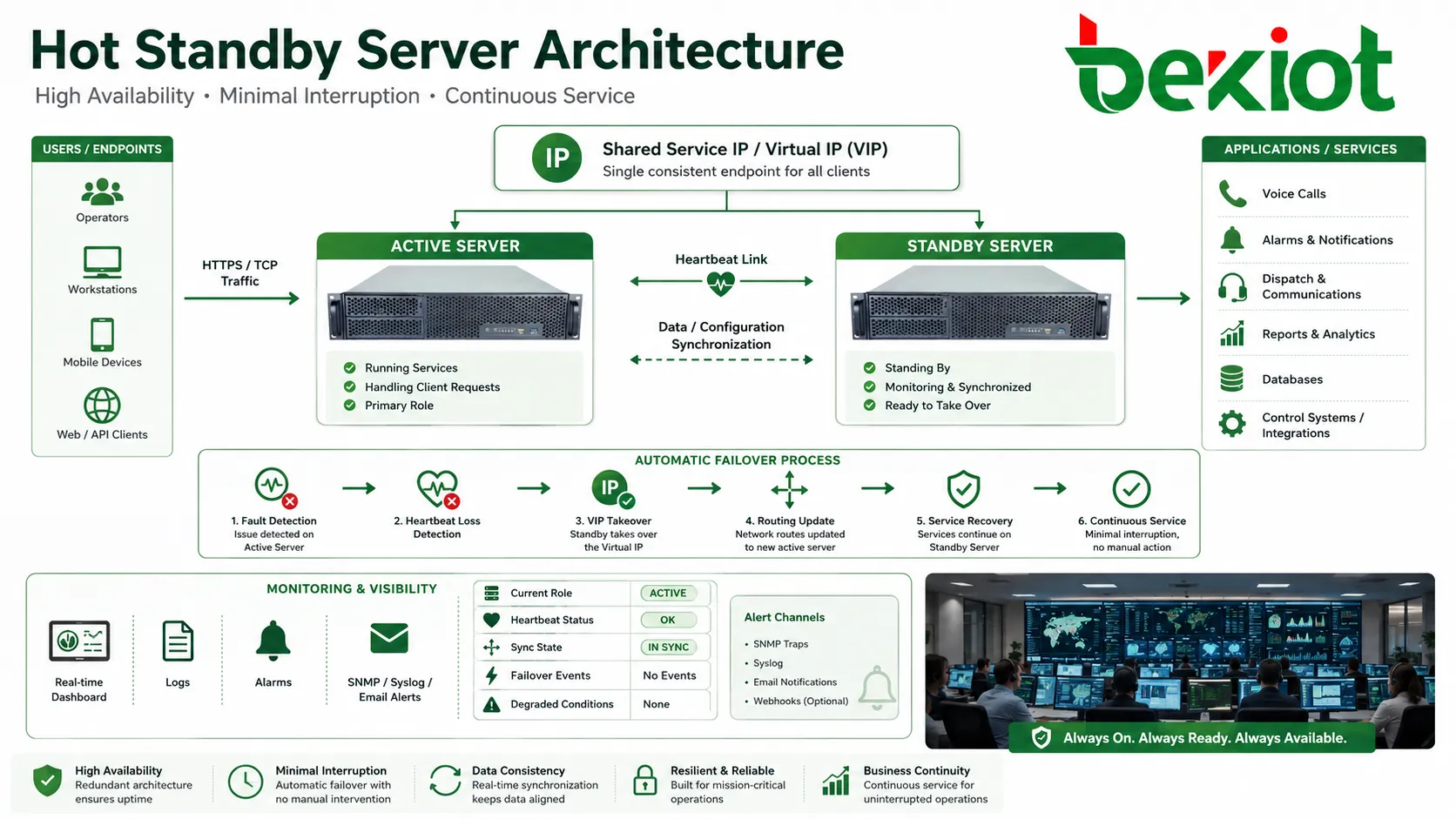
El hot standby es un diseño de alta disponibilidad en el que un equipo, servidor, controlador, gateway o plataforma de respaldo permanece encendido, sincronizado y preparado para asumir el servicio cuando falla la unidad activa. En lugar de esperar una reparación manual o un arranque en frío, el lado en espera ejecuta la conmutación automática y reduce la interrupción de los sistemas críticos.
La función se aplica en plataformas de comunicación, centros de datos, control industrial, seguridad, energía, transporte, nube, gateways de telecomunicaciones, sistemas de emergencia y aplicaciones empresariales. Su valor no consiste solo en tener una máquina adicional; el nodo de reserva debe estar conectado, monitorizado, sincronizado y probado para poder activarse cuando el nodo de producción deja de estar disponible.
Del equipo de respaldo al diseño de continuidad del servicio
Una copia de respaldo tradicional puede permanecer sin uso hasta que ocurra una avería. El hot standby es distinto porque el elemento de reserva ya forma parte de la arquitectura en vivo: escucha heartbeats, recibe cambios de configuración, sigue el estado del servicio y prepara una toma de control con mínima interrupción.
Para el usuario, el objetivo es directo: las llamadas continúan, las sesiones se recuperan, las alarmas siguen visibles, los sistemas de control permanecen disponibles y los operadores no reconstruyen el servicio manualmente. Para lograrlo, la arquitectura debe tratar sincronización de datos, toma de IP, estado de servicio, actualización de rutas, detección de fallos y orden de recuperación.
En entornos empresariales e industriales, la alta disponibilidad suele pesar más que el rendimiento máximo. Un sistema algo más lento pero siempre disponible puede resultar más valioso que una plataforma potente que queda sin protección ante una avería.
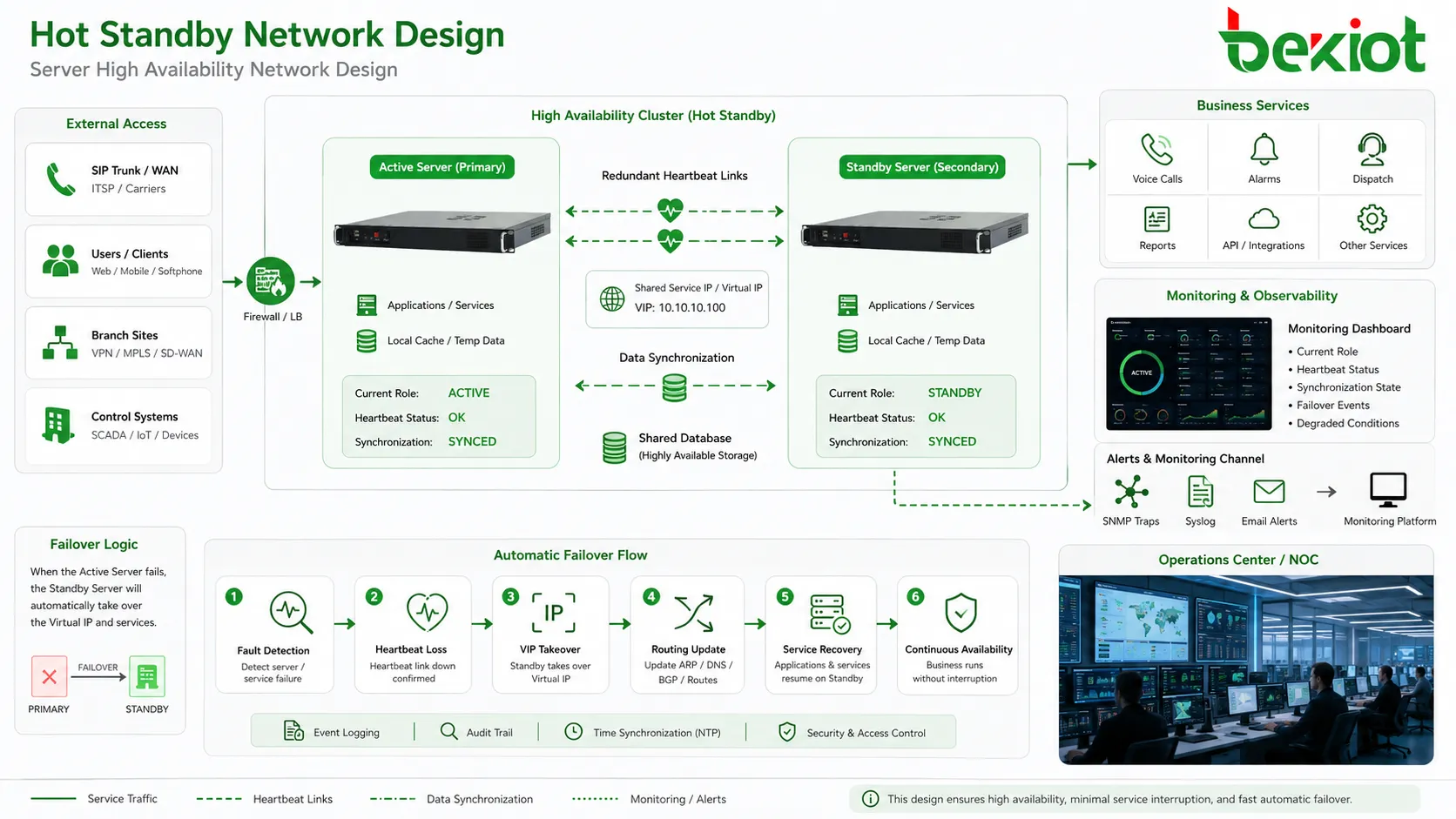
Cómo funciona el proceso de toma de control
Detección por latido
Los nodos activo y en espera intercambian señales de heartbeat para confirmar que ambos están vivos y que el primario sigue prestando servicio. Ese tráfico puede circular por cable dedicado, red de gestión, VLAN privada o ruta redundante.
Si el nodo en espera deja de recibir heartbeats válidos dentro de una ventana definida, puede sospechar que el activo falló y empezar la lógica de failover. Esa reacción debe diseñarse con cuidado, porque una demora temporal de red no debería provocar una conmutación falsa.
Sincronización de estado
Para una transición suave, el lado de reserva necesita información actual: configuración, datos de usuarios, tablas de ruta, sesiones, estados de llamada, alarmas, entradas de base de datos, licencias, registros de dispositivos y lógica de control.
Algunos sistemas sincronizan solo la configuración; otros sincronizan también el estado del servicio en tiempo real. Cuanto más profunda es la sincronización, más limpia puede ser la conmutación, aunque también aumentan la complejidad y la dependencia de la red.
Decisión de fallo
Tras detectar un posible fallo, el sistema debe decidir si el nodo activo está realmente fuera de servicio. Puede comprobar pérdida de heartbeat, procesos, disco, interfaces, respuesta de base de datos, CPU, alarmas de energía o entradas de monitorización externa.
Un buen diseño evita decidir por una única condición. Por ejemplo, perder un enlace de heartbeat no debería activar la toma de control si otra ruta de gestión todavía confirma que el nodo activo está sano.
Cambio de rol
Cuando se confirma el failover, el nodo en espera cambia de rol y se vuelve activo. Puede tomar una IP virtual, iniciar procesos, anunciar rutas, registrarse ante pares, activar troncales, asumir la base de datos maestra o empezar a procesar llamadas y alarmas.
El antiguo nodo activo puede aislarse, reiniciarse, repararse o volver después como nodo en espera. El reingreso debe controlarse para evitar conflicto de servicios.
Modelos de arquitectura clave
Par activo-en espera
El modelo más común usa un nodo activo y otro en espera. El activo atiende la producción y el de reserva espera y se sincroniza; si el activo falla, el de reserva toma el servicio.
Este modelo es fácil de entender y se usa en PBX, firewalls, routers, controladores, bases de datos, almacenamiento e industrias. Su límite es que el recurso de reserva puede quedar subutilizado durante la operación normal.
Doble activo con lógica de respaldo
En algunos entornos ambos nodos trabajan activamente y aun así ofrecen failover entre sí. Cada lado atiende parte de la carga normal y puede absorber más tráfico si el otro cae.
El diseño mejora el uso de recursos, pero exige balanceo, sincronización, manejo de sesiones y planificación de capacidad más cuidadosos. Si cada nodo trabaja casi al máximo, quizá no tenga reserva suficiente durante el fallo.
Redundancia basada en clúster
Los sistemas grandes pueden usar un clúster en lugar de un par simple. Varios nodos comparten servicios, se supervisan y redistribuyen cargas cuando un miembro falla.
El clúster aporta escalabilidad y resiliencia, pero complica el despliegue y el mantenimiento. Requiere coordinación fuerte, quórum, chequeos de salud y gestión de configuración consistente.
Protección geográficamente separada
En sistemas críticos, los recursos en espera pueden ubicarse en otro edificio, campus, centro de datos o región para protegerse frente a corte eléctrico, incendio, inundación, fallo de sala o interrupción del sitio.
La protección geográfica mejora la recuperación ante desastre, pero introduce latencia, consistencia de datos, enrutamiento y coordinación operativa. No todos los servicios pueden conmutar sin problemas a larga distancia.
| Modelo | Mejor ajuste | Principal preocupación de diseño |
|---|---|---|
| Activo-en espera | Pares simples de alta disponibilidad para servidores, gateways, PBX y controladores. | Uso del recurso de reserva y tiempo de conmutación. |
| Doble activo | Sistemas que necesitan reparto de carga y redundancia al mismo tiempo. | Reserva de capacidad, distribución de sesiones y control de retorno. |
| Clúster | Plataformas grandes con varios nodos de servicio y cargas escalables. | Quórum, sincronización, prevención de split-brain y complejidad operativa. |
| Protección remota | Recuperación ante desastre y resiliencia a nivel de sitio. | Latencia, consistencia de datos, enrutamiento y procedimiento de recuperación. |
Elementos de red que determinan la fiabilidad
Ruta de latido
El enlace de heartbeat debe ser fiable y preferentemente redundante. Si comparte una red inestable con el tráfico normal, el nodo de reserva puede interpretar mal el estado durante congestión o fallo de switch.
En despliegues críticos se usan dos rutas de heartbeat, enlaces físicos separados o caminos de switch distintos para evitar que un fallo de red provoque una toma incorrecta.
Dirección virtual de servicio
Muchos sistemas usan una IP virtual o dirección flotante. Usuarios y sistemas pares se conectan a esa dirección estable, no a la dirección física de un nodo; durante el failover la dirección pasa al lado de reserva.
El método simplifica los clientes, pero los equipos de red deben actualizar ARP, rutas, DNS o tablas de sesión con rapidez. Una actualización lenta puede hacer que el cambio parezca demorado aunque el nodo de reserva ya esté activo.
Datos compartidos o replicados
Algunos sistemas usan almacenamiento compartido y otros replican datos entre nodos. El almacenamiento compartido simplifica la consistencia, pero puede ser un punto único de fallo; la replicación aumenta independencia, aunque exige manejar retrasos, conflictos y escrituras incompletas.
La elección depende de si se necesita continuidad de configuración, consistencia transaccional, integridad de grabaciones, preservación de sesiones o solo reinicio sencillo del servicio.
Comportamiento de rutas y troncales
Los sistemas de comunicación pueden conectarse a troncales SIP, gateways de radio, PSTN, consolas de despacho, API externas, plataformas de monitorización y terminales remotos. Esos sistemas deben saber hacia dónde enviar tráfico después del failover.
Si el nodo de reserva se activa pero las troncales, rutas o registros de pares no se actualizan, el usuario seguirá percibiendo interrupción. Las pruebas deben incluir sistemas aguas arriba y abajo, no solo los dos nodos locales.
Capa de gestión y monitorización
La alta disponibilidad debe ser visible para los administradores. Paneles, logs, alarmas, traps SNMP, syslog, correos o plataformas de monitorización deben mostrar rol actual, heartbeat, sincronización, eventos de failover y estados degradados.
Sin monitorización, un sistema puede funcionar silenciosamente en el lado de reserva durante semanas. Si ocurre otro fallo, quizá ya no quede protección disponible.
Funciones técnicas importantes
Conmutación automática
El failover automático permite que el lado de reserva se vuelva activo sin intervención manual. Es esencial para comunicación en tiempo real, alarmas de seguridad, operaciones de control y servicios expuestos al cliente.
El umbral de failover debe ajustarse con precisión. Si es demasiado sensible habrá falsas conmutaciones; si es demasiado lento, los usuarios sufrirán paradas innecesarias.
Conmutación manual
La conmutación manual permite mover el servicio entre nodos durante mantenimiento, actualización, pruebas o reparación planificada. Ayuda al reemplazo de hardware, parches y validación de la preparación del standby.
Una conmutación controlada es más segura que esperar una avería no planificada, porque el equipo puede programarla, observar el resultado y revertir si hace falta.
Control de retorno
Tras reparar el nodo original, el sistema debe decidir si vuelve automáticamente o permanece en el nodo activo actual hasta una ventana planificada. El failback automático restaura el diseño, pero también puede causar otra interrupción.
Muchos sistemas críticos prefieren failback manual para que el operador verifique salud, sincronización y tráfico antes de mover de nuevo el servicio.
Prevención de split-brain
El split-brain aparece cuando ambos nodos creen estar activos al mismo tiempo. Puede causar servicios duplicados, conflictos de base de datos, errores de rutas de llamada, conflicto de IP o corrupción de datos.
Para prevenirlo se usan quórum, nodos testigo, fencing, reglas de prioridad, heartbeats redundantes y control estricto de rol. Es una parte central de cualquier diseño de alta disponibilidad.
Protección de integridad de datos
Durante el failover se deben proteger la configuración y los datos operativos, incluidas transacciones, registros de llamada, logs de alarma, estado de registro de dispositivos, grabaciones e historial de eventos.
La integridad de datos es crítica cuando el sistema participa en cumplimiento, facturación, registros de emergencia, bitácoras de despacho o auditorías.
Dónde se utiliza este diseño
Plataformas de comunicación empresarial
Servidores PBX, plataformas SIP, buzón de voz, grabación, contact center y comunicaciones unificadas pueden usar protección standby para mantener llamadas de negocio. Si falla el activo, el respaldo continúa gestionando registros, llamadas, rutas y lógica de servicio.
En proyectos de comunicación crítica, Becke Telcom aplica el enfoque de alta disponibilidad al diseño de soluciones, considerando redundancia de servidores, continuidad de gateways, disponibilidad de despacho y rutas de failover.
Control industrial y SCADA
Los sistemas industriales utilizan controladores en espera, SCADA redundante, gateways dobles y estaciones de operador de respaldo para producción, seguridad, energía, servicios públicos y monitorización de procesos.
El failover debe probarse con condiciones reales de proceso. Un sistema que cambia bien en laboratorio puede comportarse distinto al conectarse con dispositivos de campo, PLC, historiadores, alarmas y consolas.
Sistemas de seguridad y videovigilancia
Servidores VMS, control de acceso, servidores de alarma, nodos de almacenamiento y salas de control pueden necesitar standby para evitar puntos ciegos o retrasos de respuesta de seguridad.
En esos entornos, el diseño debe considerar video en vivo, continuidad de grabación, control de puertas, acuse de alarmas, logs de eventos y permisos de operadores.
Centros de datos y servicios cloud
Servidores, bases de datos, firewalls, balanceadores, matrices de almacenamiento, routers y aplicaciones usan alta disponibilidad en capas de hardware, virtualización, contenedor, base de datos o aplicación.
Cuantas más capas intervienen, más importante es definir cuál ejecuta el failover. Mecanismos independientes pueden entrar en conflicto si no se planifican juntos.

Seguridad pública y transporte
Centros de emergencia, ferrocarriles, túneles, aeropuertos, puertos y tráfico requieren alta disponibilidad. La falla de comunicación retrasa respuesta, reduce conciencia situacional o interrumpe coordinación.
La redundancia debe cubrir servidores, energía, switches, troncales, terminales, puestos de operador e interfaces externas.
Beneficios de despliegue más allá de reducir paradas
El beneficio más visible es continuidad del servicio. Si falla el primario, los usuarios siguen trabajando con menos interrupción en voz, alarmas, monitorización, datos y control.
También aporta flexibilidad de mantenimiento planificado. El administrador mueve el servicio al standby, mantiene el nodo original y restaura el rol tras verificarlo, reduciendo ventanas largas.
El standby aumenta la confianza en las actualizaciones. Si un cambio falla en un lado, la organización puede tener un camino controlado de recuperación si el rollback está bien diseñado.
Para la dirección, la alta disponibilidad convierte un fallo de dispositivo en un evento gestionable que se investiga y repara con menor impacto en el negocio.
Escenarios prácticos de fallo
Fallo de hardware
Puede fallar un servidor, fuente, disco, tarjeta, gateway o controlador. El standby debe detectar que el servicio activo ya no está sano y asumir según la política configurada.
El fallo de hardware es fácil de comprender, pero no siempre es la causa más frecuente de interrupción.
Caída del proceso de aplicación
La máquina puede seguir encendida mientras la aplicación dejó de responder. Un buen chequeo verifica el servicio, no solo que el servidor esté vivo.
Comprobar solo ping no basta; el sistema puede responder ping aunque el motor de llamadas, la base de datos, el proceso de alarmas o el servicio web hayan fallado.
Aislamiento de red
Un nodo puede quedar aislado de usuarios y aun creer que está sano. Esto es peligroso porque el sistema puede no saber qué lado debe estar activo.
Rutas de red redundantes y lógica de quórum ayudan a evitar decisiones incorrectas durante el aislamiento.
Corrupción de base de datos
Si se corrompen datos en el activo y se replican de inmediato al standby, la redundancia sola no resuelve el problema. Se necesitan backup y recuperación con versiones.
Alta disponibilidad no es lo mismo que backup: el nodo standby protege continuidad de servicio y el backup protege recuperación histórica.
Error del operador
Configuración errónea, borrado accidental, ruta incorrecta o actualización fallida pueden afectar a ambos nodos si se sincronizan automáticamente.
Control de cambios, aprobación, exportación de configuración y plan de rollback reducen el impacto de errores humanos.
La alta disponibilidad reduce paradas por fallo de componentes, pero no reemplaza backup, ciberseguridad, control de cambios, monitorización ni mantenimiento disciplinado.
Estrategia de prueba y aceptación
El failover debe probarse antes de la entrega. La prueba confirma detección de fallo, toma de servicio, actualización de red, reconexión externa, preservación de datos y alarmas correctas.
Las pruebas deben incluir switchover planificado, apagado del activo, caída de procesos, fallo de enlace, fallo de energía cuando sea seguro y recuperación tras reparación, con criterios de interrupción máxima.
Los registros de aceptación deben incluir tiempo de failover, consistencia de datos, disponibilidad de servicio, alarmas, evidencias de log, confirmación del operador y asuntos pendientes.
Guías de operación y mantenimiento
El estado standby debe supervisarse de forma continua. Un nodo encendido pero fuera de sincronía no está listo; se revisan heartbeat, retraso de réplica, recursos, servicio, licencias, almacenamiento y versiones.
Mantener ambos lados actualizados requiere cuidado. Diferencias de versión pueden romper el failover, pero las actualizaciones deben probarse para no dañar ambos nodos a la vez.
Hay que realizar simulacros periódicos de conmutación. Un sistema nunca probado en condiciones controladas puede no funcionar durante una falla real.
Después de cada failover se revisan logs e investigación de causa. Eventos repetidos pueden indicar red inestable, sobrecarga, degradación de hardware o umbrales de salud mal definidos.
FAQ
¿Hot standby es lo mismo que copia de seguridad?
No. El standby se usa para continuidad del servicio y el backup para recuperación de datos. Normalmente se necesitan ambos porque el failover no recupera versiones antiguas de datos dañados o eliminados.
¿Qué tan rápida debe ser la conmutación?
El tiempo aceptable depende de la aplicación. Voz, control, alarmas y seguridad pública suelen requerir recuperación más rápida que reportes o archivos ordinarios.
¿Un sistema en espera protege contra errores de software?
Solo a veces. Si el mismo bug existe en ambos nodos, el failover no lo resuelve; siguen siendo importantes control de versiones, pruebas, rollback y backup.
¿Qué causa una condición split-brain?
El split-brain suele deberse a pérdida de heartbeat, aislamiento de red, quórum débil o reglas incorrectas, cuando más de un nodo cree que debe estar activo.
¿Qué se debe revisar después de una conmutación?
Después del evento se revisan rol activo, salud del standby, sincronización, logs de servicio, impacto a usuarios, integridad de datos, troncos o interfaces externas, alarmas y causa raíz.