La tecnología de recuperación ante desastres combina sistemas de copia de seguridad, infraestructura replicada, entornos de reserva, procedimientos de restauración, herramientas de supervisión y planes operativos para restablecer servicios empresariales después de una falla grave. Ayuda a las organizaciones a recuperarse de fallos de hardware, corrupción de datos, ransomware, incendios, inundaciones, cortes eléctricos, interrupciones de servicios en la nube, colapsos de red, eliminaciones accidentales o afectaciones completas de un sitio.
Su objetivo no es solo “guardar datos”. Un diseño completo de recuperación debe devolver a un estado utilizable las aplicaciones, bases de datos, servidores, sistemas de identidad, plataformas de comunicación, rutas de red, accesos de usuarios, políticas de seguridad y flujos operativos. Por eso la recuperación ante desastres es a la vez una arquitectura técnica y una disciplina de continuidad del negocio.
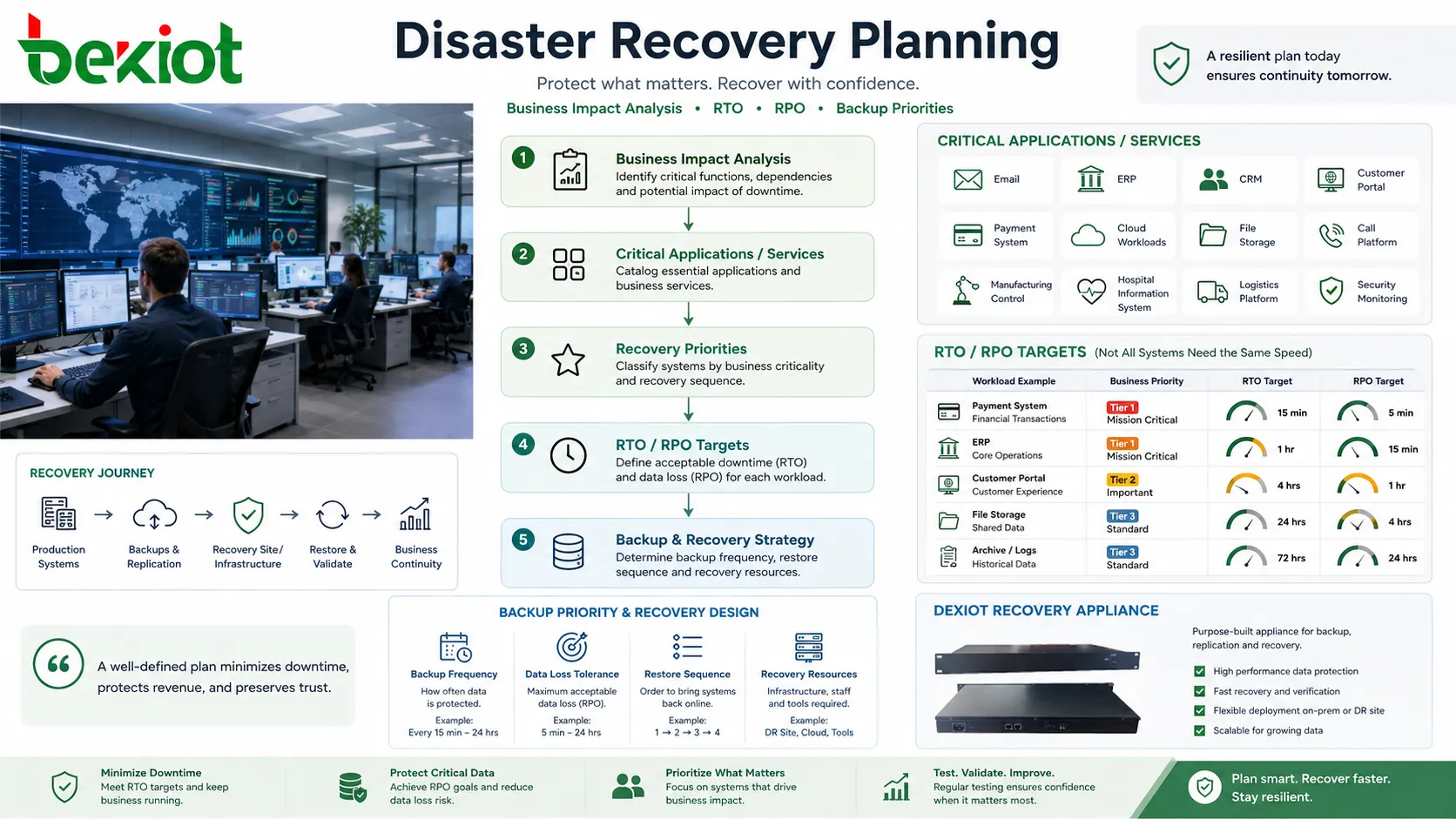
Partir del impacto en el negocio
Un plan confiable empieza por entender qué servicios son realmente críticos. El correo electrónico, ERP, CRM, portales de clientes, sistemas de pago, cargas de trabajo en la nube, almacenamiento de archivos, plataformas de llamadas, sistemas de control de fabricación, sistemas de información hospitalaria, plataformas logísticas y monitoreo de seguridad pueden tener prioridades de recuperación muy distintas.
No todos los sistemas necesitan la misma velocidad de recuperación. Un sistema transaccional público puede tener que volver en minutos, mientras que un sistema de archivo puede tolerar varias horas. Tratar todas las cargas de trabajo como igualmente urgentes aumenta el costo y la complejidad; tratar con ligereza las cargas importantes incrementa el riesgo empresarial.
Durante la planificación se usan con frecuencia dos conceptos. El objetivo de tiempo de recuperación, o RTO, define con qué rapidez debe restaurarse un servicio. El objetivo de punto de recuperación, o RPO, define cuánta pérdida de datos es aceptable, medida en tiempo. Por ejemplo, un RPO de 15 minutos significa que la organización debería poder recuperar los datos hasta un punto no anterior a 15 minutos antes de la falla.
Capas principales detrás de la tecnología
Capa de protección de datos
La primera capa técnica protege los datos. Puede incluir copias completas, copias incrementales, copias diferenciales, instantáneas, protección continua de datos, copias inmutables, volcados de bases de datos, versionado de almacenamiento de objetos y replicación fuera del sitio.
Una buena protección debe incluir varios puntos de restauración. Si la copia más reciente contiene datos dañados o cifrados, la organización puede necesitar volver a una versión limpia anterior. Esto es especialmente importante ante ransomware o eliminaciones accidentales.
Capa de recuperación de cómputo
Los datos por sí solos no bastan. Las aplicaciones necesitan servidores, máquinas virtuales, contenedores, sistemas operativos, entornos de ejecución, middleware, licencias y archivos de configuración. La capa de cómputo define dónde se ejecutarán las cargas de trabajo cuando falle el entorno principal.
La capacidad de cómputo de recuperación puede prepararse en otro centro de datos, una región de nube, un clúster de reserva, una plataforma virtualizada o un entorno gestionado de recuperación. Cuanto más preparado esté el entorno, más rápida puede ser la recuperación.
Capa de continuidad de red
Después de restaurar los sistemas, los usuarios y otros sistemas deben poder alcanzarlos. Esto requiere rutas de red, actualizaciones de DNS, acceso VPN, reglas de firewall, balanceadores de carga, planes de direcciones IP, certificados, políticas NAT y acceso remoto seguro.
La recuperación de red suele subestimarse. Una aplicación puede estar funcionando en el sitio de recuperación, pero los usuarios aún no pueden acceder porque no se actualizaron registros DNS, tablas de enrutamiento, rutas de identidad o reglas de firewall.
Capa de identidad y acceso
Usuarios, administradores, aplicaciones y cuentas de servicio necesitan autenticación y autorización después de una falla. Si los servicios de identidad no están disponibles, muchas aplicaciones recuperadas seguirán siendo inutilizables.
Los servicios de directorio, sistemas MFA, autoridades certificadoras, herramientas de acceso privilegiado, bóvedas de contraseñas y plataformas SSO deben incluirse en la planificación. Un sitio de recuperación sin control de identidad operativo puede convertirse en un problema de seguridad y operación.
Capa de orquestación operativa
La recuperación requiere acciones en el orden correcto. Las bases de datos pueden necesitar iniciarse antes que las aplicaciones. Las reglas de red pueden tener que cambiar antes de que se conecten los usuarios. El almacenamiento debe montarse antes de que corran los servicios. La supervisión debe confirmar que el sistema recuperado está sano.
Las herramientas de orquestación automatizan estos pasos. Pueden iniciar cargas de trabajo, aplicar scripts, actualizar configuraciones, activar failover, validar dependencias y generar informes de recuperación. La automatización reduce el error humano durante incidentes de alta presión.
Cómo suele ejecutarse el proceso de recuperación
Detección y confirmación del incidente
El proceso comienza cuando herramientas de monitoreo, usuarios, administradores o sistemas de seguridad detectan un evento anormal. Puede ser una falla de servidor, error de base de datos, interrupción de almacenamiento, alerta de ransomware, caída de aplicación, pérdida de energía en el sitio o problema de región de nube.
El equipo debe confirmar si el evento exige recuperación completa, restauración parcial o reparación local. No toda falla debe activar un failover completo. Un problema pequeño de aplicación puede resolverse más rápido que activar un entorno secundario.
Decisión y activación
Una vez confirmado el incidente, el personal autorizado decide si activa el plan de recuperación. La decisión debe basarse en el impacto en el negocio, la duración prevista de la interrupción, el riesgo para la seguridad, el impacto en clientes, la integridad de los datos y si el sitio principal puede restaurarse rápidamente.
La autoridad de decisión clara es fundamental. Si nadie sabe quién puede aprobar el failover, la organización puede perder tiempo valioso durante un incidente serio.
Restauración de datos o cambio de replicación
El entorno de recuperación necesita datos utilizables. Si el diseño usa copias de seguridad, el equipo restaura los datos desde un punto seleccionado. Si usa replicación, la copia en espera puede promoverse para uso activo.
La selección de datos es crítica. Restaurar la copia más nueva no siempre es correcto si la corrupción o el malware ya llegaron a esa copia. Los equipos pueden tener que identificar el último punto limpio de recuperación.
Reinicio de servicios y orden de dependencias
Las aplicaciones se reinician según sus dependencias. Bases de datos, almacenamiento, servicios de identidad, middleware, servidores de aplicación, front ends web, API e integraciones pueden necesitar una secuencia definida.
Saltar el orden de dependencias puede crear fallos confusos. Una aplicación recuperada puede parecer rota simplemente porque la base de datos, el servidor de licencias, la cola de mensajes o el registro DNS aún no está listo.
Validación antes de la entrega
Antes de que los usuarios vuelvan al servicio, el equipo debe validar que el entorno recuperado funciona. Esto puede incluir pruebas de inicio de sesión, comprobaciones de consistencia de datos, pruebas transaccionales, pruebas de llamadas, revisiones de API, generación de informes, revisión de seguridad y confirmación de monitoreo.
Solo después de validar debe tratarse el entorno de recuperación como servicio de producción activo. Una recuperación rápida pero no verificada puede generar pérdida de datos, brechas de seguridad o confusión para los usuarios.
La recuperación ante desastres funciona mejor cuando no se trata como una simple tarea de respaldo, sino como el reinicio coordinado de datos, sistemas, redes, identidades, usuarios y procesos de negocio.
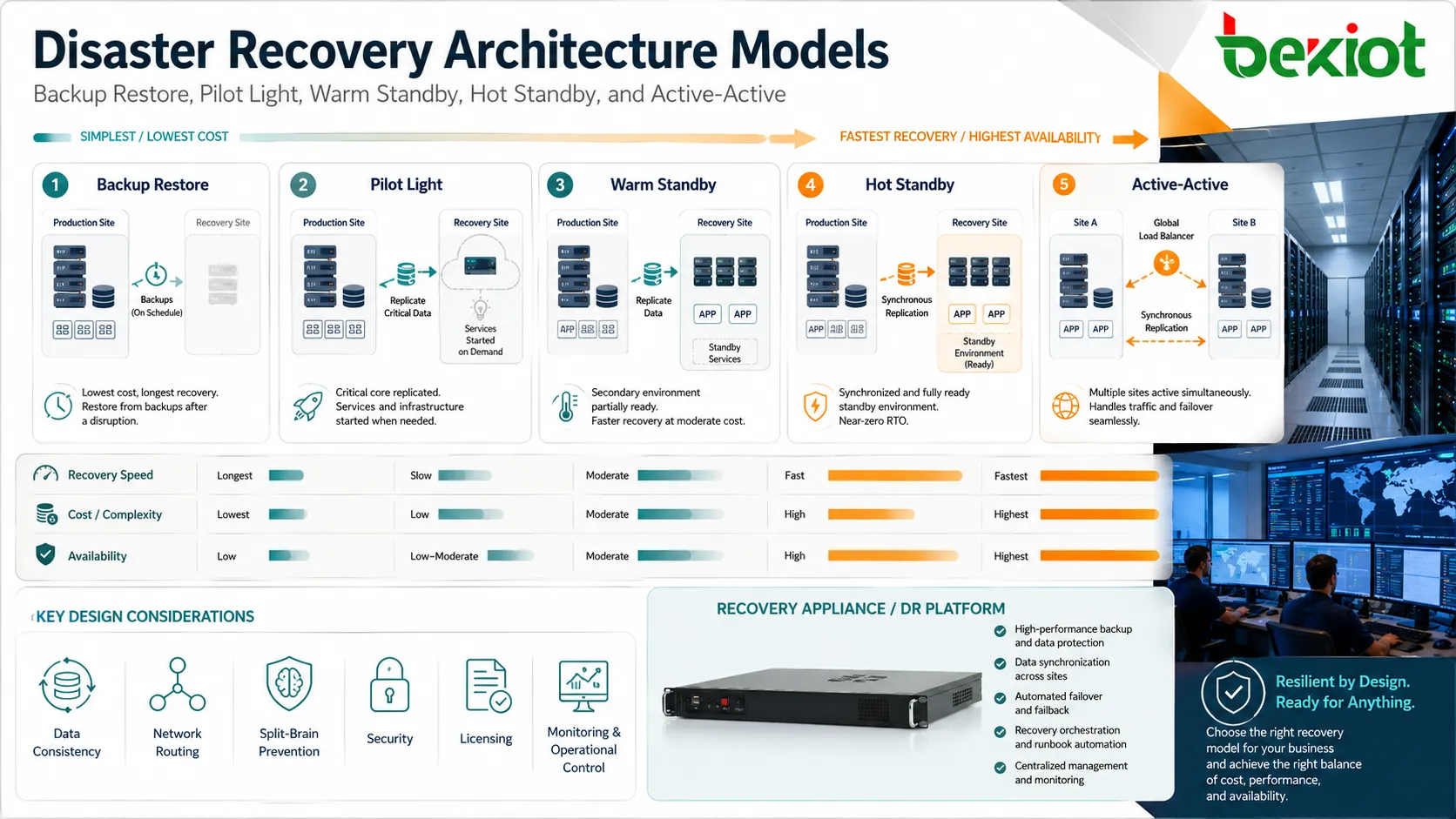
Modelos principales de arquitectura
Copia de seguridad y restauración
El modelo más simple almacena copias de seguridad y las restaura cuando se necesitan. Suele tener menor costo, pero es más lento porque servidores, aplicaciones, datos y configuraciones pueden tener que reconstruirse o restaurarse manualmente.
Este modelo puede servir para sistemas no críticos, pequeñas empresas, cargas de archivo o aplicaciones con mayor tolerancia al tiempo de inactividad. Aun así debe probarse, porque las copias no verificadas pueden fallar en una recuperación real.
Entorno de piloto mínimo
Un diseño de piloto mínimo mantiene funcionando un entorno de recuperación reducido. Componentes centrales como bases de datos, base de red, servicios de identidad o plantillas de configuración pueden existir ya, mientras que los servidores de aplicación se escalan solo durante la recuperación.
Este enfoque equilibra costo y velocidad. Es más rápido que construir todo desde cero y más económico que mantener en todo momento un entorno duplicado completo.
Reserva templada
Un entorno de reserva templada mantiene más sistemas activos de antemano. Los datos pueden replicarse con regularidad y los servicios de aplicación pueden estar instalados y parcialmente activos. Durante un incidente, el entorno se escala, promueve o reconfigura para manejar tráfico de producción.
Este modelo es útil cuando se debe reducir el tiempo de inactividad, pero un sitio secundario plenamente activo resulta demasiado costoso.
Reserva caliente o activo-activo
Los diseños más rápidos mantienen un entorno secundario continuamente sincronizado y listo para atender usuarios. En diseños activo-activo, varios sitios pueden manejar tráfico en vivo al mismo tiempo, con balanceo de carga y replicación entre ubicaciones.
Estos modelos reducen el tiempo de inactividad, pero requieren un diseño cuidadoso. La consistencia de datos, el enrutamiento de red, la prevención de split-brain, licencias, seguridad, monitoreo y control operativo se vuelven más complejos.
Características técnicas importantes
Programación automática de copias
Los calendarios automáticos reducen la dependencia de operaciones manuales. Los sistemas pueden crear copias por hora, diarias, semanales o continuas según el RPO requerido.
Los calendarios deben alinearse con el comportamiento de cada carga. Una base de datos que cambia cada minuto necesita una estrategia distinta a la de un archivo documental estático.
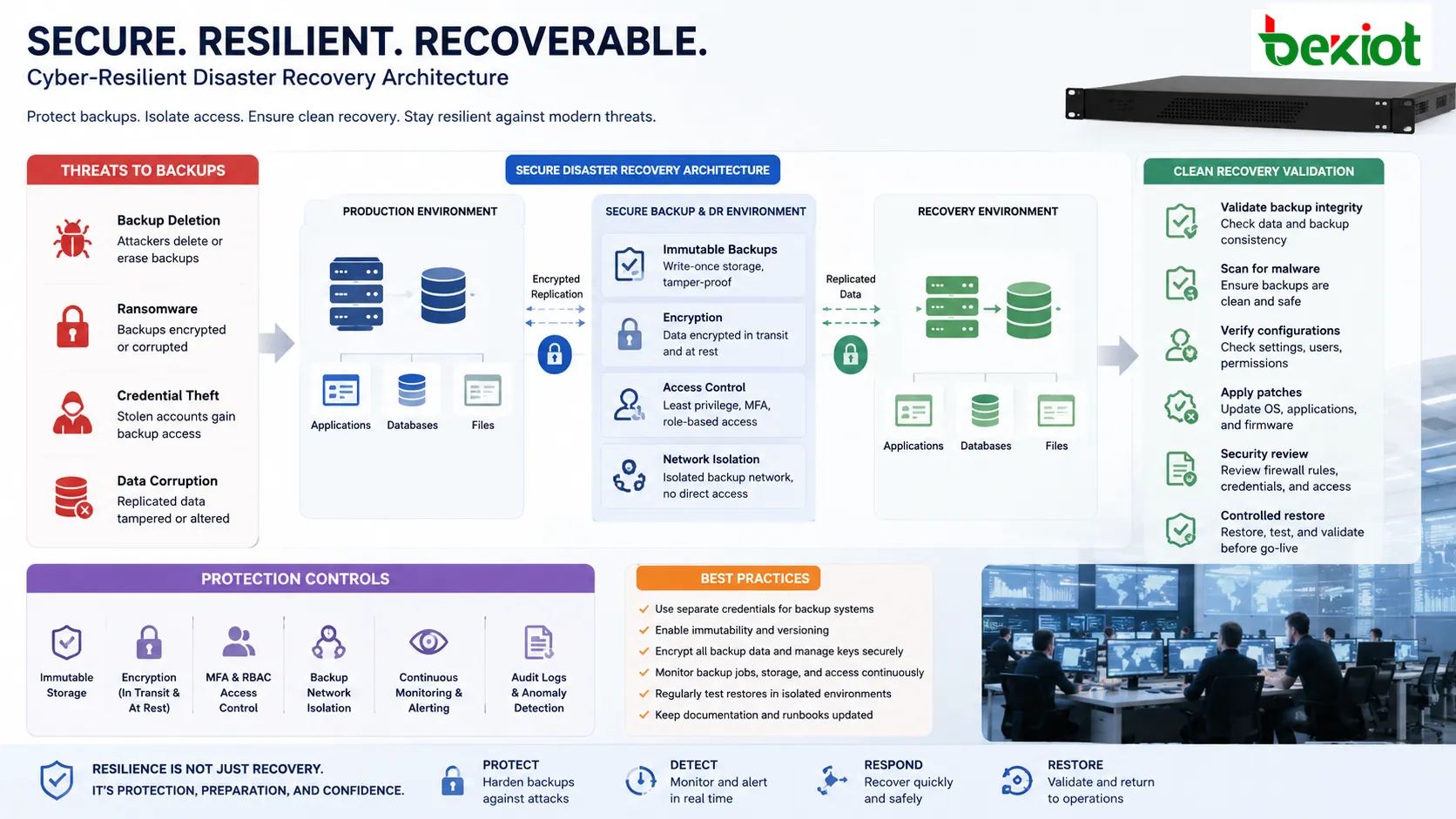
Copias inmutables y desconectadas
Las copias inmutables no pueden modificarse ni eliminarse durante un periodo definido. Las copias desconectadas o air-gapped se separan del entorno activo. Estas protecciones son importantes frente a ransomware, amenazas internas, eliminaciones accidentales y cuentas de administrador comprometidas.
Un plan que guarda todas las copias dentro del mismo entorno comprometido puede fallar precisamente cuando más se necesita.
Replicación y sincronización
La replicación copia datos del entorno principal a otra ubicación. Puede ser síncrona, cuando las escrituras se confirman en ambos lados antes de completarse, o asíncrona, cuando los cambios se copian poco después de ocurrir.
La replicación síncrona puede reducir la pérdida de datos, pero requiere enlaces de baja latencia y puede afectar el rendimiento. La replicación asíncrona es más flexible a distancia, pero puede perder cambios recientes si el sitio principal falla de repente.
Protección consciente de la aplicación
La protección consciente de la aplicación entiende la carga de trabajo respaldada. Bases de datos, sistemas de correo, máquinas virtuales, servidores de archivos y aplicaciones empresariales pueden necesitar pasos especiales para asegurar copias consistentes.
Por ejemplo, copiar archivos de base de datos mientras cambian puede no producir un punto de restauración limpio. Las instantáneas conscientes de la aplicación y el manejo de registros de transacciones pueden mejorar la calidad de la recuperación.
Automatización de la recuperación
La automatización puede iniciar máquinas virtuales, adjuntar almacenamiento, actualizar reglas de red, ejecutar scripts, ajustar DNS, verificar servicios y generar registros de incidentes. Reduce el trabajo manual y hace la recuperación más repetible.
La recuperación manual puede funcionar en entornos pequeños, pero los sistemas complejos suelen necesitar flujos documentados y automatizados para reducir errores bajo presión.
Aplicaciones en distintos entornos
Sistemas de TI empresarial
Las empresas usan tecnología de recuperación para proteger ERP, CRM, correo electrónico, sistemas de identidad, archivos compartidos, bases de datos, plataformas de intranet y aplicaciones de negocio. El objetivo es mantener disponibles las operaciones principales después de incidentes graves.
Estos entornos suelen requerir recuperación por niveles. Las aplicaciones de misión crítica reciben objetivos más rápidos, mientras que los sistemas menos urgentes usan protección de menor costo.
Infraestructura en la nube e híbrida
Los entornos en la nube admiten instantáneas, replicación entre regiones, infraestructura como código, bases de datos gestionadas, versionado de almacenamiento de objetos y patrones de failover automatizado. Los sistemas híbridos pueden combinar centros de datos locales con recursos de recuperación en la nube.
La recuperación basada en la nube puede reducir la necesidad de un segundo centro de datos completo, pero todavía exige planificación de red, diseño de seguridad, control de costos y pruebas periódicas.
Operaciones industriales y de servicios públicos
Fábricas, plantas eléctricas, sistemas de tratamiento de agua, instalaciones de petróleo y gas y centros logísticos pueden necesitar planes para sistemas de control, historiadores, servidores de monitoreo, plataformas de comunicación y estaciones de operador.
Estos entornos deben considerar seguridad física, control de procesos en tiempo real, protocolos heredados, acceso a dispositivos de campo y control estricto de cambios. La recuperación no debe crear condiciones operativas inseguras.
Salud y servicios públicos
Hospitales, centros de respuesta a emergencias, servicios gubernamentales e instalaciones públicas necesitan acceso a registros, comunicaciones, programación, sistemas de seguridad y datos operativos durante interrupciones.
La planificación debe incluir privacidad, pistas de auditoría, impacto en pacientes o ciudadanos, procedimientos de emergencia y acceso del personal bajo condiciones anormales.
Telecomunicaciones y servicios de comunicación
Las plataformas de comunicación requieren recuperación para control de llamadas, enrutamiento, servicios multimedia, grabación, buzón de voz, troncales SIP, gateways, plataformas de contact center y datos de registro de usuarios.
Como los sistemas de comunicación suelen apoyar la respuesta de emergencia y la interacción con clientes, las pruebas deben incluir flujos reales de llamadas y no solo el arranque de servidores.
Integridad de datos y ciberseguridad
La planificación moderna debe asumir que los ciberataques pueden dirigirse tanto a copias de seguridad como a sistemas de producción. Los atacantes pueden borrar copias, cifrar repositorios, robar credenciales o corromper datos replicados. Por eso son esenciales el aislamiento de copias, el control de acceso, la inmutabilidad, el cifrado y la supervisión.
Los datos de recuperación deben protegerse en tránsito y en reposo. Las claves de cifrado deben administrarse con cuidado, porque perder la clave puede hacer imposible la recuperación. Los repositorios de copias no deben usar las mismas credenciales y permisos que las cuentas normales de producción.
La validación de seguridad después de recuperar también es importante. Restaurar un sistema desde una copia puede restaurar software obsoleto, configuraciones vulnerables o cuentas comprometidas. Los equipos deben revisar parches, credenciales, reglas de firewall y seguridad de endpoints antes de devolver el servicio a los usuarios.
Pruebas y simulacros de preparación
Un plan de recuperación que nunca se prueba es solo una suposición. Las pruebas confirman si las copias son restaurables, las aplicaciones arrancan correctamente, los usuarios pueden iniciar sesión, los datos son consistentes, las rutas de red funcionan y el personal sabe qué hacer.
Las pruebas pueden ejecutarse en distintos niveles. Una prueba de restauración de archivos comprueba si pueden recuperarse datos individuales. Una prueba de recuperación de aplicación comprueba si un servicio puede restaurarse. Una simulación completa prueba una falla de sitio y todo el proceso de failover.
Los simulacros deben documentarse. El equipo debe registrar tiempo de recuperación, problemas encontrados, accesos faltantes, scripts fallidos, documentación desactualizada y acciones correctivas. Cada prueba debe mejorar el plan.
Puntos comunes de falla
Copias que nunca se restauraron
Muchas organizaciones descubren demasiado tarde que sus tareas de copia finalizaron, pero los datos no pueden restaurarse correctamente. Puede ocurrir por archivos corruptos, dependencias faltantes, credenciales incorrectas, versiones no compatibles o datos de aplicación incompletos.
La prueba de restauración es la única forma confiable de demostrar que los datos respaldados son útiles.
Archivos de configuración faltantes
Las aplicaciones pueden depender de archivos de configuración, certificados, variables de entorno, tablas de enrutamiento, reglas de firewall, licencias y cuentas de servicio. Si esos elementos no se protegen, los datos pueden restaurarse, pero la aplicación puede no ejecutarse.
La copia de configuraciones debe tratarse como parte del alcance de recuperación.
Propiedad poco clara
Durante un incidente, la confusión sobre quién toma decisiones puede retrasar la recuperación. TI, seguridad, operaciones, responsables de negocio, equipos de nube y proveedores pueden estar involucrados.
El plan debe definir roles, autoridad de aprobación, contactos de escalamiento y canales de comunicación antes de que ocurra una crisis.
Replicación de datos defectuosos
La replicación es útil, pero también puede copiar corrupción, eliminación o archivos cifrados al sitio secundario. Por eso la recuperación a un punto en el tiempo y las copias inmutables siguen siendo importantes incluso cuando existe replicación.
La replicación mejora la continuidad; no sustituye puntos históricos limpios de recuperación.
Acceso de red no preparado
Una aplicación recuperada no sirve si los usuarios no pueden alcanzarla. DNS, VPN, firewall, balanceador de carga, certificado, enrutamiento e identidad deben incluirse en las pruebas.
La preparación de red suele marcar la diferencia entre una restauración técnica y un servicio realmente utilizable.
La verdadera medida de la tecnología de recuperación no es si los datos existen en algún lugar, sino si las personas correctas pueden reanudar con seguridad el servicio correcto dentro del tiempo requerido.
Lista de verificación de implementación
Clasifique los sistemas por prioridad de negocio. Defina RTO y RPO para cada servicio en lugar de usar un objetivo genérico para todo.
Elija el método de protección adecuado. Copia y restauración, instantáneas, replicación, entornos de reserva y diseños activo-activo responden a necesidades y niveles de costo distintos.
Proteja las copias frente al riesgo cibernético. Use inmutabilidad, credenciales separadas, cifrado, mínimo privilegio, monitoreo de copias y copias desconectadas o aisladas cuando corresponda.
Documente los pasos de recuperación. Incluya dependencias del sistema, orden de arranque, cambios de red, métodos de inicio de sesión, contactos de proveedores, requisitos de licencias y pruebas de validación.
Pruebe con regularidad. Un proceso de recuperación debe practicarse antes de un incidente real. Actualice el plan después de cambios de infraestructura, migraciones a la nube, actualizaciones de aplicaciones y cambios de política de seguridad.
FAQ
¿El alojamiento en la nube proporciona recuperación ante desastres automáticamente?
No. Las plataformas en la nube proporcionan herramientas útiles, pero el cliente aún debe configurar copias, replicación, regiones, permisos, monitoreo, procedimientos de recuperación y pruebas.
¿Con qué frecuencia deben probarse los planes de recuperación?
La frecuencia depende del riesgo empresarial y de la criticidad del sistema. Los sistemas críticos pueden requerir simulacros regulares, mientras que los menos importantes pueden probarse durante revisiones programadas o después de cambios mayores.
¿Puede el ransomware afectar los sistemas de copias de seguridad?
Sí. Los atacantes pueden apuntar a repositorios de copias y credenciales de administrador. Las copias inmutables, copias desconectadas, permisos separados y monitoreo ayudan a reducir ese riesgo.
¿Cuál es la diferencia entre alta disponibilidad y recuperación ante desastres?
La alta disponibilidad se centra en mantener los servicios funcionando durante fallas menores. La recuperación ante desastres se centra en restaurar servicios después de interrupciones mayores, incluidas fallas de sitio, ciberataques o pérdidas importantes de datos.
¿Qué debe revisarse después de un evento real de recuperación?
Deben revisarse el tiempo de recuperación, la pérdida de datos, los pasos fallidos, las brechas de comunicación, el impacto en usuarios, los hallazgos de seguridad, la respuesta de proveedores, la precisión de la documentación y las mejoras necesarias antes del siguiente incidente.