. Los datos sensibles pueden necesitar inspección mediante gateways de seguridad.
La ingeniería de tráfico debe basarse en el comportamiento real de las aplicaciones. Un modelo genérico de enviar todo el tráfico a la sede central puede ser ineficiente cuando la mayoría de aplicaciones están alojadas en la nube.
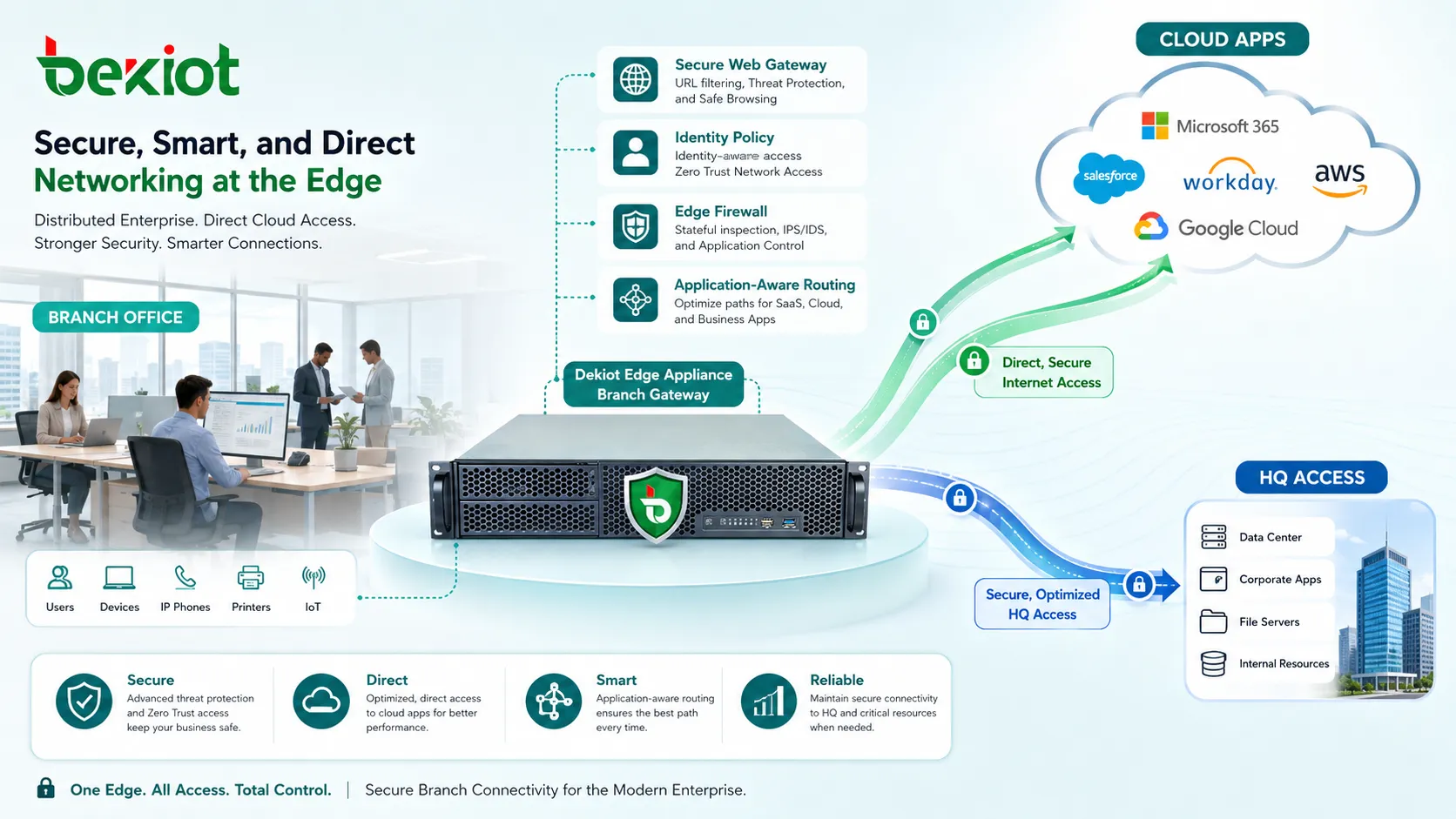
Reforzar el acceso a la nube y SaaS
El acceso a la nube ha cambiado el diseño de red. Muchas organizaciones usan SaaS, cargas en nube pública, servicios de identidad, almacenamiento cloud, escritorios remotos y sistemas de negocio basados en API. Si todo el tráfico cloud se fuerza por un centro de datos central, los usuarios pueden sufrir retrasos innecesarios.
El acceso directo a la nube mejora el rendimiento, pero debe protegerse. Puede implicar gateways web seguros, funciones CASB, políticas basadas en identidad, seguridad DNS, comprobaciones de postura del endpoint e inspección de tráfico cifrado cuando sea apropiado.
La conectividad cloud también debe planificarse para la fiabilidad. Las cargas críticas pueden requerir regiones cloud redundantes, interconexiones dedicadas, enlaces de Internet de respaldo o políticas de failover.
Soportar comunicaciones unificadas entre sedes
Voz, vídeo, mensajería, conferencias, intercomunicación, megafonía y despacho suelen depender de la misma base de red. Mal enrutamiento, jitter, pérdida de paquetes o errores de firewall afectan rápidamente la calidad de comunicación.
Una red distribuida bien diseñada debe clasificar el tráfico multimedia en tiempo real, priorizar flujos sensibles al retardo, garantizar NAT traversal cuando sea necesario y supervisar indicadores de calidad de voz. También debe soportar supervivencia local de comunicación crítica si los servicios centrales no están disponibles.
En organizaciones con muchas sedes, la comunicación unificada debe integrarse con directorios, planes de numeración, rutas de emergencia, políticas de grabación y reglas de seguridad. Esto evita islas de comunicación y mejora la coordinación diaria y ante incidentes.
Habilitar vídeo e IoT a escala
La videovigilancia, sensores, control de acceso, monitoreo ambiental, medidores inteligentes, terminales industriales e IoT pueden generar mucho tráfico. Además, sus características de seguridad son diferentes de las de dispositivos de usuario comunes.
Para utilizar estos sistemas eficazmente, la red debe definir dónde se procesan los datos. Algunos análisis de vídeo pueden hacerse en el borde. Algunas grabaciones pueden guardarse localmente y sincronizarse al centro. Algunos datos de sensores pueden enviarse a plataformas cloud. No todos los flujos deben cruzar la WAN continuamente.
El procesamiento en el borde reduce presión de ancho de banda y mejora el tiempo de respuesta. Las plataformas centrales aportan visibilidad y gestión. El enfoque adecuado depende del sitio, la aplicación, el valor de los datos y los requisitos de retención.
Usar seguridad basada en políticas
La seguridad tradicional se centraba en perímetros de sitio. Los entornos distribuidos modernos requieren control más granular. Un usuario puede acceder desde una sucursal, casa, móvil o espacio cloud. Un dispositivo puede moverse entre redes. Un servicio puede ejecutarse en varias regiones.
Las políticas deben basarse en identidad, salud del dispositivo, ubicación, aplicación, sensibilidad de datos y nivel de riesgo. Aquí son útiles los principios de confianza cero. El acceso debe concederse por contexto verificado, no por confiar en un sitio solo porque está dentro de la WAN.
La seguridad basada en políticas también mejora la consistencia. En lugar de configurar cada firewall y router de forma distinta, las organizaciones pueden definir modelos estándar de acceso y desplegarlos en todas las sedes.
Diseñar para fallos, no solo para operación normal
Un sistema distribuido sufrirá fallos. Los enlaces de Internet caen, falla la energía, los equipos se bloquean, los servicios cloud pueden quedar inaccesibles, la fibra puede cortarse y los cambios de configuración pueden causar rutas inesperadas. La prueba real es si las funciones críticas continúan o se recuperan rápido.
La planificación de resiliencia debe incluir enlaces redundantes, energía de respaldo, equipos dobles, failover automático, supervivencia local, gestión fuera de banda, copias de configuración y procedimientos de recuperación ante desastres. Las sedes críticas deben tener más protección que las de bajo riesgo.
El failover debe probarse. Un enlace de respaldo nunca ensayado puede fallar en el momento más importante. Las pruebas deben incluir enrutamiento, políticas de seguridad, servicio de voz, acceso a aplicaciones y alertas de monitoreo.
Mejorar la visibilidad con monitoreo y telemetría
Los grandes entornos distribuidos no pueden gestionarse por observación manual. Los administradores necesitan datos en tiempo real e históricos sobre estado de enlaces, uso de ancho de banda, latencia, pérdida de paquetes, salud de equipos, rendimiento de aplicaciones, eventos de seguridad, experiencia de usuario y cambios de configuración.
El monitoreo debe ser por capas. El monitoreo de dispositivos indica si el equipo está en línea. El de enlaces muestra la calidad de transporte. El de aplicaciones muestra si los usuarios completan tareas. El de seguridad muestra comportamientos sospechosos. El análisis de registros muestra qué cambió antes de un incidente.
Una buena visibilidad reduce el tiempo de diagnóstico. En vez de preguntar si el problema es “la red”, los ingenieros pueden ver si se trata de DNS, congestión WAN, bloqueo de firewall, caída de un servicio cloud, problema inalámbrico o fallo de endpoint.

Automatizar operaciones repetitivas
La automatización reduce el trabajo manual repetido. Entre las tareas habituales están incorporación de dispositivos, plantillas de configuración, despliegue de políticas, actualizaciones de firmware, renovación de certificados, respaldo de configuración, respuesta a alertas y comprobaciones de cumplimiento.
La configuración basada en plantillas es especialmente valiosa para nuevas sucursales. En lugar de reconstruir rutas, VLAN, VPN, reglas de firewall y monitoreo manualmente, los administradores aplican un perfil estándar y ajustan solo parámetros del sitio.
La automatización debe controlarse con aprobación, seguimiento de versiones, pruebas y rollback. El despliegue rápido solo es útil cuando los cambios son fiables.
Estandarizar direccionamiento y nombres
La planificación de direcciones se complica cuando muchas sedes crecen de forma independiente. Rangos IP solapados, nombres VLAN poco claros, registros DNS inconsistentes y subredes sin documentar provocan conflictos de enrutamiento y retrasos de diagnóstico.
Un plan central debe definir códigos de sitio, bloques IP, rangos VLAN, direcciones loopback, redes de gestión, ámbitos DHCP y rangos reservados. Las reglas de nombre deben identificar claramente sede, tipo de dispositivo, función y rol.
Buenos nombres y direcciones reducen confusión. También facilitan automatización, monitoreo, políticas de firewall y mantenimiento de documentación.
Planificar Wi-Fi y acceso de borde de forma coherente
Muchas sedes dependen de Wi-Fi, terminales de mano, móviles, escáneres de códigos, tabletas, cámaras, sensores y acceso de invitados. El diseño inalámbrico debe ser coherente para roaming, seguridad y gestión, pero flexible para el diseño local del edificio.
Los controladores inalámbricos centralizados o puntos de acceso gestionados en la nube simplifican políticas. Sin embargo, la planificación RF sigue requiriendo estudios de sitio, diseño de canales, análisis de interferencias y planificación de capacidad.
El acceso de borde también debe considerar seguridad física. Los puertos de red en áreas públicas, almacenes e instalaciones industriales no deben dar acceso interno sin restricciones.
Conectar la tecnología operativa con cuidado
Los sistemas industriales y de edificios suelen incluir tecnología operativa como PLC, terminales SCADA, sensores, control de acceso, energía y equipos de producción. Estos sistemas pueden requerir baja latencia, operación estable, segmentación estricta y ventanas de mantenimiento controladas.
Conectar redes operativas con sistemas empresariales mejora monitoreo y análisis de datos, pero también introduce riesgo cibernético. El acceso debe controlarse mediante firewalls, gateways, jump hosts, comprobaciones de identidad y registros.
Los equipos IT y OT deben acordar propiedad, procedimientos de mantenimiento, acceso de emergencia y control de cambios. Un cambio inocuo en la red de oficina puede afectar producción si se aplica sin cuidado.
Usar salida local de forma estratégica
La salida local a Internet permite que una sucursal acceda directamente a servicios cloud e Internet en vez de enviar todo el tráfico a la sede central. Esto reduce latencia y mejora la experiencia de aplicaciones.
El riesgo es que el tráfico de sucursal evite controles centrales de seguridad. Para evitarlo, la salida local debe combinarse con gateways web seguros, filtrado DNS, protección de endpoint, servicios de seguridad cloud e inspección basada en políticas.
No todo el tráfico debe salir localmente. Las aplicaciones internas sensibles pueden seguir usando rutas privadas, mientras SaaS y tráfico web de bajo riesgo usan una salida local controlada.
Alinear el diseño de red con la continuidad del negocio
La planificación de continuidad debe definir qué servicios deben sobrevivir ante fallos. Una tienda puede necesitar pagos, un hospital acceso clínico y comunicación de emergencia, una fábrica supervisión de producción y un almacén escaneo y logística.
Una vez identificadas las funciones críticas, la red puede aportar el nivel correcto de redundancia y supervivencia local. Puede incluir servidores locales, autenticación en caché, WAN de respaldo, failover celular, enrutamiento local de voz o procedimientos de emergencia.
La continuidad debe probarse con escenarios reales. Un plan escrito no basta si los usuarios no saben operar durante una caída de red.
Gobernanza y control de cambios
Los entornos multisede necesitan gobernanza disciplinada. Un cambio rápido de firewall en una sede puede afectar el acceso desde otra. Una nueva conexión cloud puede alterar rutas. Una VPN temporal puede quedarse permanente sin revisión.
El control de cambios debe incluir motivo, sedes afectadas, nivel de riesgo, plan de rollback, método de prueba, ventana de mantenimiento, aprobación y actualización documental. Los cambios de emergencia deben revisarse después del incidente.
Gobernanza no significa ralentizar todo. Significa hacer los cambios seguros, trazables y repetibles.
Optimización de costes
Aprovechar una arquitectura distribuida también implica controlar costes. Algunas organizaciones pagan demasiado ancho de banda donde hay poco tráfico y subinvierten en enlaces críticos. Otras mantienen circuitos privados antiguos aunque los patrones cloud hayan cambiado.
El análisis de costes debe comparar valor de negocio, necesidad de rendimiento, nivel de riesgo y requisito de redundancia. Un enlace caro puede justificarse para una sede crítica, pero no para una oficina pequeña con aplicaciones solo en la nube.
Los datos de monitoreo guían decisiones. Uso real de ancho de banda, pérdida de paquetes, tiempo de respuesta de aplicaciones y eventos de failover son mejor evidencia que suposiciones.
Hoja de ruta de implementación
Empiece por el descubrimiento. Mapee sedes, enlaces, equipos, aplicaciones, usuarios, zonas de seguridad, servicios cloud y dependencias operativas. Identifique sistemas duplicados, enlaces débiles, equipos no gestionados y flujos no documentados.
Después defina la arquitectura objetivo. Decida qué sedes necesitan redundancia, qué tráfico debe usar rutas privadas, qué servicios pueden usar salida local, cómo funcionará la segmentación y cómo se administrarán las políticas.
Luego implemente por etapas. Estandarice nombres y direcciones, mejore monitoreo, despliegue segmentación, optimice acceso cloud, introduzca automatización y pruebe resiliencia. Evite cambiar todas las sedes a la vez salvo que exista una fuerte capacidad de rollback.
Errores comunes
Un error es tratar todas las sedes igual. Tienen riesgos, perfiles de tráfico e importancia distintos; la arquitectura debe reflejarlo.
Otro error es centrarse solo en ancho de banda. Más ancho de banda no resuelve errores de ruta, brechas de seguridad, mal Wi-Fi, DNS defectuoso, latencia de aplicación ni falta de visibilidad.
Un tercer error es permitir excepciones locales sin control. Rutas temporales, switches no gestionados, líneas de Internet ocultas y VPN no registradas crean riesgo a largo plazo.
Un cuarto error es ignorar la experiencia del usuario. La red puede parecer sana por estado de dispositivos, mientras los usuarios sufren aplicaciones lentas o mala calidad de voz.
Un quinto error es retrasar la documentación. En un entorno distribuido, un diseño sin documentar se convierte en riesgo de futuras caídas.
Tendencias del sector
Las redes distribuidas avanzan hacia control gestionado en la nube, SD-WAN, SASE, acceso de confianza cero, edge computing, monitoreo asistido por IA y mayor integración entre red y seguridad. La frontera entre WAN, acceso cloud, identidad y protección contra amenazas es cada vez menos separada.
Al mismo tiempo, las organizaciones añaden más dispositivos conectados y servicios en tiempo real. Vídeo, voz, sensores, telemetría industrial y operaciones remotas aumentan la presión sobre el diseño de red.
La dirección más exitosa no es añadir más herramientas, sino construir un modelo operativo coherente donde conectividad, seguridad, monitoreo, automatización y flujo de negocio se apoyen entre sí.
Una red multisede se aprovecha plenamente cuando se convierte en una base digital gestionada que conecta ubicaciones, protege el acceso, optimiza aplicaciones, soporta resiliencia y da a los administradores visibilidad clara de toda la organización.
Preguntas frecuentes
¿Por qué diferentes sucursales tienen distinta calidad de red?
Cada sucursal puede usar enlaces, entornos Wi-Fi, rutas, modelos de equipo, distancias a la nube y cargas locales diferentes. El monitoreo debe comparar condiciones por sitio en lugar de asumir una causa común.
¿Debe todo el tráfico volver a la sede central?
No siempre. El tráfico cloud y SaaS puede rendir mejor con salida local controlada, mientras el tráfico interno sensible puede requerir rutas privadas o inspección central.
¿Cómo proteger sedes pequeñas sin equipos complejos?
Use plantillas estandarizadas, firewalls gestionados, gateways cloud seguros, protección de endpoints, filtrado DNS, autenticación fuerte y monitoreo centralizado. La complejidad debe ajustarse al riesgo del sitio.
¿Por qué es importante la segmentación entre ubicaciones?
La segmentación limita accesos innecesarios entre usuarios, dispositivos, servidores, IoT y redes operativas. Reduce el impacto de una intrusión y mejora el control de políticas.
¿Qué debe revisarse antes de añadir una nueva sucursal?
Revise necesidades de ancho de banda, acceso a aplicaciones, direccionamiento IP, zonas de seguridad, diseño Wi-Fi, redundancia, acceso cloud, integración de monitoreo, reglas de nombre y responsabilidad de soporte.