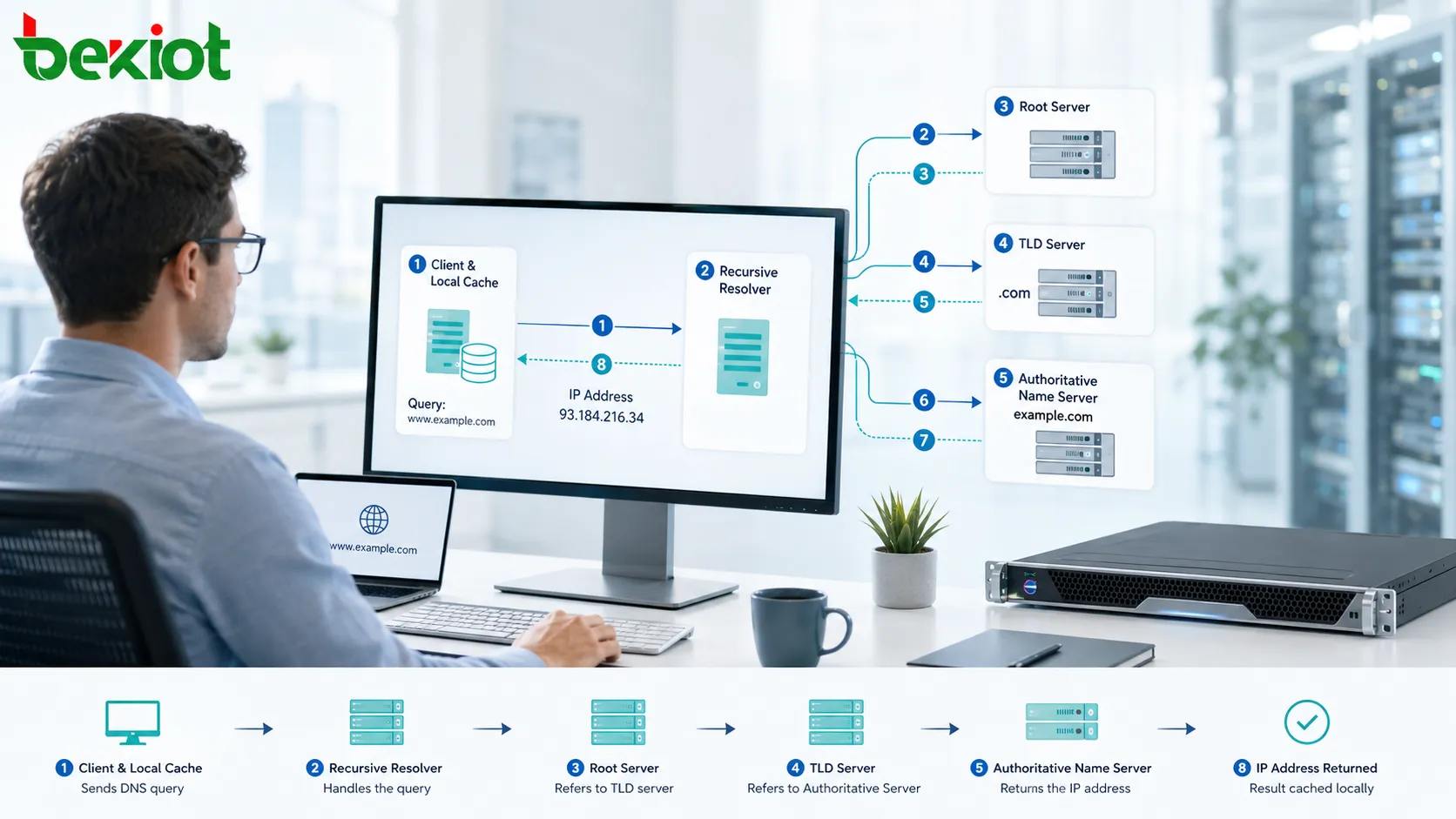
El uptime es el tiempo durante el cual un sistema, servicio, dispositivo, aplicación, red o plataforma permanece disponible y funcionando correctamente. En términos sencillos, indica a los usuarios cuánto tiempo algo ha estado operando sin interrupciones. Cuando un sitio web es accesible, un servidor está en ejecución, una plataforma de comunicación está en línea o un dispositivo de red sigue funcionando con normalidad, ese período se contabiliza como uptime.
El uptime es uno de los indicadores de fiabilidad más importantes en entornos de TI, redes, telecomunicaciones, servicios en la nube, sistemas industriales, sitios web, centros de datos, plataformas de seguridad y comunicaciones empresariales. Ayuda a las organizaciones a entender si sus sistemas son lo suficientemente confiables para soportar las operaciones diarias. Un servicio con alto uptime está disponible la mayor parte del tiempo. Un servicio con bajo uptime puede sufrir interrupciones frecuentes, caídas, reinicios o períodos de indisponibilidad.
En la operación real, el uptime no es solo una cifra técnica. Afecta la experiencia del cliente, la continuidad del negocio, la reputación del servicio, la respuesta ante emergencias, la productividad y la confianza operativa. Si un sistema no está disponible cuando las personas lo necesitan, incluso un conjunto de funciones potente puede perder su valor práctico. Por eso el uptime se suele analizar junto con la monitorización, la redundancia, la planificación del mantenimiento, los acuerdos de nivel de servicio y la recuperación ante desastres.
¿Qué es el uptime?
Definición y significado principal
El uptime se refiere al período durante el cual un sistema o servicio está funcionando y disponible para su uso. Puede aplicarse a un servidor, router, switch, sitio web, aplicación, base de datos, plataforma en la nube, centralita IP, sistema de seguridad, controlador industrial o cualquier dispositivo conectado del que dependan los usuarios. Si se puede acceder al sistema y funciona como se espera, se considera que está operativo.
El significado central del uptime es la disponibilidad a lo largo del tiempo. No significa simplemente que un dispositivo tenga corriente. Un servidor puede estar encendido pero no responder a los usuarios. Un dispositivo de red puede estar funcionando pero no transmitir tráfico correctamente. Un sitio web puede cargarse parcialmente pero fallar en sus funciones clave. Para una medición práctica del uptime, el sistema normalmente debe estar disponible de manera que preste el servicio previsto.
Por eso el uptime debe definirse según el propósito real del sistema. Una comprobación de uptime de un sitio web puede centrarse en la respuesta de la página. Un servicio de comunicación puede enfocarse en el registro, la señalización y la finalización de llamadas. Una plataforma de base de datos puede centrarse en la respuesta a consultas. Un sistema de monitorización puede centrarse en la recogida de datos y la disponibilidad de alertas.
El uptime no consiste solo en si el equipo está encendido. Se trata de si el servicio esperado está realmente disponible cuando los usuarios lo necesitan.
Uptime frente a disponibilidad
El uptime y la disponibilidad están estrechamente relacionados y, en muchas conversaciones cotidianas, se usan casi indistintamente. Sin embargo, la disponibilidad suele considerarse una métrica de servicio más amplia. El uptime describe cuánto tiempo permanece operativo el sistema, mientras que la disponibilidad puede incluir si el sistema puede ofrecer la función requerida a los usuarios en condiciones reales.
Por ejemplo, un proceso de servidor puede estar ejecutándose, pero si los usuarios no pueden acceder a él debido a un problema de red, el servicio podría seguir sin estar disponible. En ese caso, el servidor en sí puede tener uptime, pero el servicio de cara al usuario no tiene disponibilidad completa. Esta distinción es importante en sistemas complejos donde muchos componentes trabajan juntos.
En la gestión práctica de servicios, las organizaciones suelen preocuparse más por la disponibilidad percibida por el usuario. El servicio debe funcionar desde la perspectiva del usuario, no solo desde la pantalla de estado local del dispositivo.

Cómo funciona el uptime
Medición del tiempo operativo
El uptime funciona midiendo el tiempo que un sistema permanece en un estado saludable y disponible. Puede medirse desde el momento de arranque del sistema, el inicio del servicio, el tiempo de respuesta de la monitorización o una ventana definida de disponibilidad del servicio. El método depende de lo que se esté midiendo y de lo que la organización considere operativo.
Para un solo dispositivo, el uptime puede mostrarse como el tiempo transcurrido desde el último reinicio. Para un sitio web, el uptime puede medirse mediante sondas externas que verifican si el sitio responde correctamente. Para un servicio de red, el uptime puede depender de si los usuarios pueden conectarse, autenticarse, intercambiar datos y completar la transacción prevista.
La medición de uptime más útil está ligada al comportamiento del servicio. Un sistema que técnicamente está funcionando pero que falla en su función principal no debería contabilizarse como totalmente disponible en un modelo operativo serio.
Seguimiento del tiempo de inactividad y del porcentaje de disponibilidad
El uptime se expresa a menudo como un porcentaje a lo largo de un período definido, como un mes o un año. La fórmula básica compara el tiempo que el sistema estuvo disponible con el tiempo total que se está midiendo. Si un servicio estuvo disponible durante casi todo el período, su porcentaje de uptime será alto. Si experimentó interrupciones prolongadas, el porcentaje disminuirá.
Por ejemplo, un servicio disponible el 99,9 % del mes tiene menos tiempo de inactividad que uno disponible el 99 %. Estos porcentajes pueden parecer cercanos, pero la diferencia real en tiempo de inactividad puede ser significativa. Pequeñas diferencias porcentuales importan mucho en sistemas que soportan operaciones de negocio, acceso de clientes o comunicaciones críticas.
Por eso el uptime se utiliza a menudo en los acuerdos de nivel de servicio. Un proveedor puede comprometerse a un cierto porcentaje de uptime, y los clientes usan ese compromiso para entender la fiabilidad esperada del servicio.
El porcentaje de uptime parece sencillo, pero pequeñas diferencias pueden representar cantidades muy diferentes de tiempo de inactividad real.
Niveles de uptime habituales y su significado
Comprender el 99 %, 99,9 % y 99,99 % de uptime
El uptime se suele discutir en términos de "nueves". Un sistema con un 99 % de uptime está disponible la mayor parte del tiempo, pero aún permite una cantidad significativa de inactividad al año. Un sistema con un 99,9 % de uptime es más fiable y permite mucho menos tiempo de inactividad. Un sistema con un 99,99 % de uptime es considerablemente más exigente y generalmente requiere un diseño más sólido, mejor monitorización y mayor disciplina operativa.
Cuanto más alto es el objetivo de uptime, más difícil resulta alcanzarlo. Pasar del 99 % al 99,9 % puede requerir mejor monitorización y mantenimiento. Pasar del 99,9 % al 99,99 % puede exigir redundancia, conmutación por error, arquitectura de alta disponibilidad, mejor control de cambios y una respuesta a incidentes más rápida.
En la planificación práctica, las organizaciones no deberían elegir objetivos de uptime solo porque suenen impresionantes. Deben ajustar el objetivo al riesgo empresarial, al coste, a las expectativas de los usuarios y a la importancia operativa.
Por qué un mayor uptime cuesta más
Un mayor uptime suele requerir más inversión. Un solo servidor sin redundancia es más fácil y barato de desplegar, pero tiene puntos de fallo evidentes. Un sistema de alta disponibilidad puede necesitar servidores de respaldo, alimentación redundante, múltiples rutas de red, balanceadores de carga, bases de datos con conmutación por error, herramientas de monitorización y personal de operaciones cualificado.
El coste no es solo de hardware. Incluye planificación, pruebas, procedimientos de mantenimiento, formación del personal, arquitectura de software, respuesta a incidentes y, a veces, redundancia geográfica. Cada capa adicional mejora la resiliencia, pero también aumenta la complejidad.
Por eso el uptime debe tratarse como un requisito de diseño, no solo como una afirmación comercial. El nivel de fiabilidad requerido debe estar respaldado por una arquitectura y procesos operativos reales.

Factores clave que afectan al uptime
Fiabilidad del hardware y estabilidad eléctrica
La fiabilidad del hardware es uno de los factores más básicos que afectan al uptime. Los servidores, dispositivos de almacenamiento, switches, routers, fuentes de alimentación, ventiladores, discos y otros componentes físicos pueden fallar. Si un componente crítico falla sin una ruta de respaldo, el servicio puede caerse.
La estabilidad eléctrica es igualmente importante. Incluso los sistemas más robustos pueden fallar si el suministro eléctrico se interrumpe o es inestable. Los centros de datos y las instalaciones críticas suelen utilizar sistemas de alimentación ininterrumpida (SAI), generadores de respaldo, doble acometida eléctrica y monitorización del consumo para reducir este riesgo.
En entornos más pequeños, incluso mejoras sencillas como una protección eléctrica fiable y un mantenimiento adecuado de los equipos pueden mejorar el uptime de forma notable.
Conectividad de red y estabilidad del enrutamiento
La conectividad de red afecta enormemente al uptime porque muchos servicios dependen de llegar a los usuarios a través de redes locales, redes de área amplia o Internet. Un servidor puede estar en buen estado, pero si la ruta de red falla, los usuarios pueden experimentar igualmente una interrupción. Los fallos en switches, errores de enrutamiento, problemas de DNS, configuraciones incorrectas de cortafuegos y cortes del proveedor de Internet (ISP) pueden afectar la disponibilidad del servicio.
Los enlaces de red redundantes, la diversidad de proveedores, un diseño de enrutamiento sólido, una gestión adecuada de DNS y la monitorización continua pueden ayudar a mejorar el uptime. En los sistemas de comunicación empresarial, la estabilidad de la red es especialmente importante porque la voz, el vídeo, la mensajería y las aplicaciones en la nube dependen de una conectividad fiable.
En términos prácticos, el uptime debe medirse a lo largo de toda la ruta de servicio, no solo en el dispositivo principal.
Uptime y arquitectura del sistema
Redundancia y conmutación por error
La redundancia es uno de los métodos arquitectónicos más comunes para mejorar el uptime. Consiste en tener componentes o rutas de respaldo listos para cuando falle el componente principal. Esto puede incluir servidores, fuentes de alimentación, discos, switches, enlaces de red, bases de datos, pasarelas o centros de datos redundantes.
La conmutación por error (failover) es el proceso de transferir el servicio del componente que ha fallado al componente de respaldo. En un sistema bien diseñado, la conmutación por error puede producirse automáticamente, con poca o ninguna interrupción para el usuario. En sistemas más sencillos, la conmutación por error puede requerir intervención manual.
La redundancia y la conmutación por error no eliminan todos los riesgos, pero reducen la probabilidad de que un solo fallo detenga todo el servicio. Son esenciales en sistemas donde el tiempo de inactividad tiene un impacto significativo en el negocio o en la seguridad.
Balanceo de carga y diseño de alta disponibilidad
El balanceo de carga también puede contribuir al uptime distribuyendo el tráfico entre múltiples servidores o instancias de servicio. Si un servidor se sobrecarga o falla, otros servidores pueden seguir gestionando las solicitudes. Esto mejora tanto el rendimiento como la resiliencia cuando se implementa correctamente.
El diseño de alta disponibilidad combina múltiples técnicas, como redundancia, conmutación por error, agrupación en clústeres, replicación, comprobaciones de estado, recuperación automatizada y monitorización. El objetivo es mantener el servicio disponible incluso cuando fallan componentes individuales.
Un sistema de alta disponibilidad debe probarse cuidadosamente. Los componentes redundantes solo son útiles si realmente asumen el control correctamente cuando se produce un fallo.
El uptime se construye desde la arquitectura, no desde las ilusiones. Un sistema fiable necesita rutas de fallo que hayan sido diseñadas y probadas antes de que ocurra el fallo.
Monitorización del uptime
Monitorización interna y externa
La monitorización del uptime comprueba si un sistema o servicio está disponible. La monitorización interna observa los componentes desde dentro del entorno, como la CPU del servidor, la memoria, el estado del disco, el estado de los procesos, el estado de la base de datos y la conectividad de red local. La monitorización externa verifica el servicio desde fuera, más cerca de la perspectiva del usuario.
Ambos métodos son útiles. La monitorización interna puede detectar signos tempranos de fallo antes de que los usuarios se vean afectados. La monitorización externa puede confirmar si el servicio es realmente accesible desde el exterior. Un sistema puede parecer saludable internamente pero seguir siendo inaccesible debido a problemas de DNS, enrutamiento, cortafuegos o redes aguas arriba.
Una buena estrategia de monitorización suele combinar tanto comprobaciones internas como externas para crear una visión más completa del uptime.
Comprobaciones de estado, alertas y respuesta a incidentes
Las comprobaciones de estado (health checks) son pruebas automatizadas que confirman si un sistema funciona como se espera. Una comprobación sencilla puede confirmar que un servidor responde a una solicitud. Una comprobación más avanzada puede verificar el inicio de sesión, la respuesta de la base de datos, el registro de llamadas, la finalización de transacciones o el comportamiento de la API.
Las alertas notifican a los administradores cuando el uptime está amenazado o se produce una interrupción. Sin embargo, las alertas por sí solas no bastan. La organización también debe contar con un proceso de respuesta a incidentes que defina quién investiga, cómo se escalan los problemas, cómo se informa a los usuarios y cómo se restaura el servicio.
La monitorización alcanza su máximo valor cuando conecta la detección con la acción. Conocer rápidamente una interrupción solo es útil si el equipo puede responder de forma eficaz.
Uptime y SLA
Acuerdos de nivel de servicio
Un acuerdo de nivel de servicio (SLA, por sus siglas en inglés) puede definir el porcentaje de uptime que un proveedor de servicios o un equipo interno se compromete a ofrecer. Por ejemplo, un proveedor puede prometer un 99,9 % de uptime durante un período de facturación mensual. El SLA también puede explicar qué cuenta como tiempo de inactividad, qué ventanas de mantenimiento se excluyen y qué compensaciones o créditos se aplican si no se alcanza el objetivo.
La redacción del SLA es importante porque el uptime puede interpretarse de diferentes maneras. Algunos acuerdos excluyen el mantenimiento programado. Algunos solo contabilizan la interrupción total del servicio, no la degradación parcial del rendimiento. Algunos miden la disponibilidad desde la red del proveedor y no desde la ubicación del cliente.
Por esta razón, los usuarios deben leer atentamente las definiciones del SLA. El porcentaje de uptime anunciado es importante, pero las reglas de medición lo son igualmente.
Mantenimiento planificado frente a tiempo de inactividad no planificado
El mantenimiento planificado es un trabajo programado que puede afectar temporalmente la disponibilidad del sistema. Puede incluir actualizaciones de firmware, actualizaciones de software, sustitución de hardware, mantenimiento de bases de datos, aplicación de parches de seguridad o cambios en la infraestructura. Muchos cálculos de uptime tratan el mantenimiento planificado de forma diferente a las interrupciones inesperadas.
El tiempo de inactividad no planificado se produce cuando un sistema falla inesperadamente debido a un fallo de hardware, un bloqueo de software, un corte de red, un error de configuración, un ciberataque, una pérdida de alimentación o un error humano. Este tipo de interrupción suele ser más perjudicial porque los usuarios no están preparados para ella.
Una buena gestión del uptime reduce el tiempo de inactividad no planificado y comunica claramente el mantenimiento programado para que los usuarios puedan prepararse.
Consejos de mantenimiento para mejorar el uptime
Aplique mantenimiento preventivo
El mantenimiento preventivo ayuda a mejorar el uptime al abordar los problemas antes de que se conviertan en interrupciones. Esto puede incluir la revisión de registros, la actualización del firmware, la aplicación de parches de seguridad, la sustitución de hardware envejecido, la monitorización de la capacidad de almacenamiento, la prueba de las copias de seguridad y la revisión de las tendencias de rendimiento del sistema.
El mantenimiento preventivo debe planificarse y documentarse. Los cambios aleatorios pueden crear nuevos problemas, pero un mantenimiento controlado ayuda a reducir el riesgo. El objetivo es mantener los sistemas en buen estado sin causar interrupciones innecesarias.
En las operaciones prácticas, muchas interrupciones se pueden evitar cuando los equipos de mantenimiento actúan antes de que las señales de advertencia se conviertan en fallos.
Controle los cambios cuidadosamente
Los cambios de configuración son una fuente habitual de tiempo de inactividad. Una regla de cortafuegos, un cambio de enrutamiento, una actualización de software, la sustitución de un certificado, un ajuste en la base de datos o un cambio en la política de acceso pueden interrumpir accidentalmente el servicio si no se revisan adecuadamente. El control de cambios ayuda a reducir este riesgo.
Un buen control de cambios incluye documentación, aprobación, pruebas, plan de reversión, elección del momento y verificación posterior al cambio. En los sistemas críticos, los cambios deben realizarse durante períodos de bajo impacto y supervisarse de cerca después.
El uptime a menudo depende tanto de unas operaciones disciplinadas como de un hardware sólido.
Muchos problemas de uptime no empiezan con equipos averiados. Empiezan con cambios descontrolados, hábitos de mantenimiento deficientes o falta de verificación.
Aplicaciones de la medición del uptime
Sitios web, servicios en la nube y aplicaciones
Los sitios web, los servicios en la nube y las aplicaciones utilizan la medición del uptime para evaluar si los usuarios pueden acceder a los servicios digitales cuando los necesitan. Los sitios de comercio electrónico, las plataformas SaaS, los sistemas de banca en línea, los portales de clientes, las plataformas de streaming y las aplicaciones empresariales dependen de una alta disponibilidad.
En estos entornos, el tiempo de inactividad puede provocar pérdida de ingresos, frustración de los clientes, daños a la reputación e interrupción de los flujos de trabajo internos. La monitorización del uptime ayuda a las organizaciones a detectar problemas rápidamente y evaluar si el rendimiento del servicio cumple con las expectativas de los usuarios.
Para los servicios orientados al cliente, el uptime es a menudo una de las señales más visibles de fiabilidad.
Redes, sistemas de comunicación e infraestructura
El uptime también es crítico en redes y sistemas de comunicación. Los routers, switches, cortafuegos, plataformas IP PBX, servidores SIP, pasarelas, sistemas de despacho, redes de intercomunicación, sistemas de seguridad y plataformas de monitorización necesitan un funcionamiento fiable. Si estos sistemas fallan, la comunicación de voz, el acceso a datos, las alarmas, el control de acceso y la coordinación operativa pueden verse afectados.
El uptime de la infraestructura es especialmente importante porque muchos otros servicios dependen de ella. Una aplicación en la nube puede estar en buen estado, pero si la red local no funciona, los usuarios no pueden acceder a ella. Una plataforma de comunicación puede estar funcionando, pero si una pasarela o un enlace troncal fallan, las llamadas pueden no completarse.
Por eso el uptime de la infraestructura suele monitorizarse en múltiples capas, desde los dispositivos físicos hasta los servicios de cara al usuario.
Causas comunes del tiempo de inactividad
Fallos técnicos
Los fallos técnicos incluyen el mal funcionamiento del hardware, los bloqueos de software, las fugas de memoria, los problemas de base de datos, los fallos de disco, los fallos de equipos de red, las interrupciones del suministro eléctrico, los problemas de refrigeración y el agotamiento de recursos. Son causas comunes de tiempo de inactividad en muchos entornos.
Algunos fallos técnicos ocurren de repente, mientras que otros se desarrollan gradualmente. Un disco puede mostrar advertencias antes de fallar. Un servidor puede ralentizarse antes de bloquearse. Un enlace de red puede mostrar pérdida de paquetes antes de la interrupción total. La monitorización ayuda a detectar signos tempranos para que los equipos puedan actuar antes.
La redundancia, las alertas, la planificación de la capacidad y el mantenimiento preventivo contribuyen a reducir el efecto de los fallos técnicos.
Error humano y debilidad de los procesos
El error humano es otra causa importante de tiempo de inactividad. Un comando equivocado, un borrado accidental, una regla de cortafuegos mal configurada, un archivo de firmware incorrecto, un certificado caducado o una actualización mal probada pueden tirar un servicio. En muchos casos, el sistema no falla porque el hardware sea débil, sino porque el proceso operativo es deficiente.
Los controles de proceso ayudan a reducir este riesgo. La documentación, el control de acceso, la revisión por pares, la aprobación de cambios, las copias de seguridad, los entornos de preproducción y los planes de reversión reducen el impacto de los errores humanos. La formación también es importante, porque los administradores necesitan comprender tanto el sistema como las consecuencias de los cambios.
Una gestión sólida del uptime trata a las personas, los procesos y la tecnología como un único sistema de fiabilidad.
Cómo mejorar el uptime
Diseñe para el fallo
Mejorar el uptime empieza por diseñar pensando en el fallo. Todos los componentes pueden fallar en algún momento. Un sistema fiable asume que el fallo ocurrirá e incluye rutas de respaldo, monitorización, procedimientos de recuperación y un comportamiento de conmutación por error probado.
Este enfoque cambia la mentalidad de diseño. En lugar de preguntarse si un componente fallará, el equipo se pregunta qué sucede cuando falle. Si la respuesta es que todo el servicio se detiene, es posible que el diseño necesite mejoras. Si la respuesta es que el tráfico se desvía a una ruta de respaldo y los usuarios siguen trabajando, el sistema es más resistente.
Diseñar para el fallo es uno de los principios fundamentales que hay detrás de un alto uptime.
Mida lo que los usuarios realmente experimentan
La mejora del uptime debe centrarse en la experiencia del usuario, no solo en el estado interno. Un panel de servidor puede mostrar que el proceso está en ejecución, pero los usuarios pueden seguir sin poder iniciar sesión, hacer llamadas, abrir archivos o completar transacciones. Por lo tanto, la monitorización debe incluir comprobaciones de servicio de extremo a extremo siempre que sea posible.
La medición centrada en el usuario ayuda a descubrir problemas que las comprobaciones a nivel de componente podrían pasar por alto. También ayuda a las organizaciones a comprender el impacto real del tiempo de inactividad en el negocio. Si los usuarios no pueden completar la tarea del servicio, el sistema no está realmente disponible desde su punto de vista.
Los mejores programas de uptime miden tanto la salud técnica como el comportamiento del servicio de cara al usuario.
Conclusión
El uptime es la medida del tiempo que un sistema, dispositivo, servicio o plataforma permanece operativo y disponible. Es un indicador clave de fiabilidad en sitios web, plataformas en la nube, redes, sistemas de comunicación, centros de datos, infraestructura industrial y aplicaciones empresariales. Un alto uptime significa que los usuarios pueden confiar en el servicio cuando lo necesitan.
El uptime funciona rastreando el tiempo de servicio disponible y comparándolo con el tiempo total medido. Se ve influenciado por la fiabilidad del hardware, la conectividad de red, la estabilidad eléctrica, la calidad del software, la arquitectura del sistema, la monitorización, el mantenimiento y la disciplina operativa. Un uptime sólido suele requerir redundancia, conmutación por error, mantenimiento preventivo, cambios controlados y una monitorización realista del servicio.
En términos prácticos, el uptime no es solo un porcentaje. Es un reflejo de lo bien que un sistema ha sido diseñado, operado, monitorizado y mantenido para satisfacer a usuarios reales y necesidades empresariales reales.
Preguntas frecuentes
¿Qué significa uptime en términos sencillos?
En términos sencillos, el uptime es la cantidad de tiempo que un sistema o servicio está funcionando y disponible para su uso. Si un sitio web, servidor, red o dispositivo funciona correctamente, ese período cuenta como uptime.
Se utiliza habitualmente para medir la fiabilidad.
¿Cómo se calcula el uptime?
El uptime suele calcularse comparando el tiempo que un sistema estuvo disponible con el tiempo total del período de medición. El resultado suele mostrarse como un porcentaje, por ejemplo, 99,9 % de uptime.
El cálculo exacto depende de cómo se definan la disponibilidad y el tiempo de inactividad.
¿Por qué es importante el uptime?
El uptime es importante porque los usuarios y las empresas dependen de que los sistemas estén disponibles cuando se necesitan. Un uptime deficiente puede causar pérdida de productividad, fallos de comunicación, frustración de los clientes, interrupción del servicio y pérdida de ingresos.
Un alto uptime respalda la fiabilidad, la continuidad y la confianza de los usuarios.